Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Stable Feature Rankings with SHAP and LIME
Paper and Code
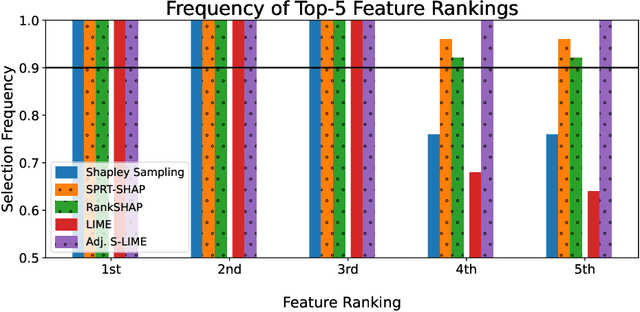
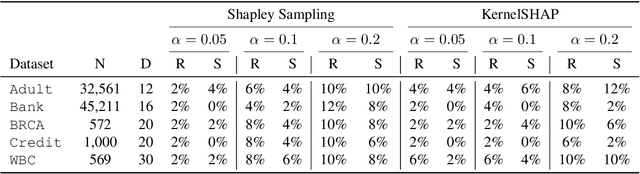
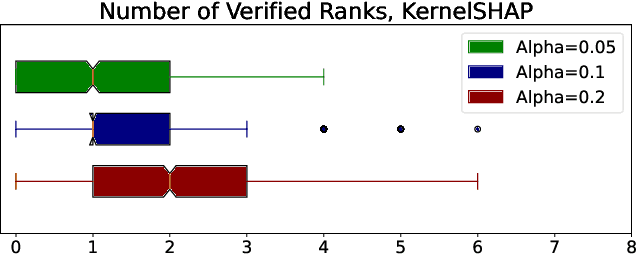
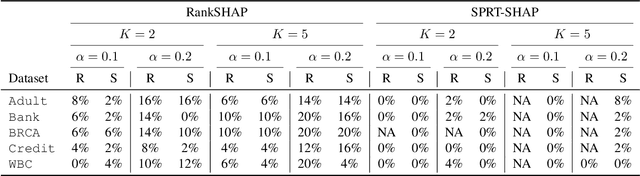
Feature attributions are ubiquitous tools for understanding the predictions of machine learning models. However, popular methods for scoring input variables such as SHAP and LIME suffer from high instability due to random sampling. Leveraging ideas from multiple hypothesis testing, we devise attribution methods that correctly rank the most important features with high probability. Our algorithm RankSHAP guarantees that the $K$ highest Shapley values have the proper ordering with probability exceeding $1-\alpha$. Empirical results demonstrate its validity and impressive computational efficiency. We also build on previous work to yield similar results for LIME, ensuring the most important features are selected in the right order.
View paper on