 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Image Counterfactuals and Feature Attributions with Latent-Space Adversarial Attacks
Paper and Code


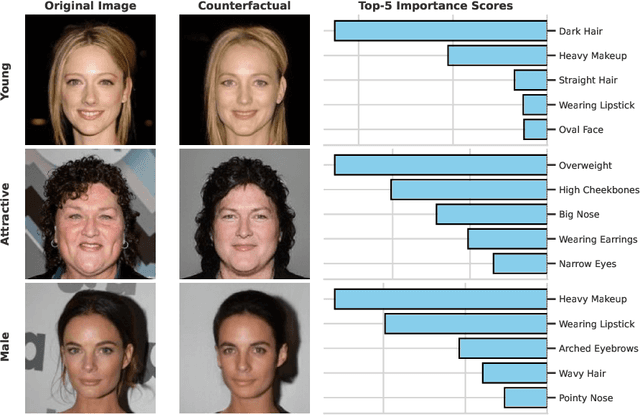
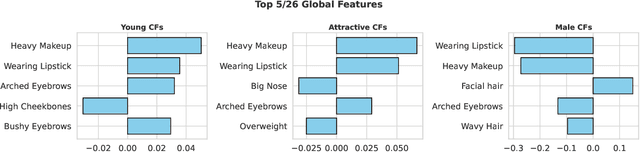
Counterfactuals are a popular framework for interpreting machine learning predictions. These what if explanations are notoriously challenging to create for computer vision models: standard gradient-based methods are prone to produce adversarial examples, in which imperceptible modifications to image pixels provoke large changes in predictions. We introduce a new, easy-to-implement framework for counterfactual images that can flexibly adapt to contemporary advances in generative modeling. Our method, Counterfactual Attacks, resembles an adversarial attack on the representation of the image along a low-dimensional manifold. In addition, given an auxiliary dataset of image descriptors, we show how to accompany counterfactuals with feature attribution that quantify the changes between the original and counterfactual images. These importance scores can be aggregated into global counterfactual explanations that highlight the overall features driving model predictions. While this unification is possible for any counterfactual method, it has particular computational efficiency for ours. We demonstrate the efficacy of our approach with the MNIST and CelebA datasets.