 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRADE: Object Tracking with 3D Trajectory and Ground Depth Estimates for UAVs
Oct 07, 2022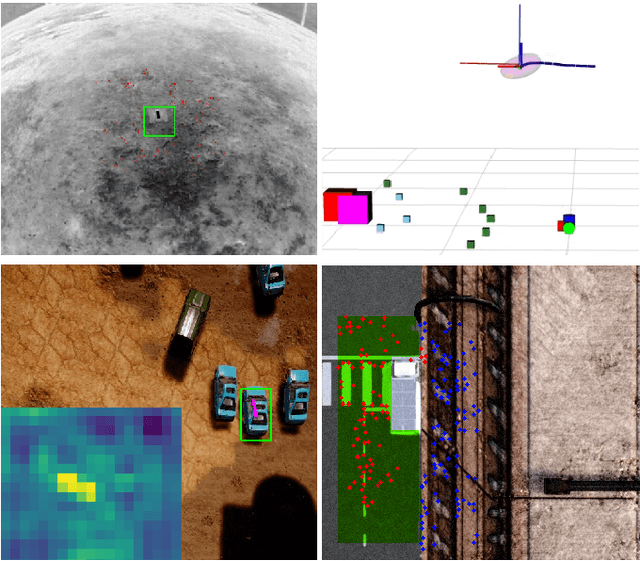


We propose TRADE for robust tracking and 3D localization of a moving target in cluttered environments, from UAVs equipped with a single camera. Ultimately TRADE enables 3d-aware target following. Tracking-by-detection approaches are vulnerable to target switching, especially between similar objects. Thus, TRADE predicts and incorporates the target 3D trajectory to select the right target from the tracker's response map. Unlike static environments, depth estimation of a moving target from a single camera is a ill-posed problem. Therefore we propose a novel 3D localization method for ground targets on complex terrain. It reasons about scene geometry by combining ground plane segmentation, depth-from-motion and single-image depth estimation. The benefits of using TRADE are demonstrated as tracking robustness and depth accuracy on several dynamic scenes simulated in this work. Additionally, we demonstrate autonomous target following using a thermal camera by running TRADE on a quadcopter's board computer.
Optimizing Terrain Mapping and Landing Site Detection for Autonomous UAVs
May 07, 2022



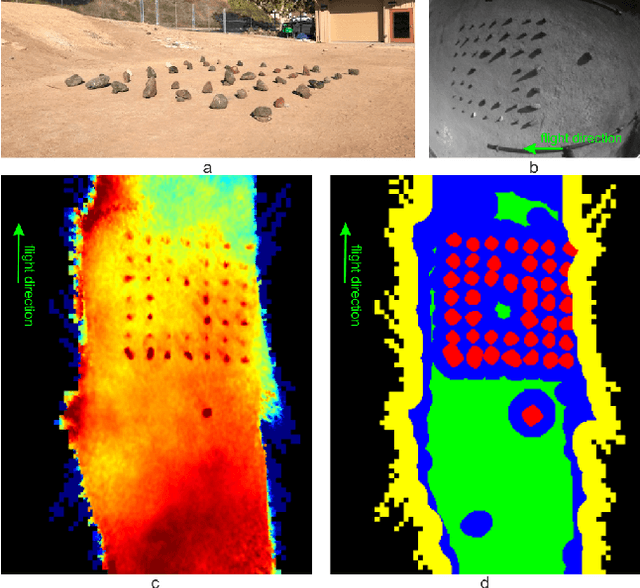
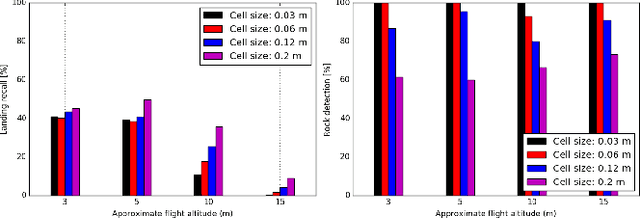
The next generation of Mars rotorcrafts requires on-board autonomous hazard avoidance landing. To this end, this work proposes a system that performs continuous multi-resolution height map reconstruction and safe landing spot detection. Structure-from-Motion measurements are aggregated in a pyramid structure using a novel Optimal Mixture of Gaussians formulation that provides a comprehensive uncertainty model. Our multiresolution pyramid is built more efficiently and accurately than past work by decoupling pyramid filling from the measurement updates of different resolutions. To detect the safest landing location, after an optimized hazard segmentation, we use a mean shift algorithm on multiple distance transform peaks to account for terrain roughness and uncertainty. The benefits of our contributions are evaluated on real and synthetic flight data.
Multi-Resolution Elevation Mapping and Safe Landing Site Detection with Applications to Planetary Rotorcraft
Nov 11, 2021

In this paper, we propose a resource-efficient approach to provide an autonomous UAV with an on-board perception method to detect safe, hazard-free landing sites during flights over complex 3D terrain. We aggregate 3D measurements acquired from a sequence of monocular images by a Structure-from-Motion approach into a local, robot-centric, multi-resolution elevation map of the overflown terrain, which fuses depth measurements according to their lateral surface resolution (pixel-footprint) in a probabilistic framework based on the concept of dynamic Level of Detail. Map aggregation only requires depth maps and the associated poses, which are obtained from an onboard Visual Odometry algorithm. An efficient landing site detection method then exploits the features of the underlying multi-resolution map to detect safe landing sites based on slope, roughness, and quality of the reconstructed terrain surface. The evaluation of the performance of the mapping and landing site detection modules are analyzed independently and jointly in simulated and real-world experiments in order to establish the efficacy of the proposed approach.
Fast Cylinder and Plane Extraction from Depth Cameras for Visual Odometry
Jul 05, 2018
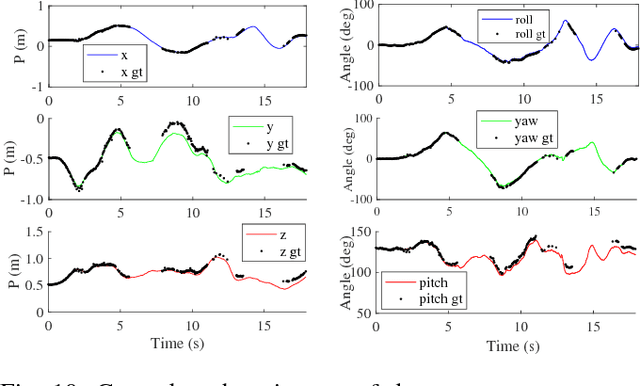
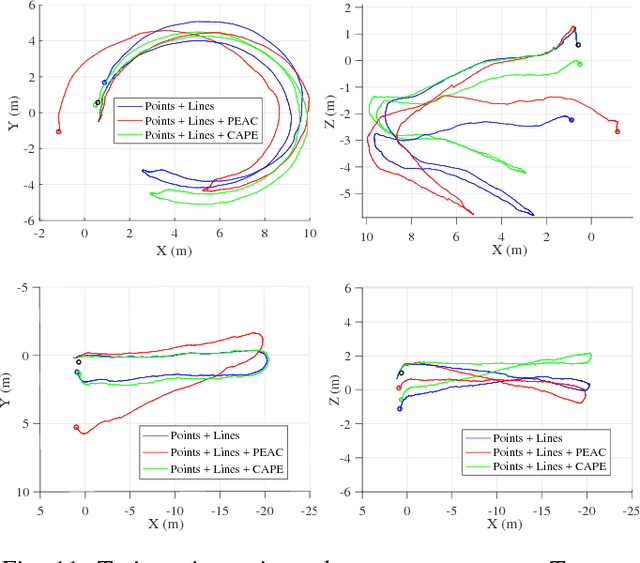

This paper presents CAPE, a method to extract planes and cylinder segments from organized point clouds, which processes 640x480 depth images on a single CPU core at an average of 300 Hz, by operating on a grid of planar cells. While, compared to state-of-the-art plane extraction, the latency of CAPE is more consistent and 4-10 times faster, depending on the scene, we also demonstrate empirically that applying CAPE to visual odometry can improve trajectory estimation on scenes made of cylindrical surfaces (e.g. tunnels), whereas using a plane extraction approach that is not curve-aware deteriorates performance on these scenes. To use these geometric primitives in visual odometry, we propose extending a probabilistic RGB-D odometry framework based on points, lines and planes to cylinder primitives. Following this framework, CAPE runs on fused depth maps and the parameters of cylinders are modelled probabilistically to account for uncertainty and weight accordingly the pose optimization residuals.
SPLODE: Semi-Probabilistic Point and Line Odometry with Depth Estimation from RGB-D Camera Motion
Aug 09, 2017
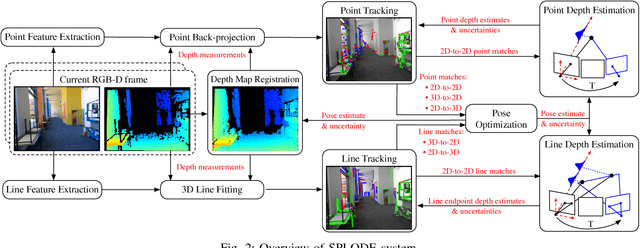
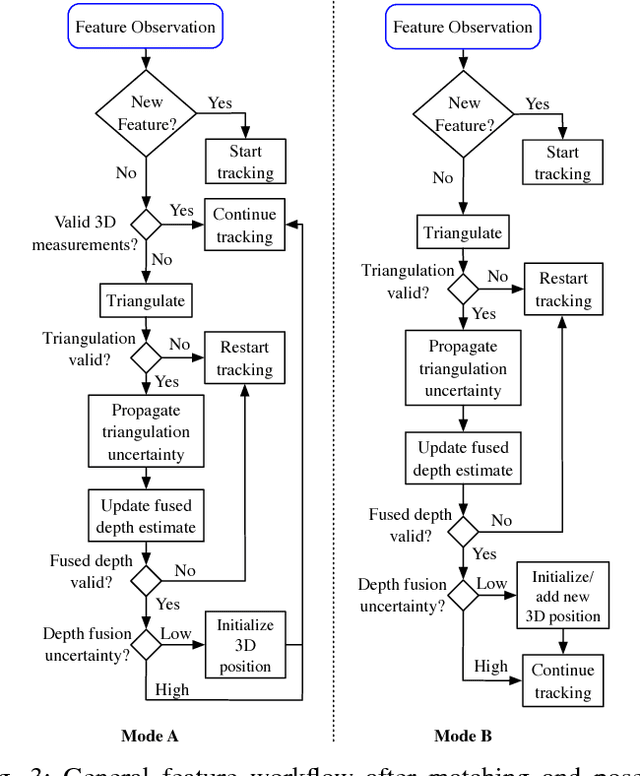
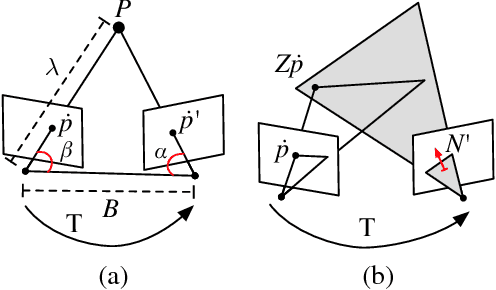
Active depth cameras suffer from several limitations, which cause incomplete and noisy depth maps, and may consequently affect the performance of RGB-D Odometry. To address this issue, this paper presents a visual odometry method based on point and line features that leverages both measurements from a depth sensor and depth estimates from camera motion. Depth estimates are generated continuously by a probabilistic depth estimation framework for both types of features to compensate for the lack of depth measurements and inaccurate feature depth associations. The framework models explicitly the uncertainty of triangulating depth from both point and line observations to validate and obtain precise estimates. Furthermore, depth measurements are exploited by propagating them through a depth map registration module and using a frame-to-frame motion estimation method that considers 3D-to-2D and 2D-to-3D reprojection errors, independently. Results on RGB-D sequences captured on large indoor and outdoor scenes, where depth sensor limitations are critical, show that the combination of depth measurements and estimates through our approach is able to overcome the absence and inaccuracy of depth measurements.
Probabilistic Combination of Noisy Points and Planes for RGB-D Odometry
May 18, 2017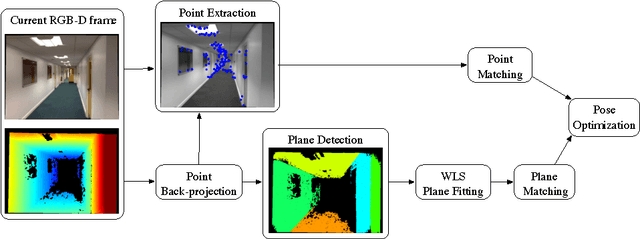
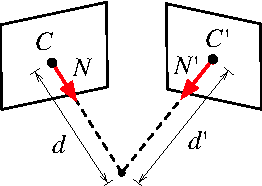

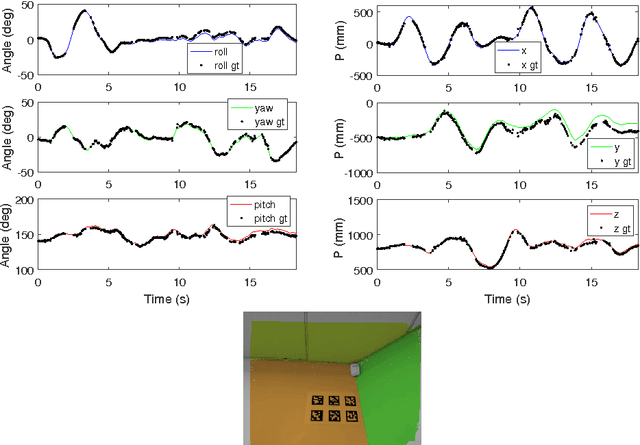
This work proposes a visual odometry method that combines points and plane primitives, extracted from a noisy depth camera. Depth measurement uncertainty is modelled and propagated through the extraction of geometric primitives to the frame-to-frame motion estimation, where pose is optimized by weighting the residuals of 3D point and planes matches, according to their uncertainties. Results on an RGB-D dataset show that the combination of points and planes, through the proposed method, is able to perform well in poorly textured environments, where point-based odometry is bound to fail.