 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynFlow: Scaling Up LiDAR Scene Flow Estimation with Synthetic Data
Apr 10, 2026Reliable 3D dynamic perception requires models that can anticipate motion beyond predefined categories, yet progress is hindered by the scarcity of dense, high-quality motion annotations. While self-supervision on unlabeled real data offers a path forward, empirical evidence suggests that scaling unlabeled data fails to close the performance gap due to noisy proxy signals. In this paper, we propose a shift in paradigm: learning robust real-world motion priors entirely from scalable simulation. We introduce SynFlow, a data generation pipeline that generates large-scale synthetic dataset specifically designed for LiDAR scene flow. Unlike prior works that prioritize sensor-specific realism, SynFlow employs a motion-oriented strategy to synthesize diverse kinematic patterns across 4,000 sequences ($\sim$940k frames), termed SynFlow-4k. This represents a 34x scale-up in annotated volume over existing real-world benchmarks. Our experiments demonstrate that SynFlow-4k provides a highly domain-invariant motion prior. In a zero-shot regime, models trained exclusively on our synthetic data generalize across multiple real-world benchmarks, rivaling in-domain supervised baselines on nuScenes and outperforming state-of-the-art methods on TruckScenes by 31.8%. Furthermore, SynFlow-4k serves as a label-efficient foundation: fine-tuning with only 5% of real-world labels surpasses models trained from scratch on the full available budget. We open-source the pipeline and dataset to facilitate research in generalizable 3D motion estimation. More detail can be found at https://kin-zhang.github.io/SynFlow.
Listening with the Eyes: Benchmarking Egocentric Co-Speech Grounding across Space and Time
Mar 09, 2026In situated collaboration, speakers often use intentionally underspecified deictic commands (e.g., ``pass me \textit{that}''), whose referent becomes identifiable only by aligning speech with a brief co-speech pointing \emph{stroke}. However, many embodied benchmarks admit language-only shortcuts, allowing MLLMs to perform well without learning the \emph{audio--visual alignment} required by deictic interaction. To bridge this gap, we introduce \textbf{Egocentric Co-Speech Grounding (EcoG)}, where grounding is executable only if an agent jointly predicts \textit{What}, \textit{Where}, and \textit{When}. To operationalize this, we present \textbf{EcoG-Bench}, an evaluation-only bilingual (EN/ZH) diagnostic benchmark of \textbf{811} egocentric clips with dense spatial annotations and millisecond-level stroke supervision. It is organized under a \textbf{Progressive Cognitive Evaluation} protocol. Benchmarking state-of-the-art MLLMs reveals a severe executability gap: while human subjects achieve near-ceiling performance on EcoG-Bench (\textbf{96.9\%} strict Eco-Accuracy), the best native video-audio setting remains low (Gemini-3-Pro: \textbf{17.0\%}). Moreover, in a diagnostic ablation, replacing the native video--audio interface with timestamped frame samples and externally verified ASR (with word-level timing) substantially improves the same model (\textbf{17.0\%}$\to$\textbf{42.9\%}). Overall, EcoG-Bench provides a strict, executable testbed for event-level speech--gesture binding, and suggests that multimodal interfaces may bottleneck the observability of temporal alignment cues, independently of model reasoning.
TeFlow: Enabling Multi-frame Supervision for Self-Supervised Feed-forward Scene Flow Estimation
Feb 22, 2026Self-supervised feed-forward methods for scene flow estimation offer real-time efficiency, but their supervision from two-frame point correspondences is unreliable and often breaks down under occlusions. Multi-frame supervision has the potential to provide more stable guidance by incorporating motion cues from past frames, yet naive extensions of two-frame objectives are ineffective because point correspondences vary abruptly across frames, producing inconsistent signals. In the paper, we present TeFlow, enabling multi-frame supervision for feed-forward models by mining temporally consistent supervision. TeFlow introduces a temporal ensembling strategy that forms reliable supervisory signals by aggregating the most temporally consistent motion cues from a candidate pool built across multiple frames. Extensive evaluations demonstrate that TeFlow establishes a new state-of-the-art for self-supervised feed-forward methods, achieving performance gains of up to 33\% on the challenging Argoverse 2 and nuScenes datasets. Our method performs on par with leading optimization-based methods, yet speeds up 150 times. The code is open-sourced at https://github.com/KTH-RPL/OpenSceneFlow along with trained model weights.
ProAct: A Benchmark and Multimodal Framework for Structure-Aware Proactive Response
Feb 03, 2026While passive agents merely follow instructions, proactive agents align with higher-level objectives, such as assistance and safety by continuously monitoring the environment to determine when and how to act. However, developing proactive agents is hindered by the lack of specialized resources. To address this, we introduce ProAct-75, a benchmark designed to train and evaluate proactive agents across diverse domains, including assistance, maintenance, and safety monitoring. Spanning 75 tasks, our dataset features 91,581 step-level annotations enriched with explicit task graphs. These graphs encode step dependencies and parallel execution possibilities, providing the structural grounding necessary for complex decision-making. Building on this benchmark, we propose ProAct-Helper, a reference baseline powered by a Multimodal Large Language Model (MLLM) that grounds decision-making in state detection, and leveraging task graphs to enable entropy-driven heuristic search for action selection, allowing agents to execute parallel threads independently rather than mirroring the human's next step. Extensive experiments demonstrate that ProAct-Helper outperforms strong closed-source models, improving trigger detection mF1 by 6.21%, saving 0.25 more steps in online one-step decision, and increasing the rate of parallel actions by 15.58%.
DeltaFlow: An Efficient Multi-frame Scene Flow Estimation Method
Aug 23, 2025



Previous dominant methods for scene flow estimation focus mainly on input from two consecutive frames, neglecting valuable information in the temporal domain. While recent trends shift towards multi-frame reasoning, they suffer from rapidly escalating computational costs as the number of frames grows. To leverage temporal information more efficiently, we propose DeltaFlow ($\Delta$Flow), a lightweight 3D framework that captures motion cues via a $\Delta$ scheme, extracting temporal features with minimal computational cost, regardless of the number of frames. Additionally, scene flow estimation faces challenges such as imbalanced object class distributions and motion inconsistency. To tackle these issues, we introduce a Category-Balanced Loss to enhance learning across underrepresented classes and an Instance Consistency Loss to enforce coherent object motion, improving flow accuracy. Extensive evaluations on the Argoverse 2 and Waymo datasets show that $\Delta$Flow achieves state-of-the-art performance with up to 22% lower error and $2\times$ faster inference compared to the next-best multi-frame supervised method, while also demonstrating a strong cross-domain generalization ability. The code is open-sourced at https://github.com/Kin-Zhang/DeltaFlow along with trained model weights.
The Structural Sources of Verb Meaning Revisited: Large Language Models Display Syntactic Bootstrapping
Aug 17, 2025Syntactic bootstrapping (Gleitman, 1990) is the hypothesis that children use the syntactic environments in which a verb occurs to learn its meaning. In this paper, we examine whether large language models exhibit a similar behavior. We do this by training RoBERTa and GPT-2 on perturbed datasets where syntactic information is ablated. Our results show that models' verb representation degrades more when syntactic cues are removed than when co-occurrence information is removed. Furthermore, the representation of mental verbs, for which syntactic bootstrapping has been shown to be particularly crucial in human verb learning, is more negatively impacted in such training regimes than physical verbs. In contrast, models' representation of nouns is affected more when co-occurrences are distorted than when syntax is distorted. In addition to reinforcing the important role of syntactic bootstrapping in verb learning, our results demonstrated the viability of testing developmental hypotheses on a larger scale through manipulating the learning environments of large language models.
Domain Randomization for Object Detection in Manufacturing Applications using Synthetic Data: A Comprehensive Study
Jun 09, 2025This paper addresses key aspects of domain randomization in generating synthetic data for manufacturing object detection applications. To this end, we present a comprehensive data generation pipeline that reflects different factors: object characteristics, background, illumination, camera settings, and post-processing. We also introduce the Synthetic Industrial Parts Object Detection dataset (SIP15-OD) consisting of 15 objects from three industrial use cases under varying environments as a test bed for the study, while also employing an industrial dataset publicly available for robotic applications. In our experiments, we present more abundant results and insights into the feasibility as well as challenges of sim-to-real object detection. In particular, we identified material properties, rendering methods, post-processing, and distractors as important factors. Our method, leveraging these, achieves top performance on the public dataset with Yolov8 models trained exclusively on synthetic data; mAP@50 scores of 96.4% for the robotics dataset, and 94.1%, 99.5%, and 95.3% across three of the SIP15-OD use cases, respectively. The results showcase the effectiveness of the proposed domain randomization, potentially covering the distribution close to real data for the applications.
Afford-X: Generalizable and Slim Affordance Reasoning for Task-oriented Manipulation
Mar 05, 2025Object affordance reasoning, the ability to infer object functionalities based on physical properties, is fundamental for task-oriented planning and activities in both humans and Artificial Intelligence (AI). This capability, required for planning and executing daily activities in a task-oriented manner, relies on commonsense knowledge of object physics and functionalities, extending beyond simple object recognition. Current computational models for affordance reasoning from perception lack generalizability, limiting their applicability in novel scenarios. Meanwhile, comprehensive Large Language Models (LLMs) with emerging reasoning capabilities are challenging to deploy on local devices for task-oriented manipulations. Here, we introduce LVIS-Aff, a large-scale dataset comprising 1,496 tasks and 119k images, designed to enhance the generalizability of affordance reasoning from perception. Utilizing this dataset, we develop Afford-X, an end-to-end trainable affordance reasoning model that incorporates Verb Attention and Bi-Fusion modules to improve multi-modal understanding. This model achieves up to a 12.1% performance improvement over the best-reported results from non-LLM methods, while also demonstrating a 1.2% enhancement compared to our previous conference paper. Additionally, it maintains a compact 187M parameter size and infers nearly 50 times faster than the GPT-4V API. Our work demonstrates the potential for efficient, generalizable affordance reasoning models that can be deployed on local devices for task-oriented manipulations. We showcase Afford-X's effectiveness in enabling task-oriented manipulations for robots across various tasks and environments, underscoring its efficiency and broad implications for advancing robotics and AI systems in real-world applications.
Meaning Beyond Truth Conditions: Evaluating Discourse Level Understanding via Anaphora Accessibility
Feb 19, 2025We present a hierarchy of natural language understanding abilities and argue for the importance of moving beyond assessments of understanding at the lexical and sentence levels to the discourse level. We propose the task of anaphora accessibility as a diagnostic for assessing discourse understanding, and to this end, present an evaluation dataset inspired by theoretical research in dynamic semantics. We evaluate human and LLM performance on our dataset and find that LLMs and humans align on some tasks and diverge on others. Such divergence can be explained by LLMs' reliance on specific lexical items during language comprehension, in contrast to human sensitivity to structural abstractions.
ImpScore: A Learnable Metric For Quantifying The Implicitness Level of Language
Nov 07, 2024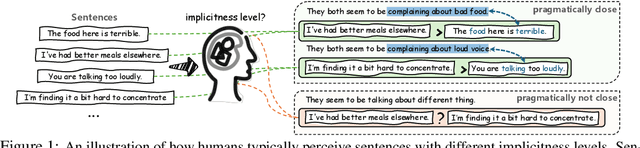
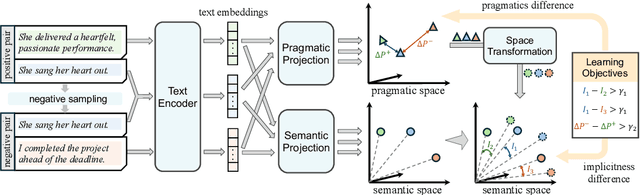

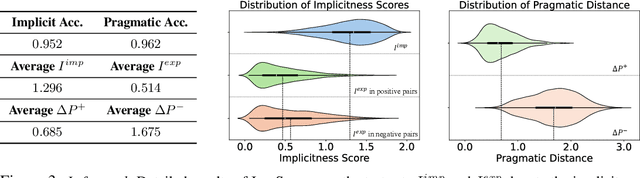
Handling implicit language is essential for natural language processing systems to achieve precise text understanding and facilitate natural interactions with users. Despite its importance, the absence of a robust metric for accurately measuring the implicitness of language significantly constrains the depth of analysis possible in evaluating models' comprehension capabilities. This paper addresses this gap by developing a scalar metric that quantifies the implicitness level of language without relying on external references. Drawing on principles from traditional linguistics, we define ''implicitness'' as the divergence between semantic meaning and pragmatic interpretation. To operationalize this definition, we introduce ImpScore, a novel, reference-free metric formulated through an interpretable regression model. This model is trained using pairwise contrastive learning on a specially curated dataset comprising $112,580$ (implicit sentence, explicit sentence) pairs. We validate ImpScore through a user study that compares its assessments with human evaluations on out-of-distribution data, demonstrating its accuracy and strong correlation with human judgments. Additionally, we apply ImpScore to hate speech detection datasets, illustrating its utility and highlighting significant limitations in current large language models' ability to understand highly implicit content. The metric model and its training data are available at https://github.com/audreycs/ImpScore.