 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVOLMO: Versatile and Open Large Models for Ophthalmology
Mar 25, 2026Vision impairment affects millions globally, and early detection is critical to preventing irreversible vision loss. Ophthalmology workflows require clinicians to integrate medical images, structured clinical data, and free-text notes to determine disease severity and management, which is time-consuming and burdensome. Recent multimodal large language models (MLLMs) show promise, but existing general and medical MLLMs perform poorly in ophthalmology, and few ophthalmology-specific MLLMs are openly available. We present VOLMO (Versatile and Open Large Models for Ophthalmology), a model-agnostic, data-open framework for developing ophthalmology-specific MLLMs. VOLMO includes three stages: ophthalmology knowledge pretraining on 86,965 image-text pairs from 26,569 articles across 82 journals; domain task fine-tuning on 26,929 annotated instances spanning 12 eye conditions for disease screening and severity classification; and multi-step clinical reasoning on 913 patient case reports for assessment, planning, and follow-up care. Using this framework, we trained a compact 2B-parameter MLLM and compared it with strong baselines, including InternVL-2B, LLaVA-Med-7B, MedGemma-4B, MedGemma-27B, and RETFound. We evaluated these models on image description generation, disease screening and staging classification, and assessment-and-management generation, with additional manual review by two healthcare professionals and external validation on three independent cohorts for age-related macular degeneration and diabetic retinopathy. Across settings, VOLMO-2B consistently outperformed baselines, achieving stronger image description performance, an average F1 of 87.4% across 12 eye conditions, and higher scores in external validation.
Enhancing Large Language Models with Domain-specific Retrieval Augment Generation: A Case Study on Long-form Consumer Health Question Answering in Ophthalmology
Sep 20, 2024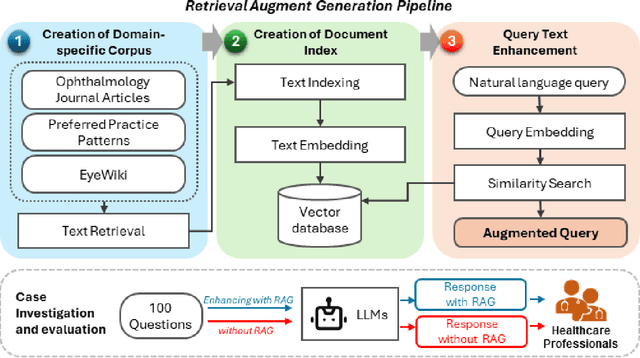

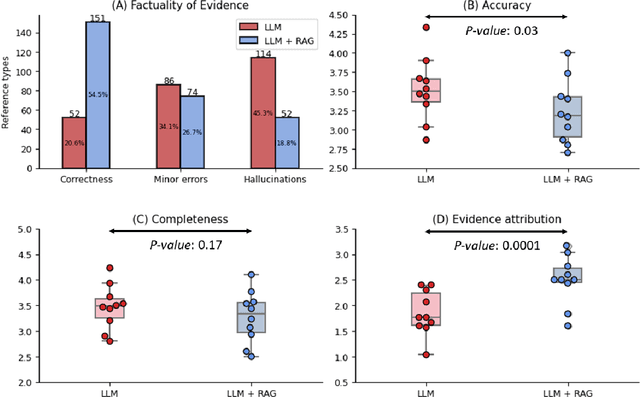

Despite the potential of Large Language Models (LLMs) in medicine, they may generate responses lacking supporting evidence or based on hallucinated evidence. While Retrieval Augment Generation (RAG) is popular to address this issue, few studies implemented and evaluated RAG in downstream domain-specific applications. We developed a RAG pipeline with 70,000 ophthalmology-specific documents that retrieve relevant documents to augment LLMs during inference time. In a case study on long-form consumer health questions, we systematically evaluated the responses including over 500 references of LLMs with and without RAG on 100 questions with 10 healthcare professionals. The evaluation focuses on factuality of evidence, selection and ranking of evidence, attribution of evidence, and answer accuracy and completeness. LLMs without RAG provided 252 references in total. Of which, 45.3% hallucinated, 34.1% consisted of minor errors, and 20.6% were correct. In contrast, LLMs with RAG significantly improved accuracy (54.5% being correct) and reduced error rates (18.8% with minor hallucinations and 26.7% with errors). 62.5% of the top 10 documents retrieved by RAG were selected as the top references in the LLM response, with an average ranking of 4.9. The use of RAG also improved evidence attribution (increasing from 1.85 to 2.49 on a 5-point scale, P<0.001), albeit with slight decreases in accuracy (from 3.52 to 3.23, P=0.03) and completeness (from 3.47 to 3.27, P=0.17). The results demonstrate that LLMs frequently exhibited hallucinated and erroneous evidence in the responses, raising concerns for downstream applications in the medical domain. RAG substantially reduced the proportion of such evidence but encountered challenges.
MedGen: A Python Natural Language Processing Toolkit for Medical Text Processing
Nov 28, 2023
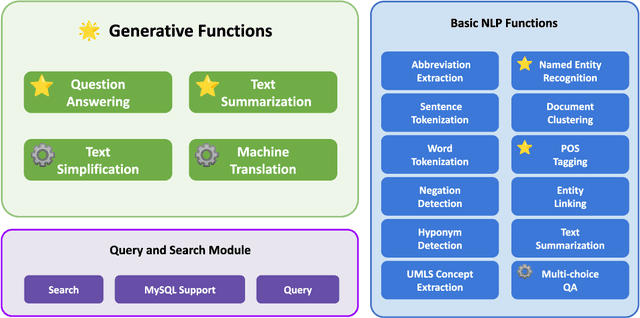
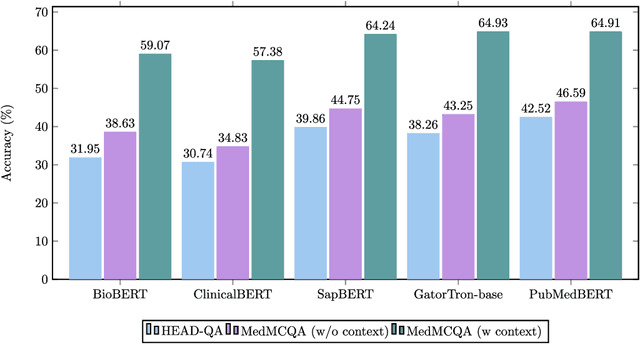
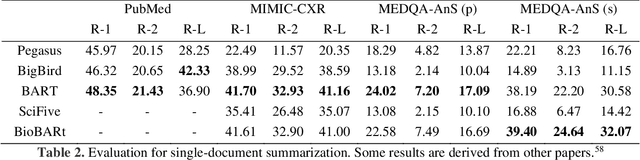
This study introduces MedGen, a comprehensive natural language processing (NLP) toolkit designed for medical text processing. MedGen is tailored for biomedical researchers and healthcare professionals with an easy-to-use, all-in-one solution that requires minimal programming expertise. It includes (1) Generative Functions: For the first time, MedGen includes four advanced generative functions: question answering, text summarization, text simplification, and machine translation; (2) Basic NLP Functions: MedGen integrates 12 essential NLP functions such as word tokenization and sentence segmentation; and (3) Query and Search Capabilities: MedGen provides user-friendly query and search functions on text corpora. We fine-tuned 32 domain-specific language models, evaluated them thoroughly on 24 established benchmarks and conducted manual reviews with clinicians. Additionally, we expanded our toolkit by introducing query and search functions, while also standardizing and integrating functions from third-party libraries. The toolkit, its models, and associated data are publicly available via https://github.com/Yale-LILY/MedGen.
Multi-modal, multi-task, multi-attention deep learning detection of reticular pseudodrusen: towards automated and accessible classification of age-related macular degeneration
Nov 11, 2020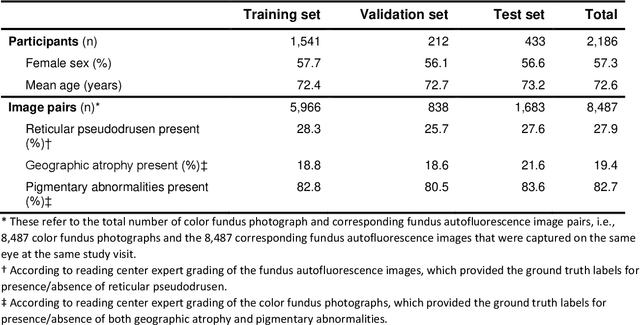
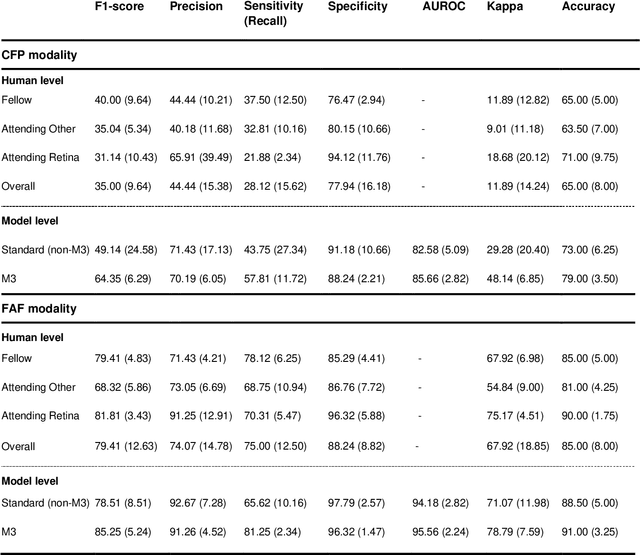
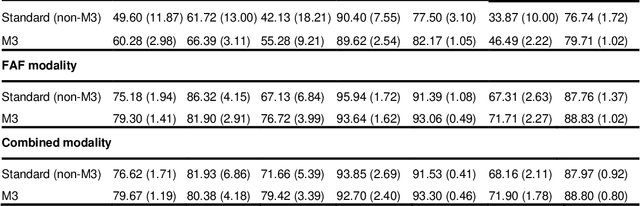
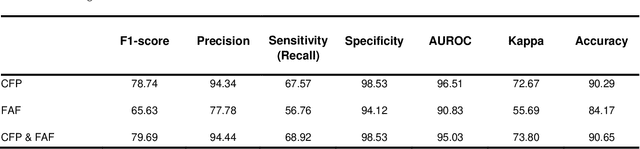
Objective Reticular pseudodrusen (RPD), a key feature of age-related macular degeneration (AMD), are poorly detected by human experts on standard color fundus photography (CFP) and typically require advanced imaging modalities such as fundus autofluorescence (FAF). The objective was to develop and evaluate the performance of a novel 'M3' deep learning framework on RPD detection. Materials and Methods A deep learning framework M3 was developed to detect RPD presence accurately using CFP alone, FAF alone, or both, employing >8000 CFP-FAF image pairs obtained prospectively (Age-Related Eye Disease Study 2). The M3 framework includes multi-modal (detection from single or multiple image modalities), multi-task (training different tasks simultaneously to improve generalizability), and multi-attention (improving ensembled feature representation) operation. Performance on RPD detection was compared with state-of-the-art deep learning models and 13 ophthalmologists; performance on detection of two other AMD features (geographic atrophy and pigmentary abnormalities) was also evaluated. Results For RPD detection, M3 achieved area under receiver operating characteristic (AUROC) 0.832, 0.931, and 0.933 for CFP alone, FAF alone, and both, respectively. M3 performance on CFP was very substantially superior to human retinal specialists (median F1-score 0.644 versus 0.350). External validation (on Rotterdam Study, Netherlands) demonstrated high accuracy on CFP alone (AUROC 0.965). The M3 framework also accurately detected geographic atrophy and pigmentary abnormalities (AUROC 0.909 and 0.912, respectively), demonstrating its generalizability. Conclusion This study demonstrates the successful development, robust evaluation, and external validation of a novel deep learning framework that enables accessible, accurate, and automated AMD diagnosis and prognosis.