 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirchow: A Million-Slide Digital Pathology Foundation Model
Sep 21, 2023Computational pathology uses artificial intelligence to enable precision medicine and decision support systems through the analysis of whole slide images. It has the potential to revolutionize the diagnosis and treatment of cancer. However, a major challenge to this objective is that for many specific computational pathology tasks the amount of data is inadequate for development. To address this challenge, we created Virchow, a 632 million parameter deep neural network foundation model for computational pathology. Using self-supervised learning, Virchow is trained on 1.5 million hematoxylin and eosin stained whole slide images from diverse tissue groups, which is orders of magnitude more data than previous works. When evaluated on downstream tasks including tile-level pan-cancer detection and subtyping and slide-level biomarker prediction, Virchow outperforms state-of-the-art systems both on internal datasets drawn from the same population as the pretraining data as well as external public datasets. Virchow achieves 93% balanced accuracy for pancancer tile classification, and AUCs of 0.983 for colon microsatellite instability status prediction and 0.967 for breast CDH1 status prediction. The gains in performance highlight the importance of pretraining on massive pathology image datasets, suggesting pretraining on even larger datasets could continue improving performance for many high-impact applications where limited amounts of training data are available, such as drug outcome prediction.
Privacy-Preserving Human Activity Recognition from Extreme Low Resolution
Dec 26, 2016

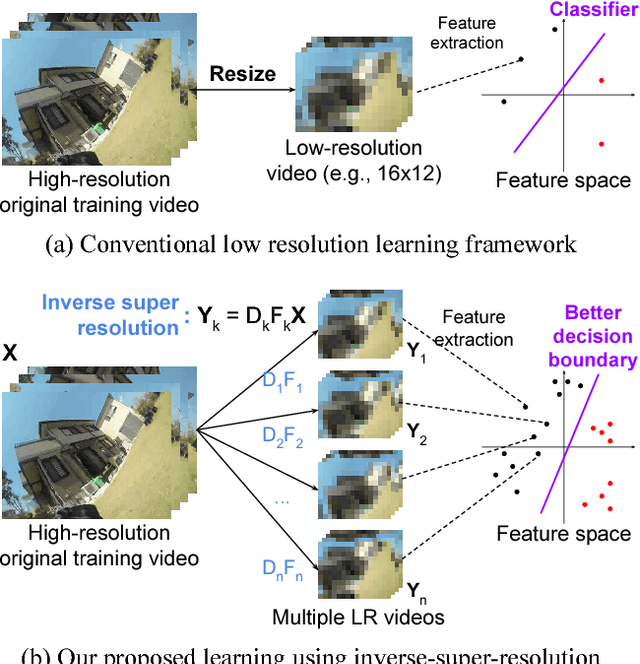

Privacy protection from surreptitious video recordings is an important societal challenge. We desire a computer vision system (e.g., a robot) that can recognize human activities and assist our daily life, yet ensure that it is not recording video that may invade our privacy. This paper presents a fundamental approach to address such contradicting objectives: human activity recognition while only using extreme low-resolution (e.g., 16x12) anonymized videos. We introduce the paradigm of inverse super resolution (ISR), the concept of learning the optimal set of image transformations to generate multiple low-resolution (LR) training videos from a single video. Our ISR learns different types of sub-pixel transformations optimized for the activity classification, allowing the classifier to best take advantage of existing high-resolution videos (e.g., YouTube videos) by creating multiple LR training videos tailored for the problem. We experimentally confirm that the paradigm of inverse super resolution is able to benefit activity recognition from extreme low-resolution videos.
Joint Inference of Groups, Events and Human Roles in Aerial Videos
May 22, 2015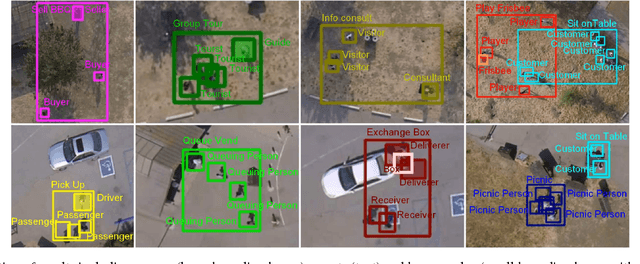
With the advent of drones, aerial video analysis becomes increasingly important; yet, it has received scant attention in the literature. This paper addresses a new problem of parsing low-resolution aerial videos of large spatial areas, in terms of 1) grouping, 2) recognizing events and 3) assigning roles to people engaged in events. We propose a novel framework aimed at conducting joint inference of the above tasks, as reasoning about each in isolation typically fails in our setting. Given noisy tracklets of people and detections of large objects and scene surfaces (e.g., building, grass), we use a spatiotemporal AND-OR graph to drive our joint inference, using Markov Chain Monte Carlo and dynamic programming. We also introduce a new formalism of spatiotemporal templates characterizing latent sub-events. For evaluation, we have collected and released a new aerial videos dataset using a hex-rotor flying over picnic areas rich with group events. Our results demonstrate that we successfully address above inference tasks under challenging conditions.
Pooled Motion Features for First-Person Videos
May 06, 2015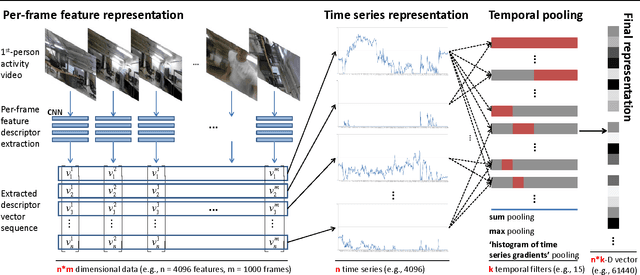
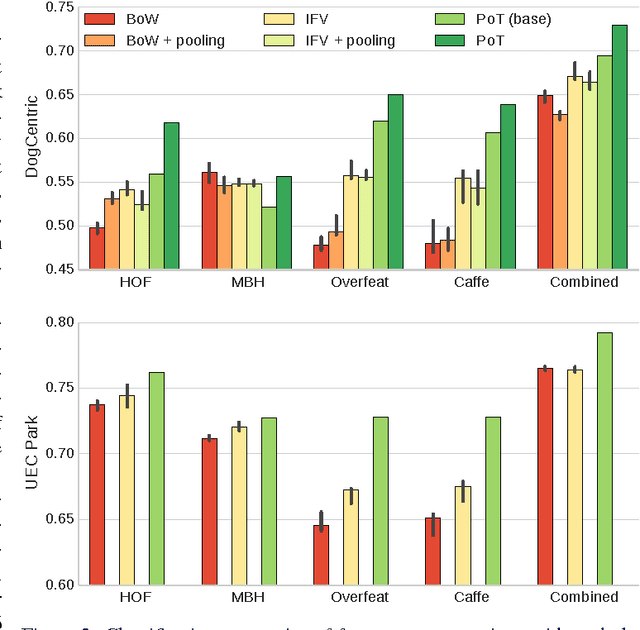
In this paper, we present a new feature representation for first-person videos. In first-person video understanding (e.g., activity recognition), it is very important to capture both entire scene dynamics (i.e., egomotion) and salient local motion observed in videos. We describe a representation framework based on time series pooling, which is designed to abstract short-term/long-term changes in feature descriptor elements. The idea is to keep track of how descriptor values are changing over time and summarize them to represent motion in the activity video. The framework is general, handling any types of per-frame feature descriptors including conventional motion descriptors like histogram of optical flows (HOF) as well as appearance descriptors from more recent convolutional neural networks (CNN). We experimentally confirm that our approach clearly outperforms previous feature representations including bag-of-visual-words and improved Fisher vector (IFV) when using identical underlying feature descriptors. We also confirm that our feature representation has superior performance to existing state-of-the-art features like local spatio-temporal features and Improved Trajectory Features (originally developed for 3rd-person videos) when handling first-person videos. Multiple first-person activity datasets were tested under various settings to confirm these findings.