 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Natural Language Processing for Unstructured Data in Electronic Health Records: a Review
Jul 07, 2021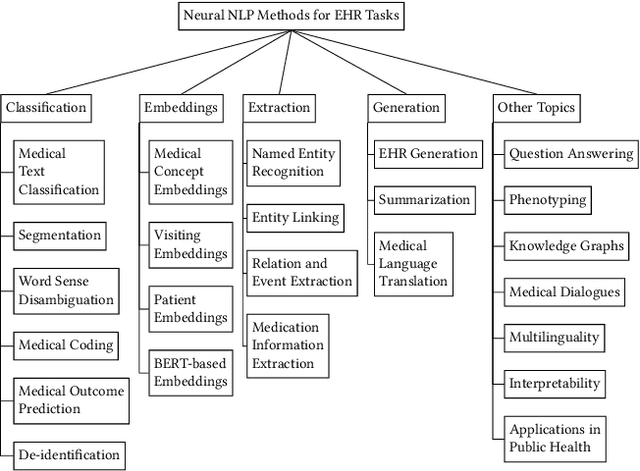

Electronic health records (EHRs), digital collections of patient healthcare events and observations, are ubiquitous in medicine and critical to healthcare delivery, operations, and research. Despite this central role, EHRs are notoriously difficult to process automatically. Well over half of the information stored within EHRs is in the form of unstructured text (e.g. provider notes, operation reports) and remains largely untapped for secondary use. Recently, however, newer neural network and deep learning approaches to Natural Language Processing (NLP) have made considerable advances, outperforming traditional statistical and rule-based systems on a variety of tasks. In this survey paper, we summarize current neural NLP methods for EHR applications. We focus on a broad scope of tasks, namely, classification and prediction, word embeddings, extraction, generation, and other topics such as question answering, phenotyping, knowledge graphs, medical dialogue, multilinguality, interpretability, etc.
DART: Open-Domain Structured Data Record to Text Generation
Jul 06, 2020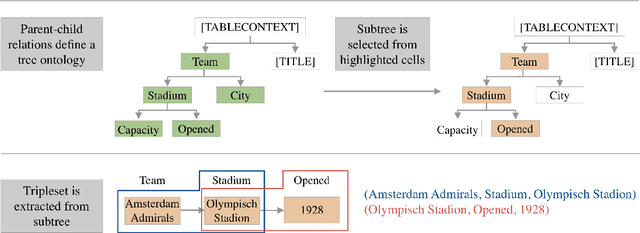
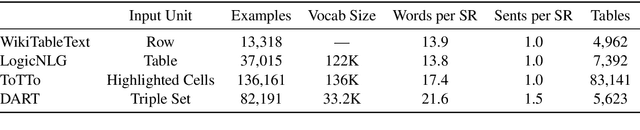
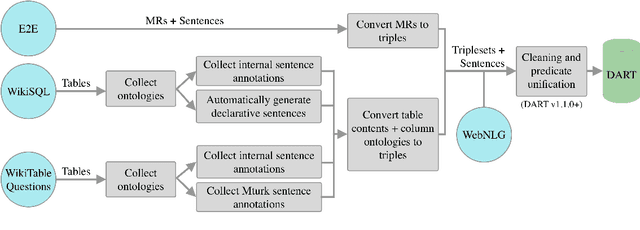
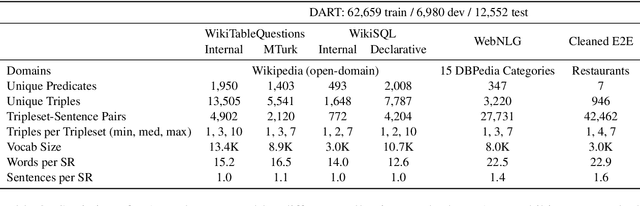
We introduce DART, a large dataset for open-domain structured data record to text generation. We consider the structured data record input as a set of RDF entity-relation triples, a format widely used for knowledge representation and semantics description. DART consists of 82,191 examples across different domains with each input being a semantic RDF triple set derived from data records in tables and the tree ontology of the schema, annotated with sentence descriptions that cover all facts in the triple set. This hierarchical, structured format with its open-domain nature differentiates DART from other existing table-to-text corpora. We conduct an analysis of DART on several state-of-the-art text generation models, showing that it introduces new and interesting challenges compared to existing datasets. Furthermore, we demonstrate that finetuning pretrained language models on DART facilitates out-of-domain generalization on the WebNLG 2017 dataset. DART is available at https://github.com/Yale-LILY/dart.