 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Multi-Robot Networks via MLLM-Driven Sensing, Communication, and Computation: A Comprehensive Survey
Mar 31, 2026Imagine advanced humanoid robots, powered by multimodal large language models (MLLMs), coordinating missions across industries like warehouse logistics, manufacturing, and safety rescue. While individual robots show local autonomy, realistic tasks demand coordination among multiple agents sharing vast streams of sensor data. Communication is indispensable, yet transmitting comprehensive data can overwhelm networks, especially when a system-level orchestrator or cloud-based MLLM fuses multimodal inputs for route planning or anomaly detection. These tasks are often initiated by high-level natural language instructions. This intent serves as a filter for resource optimization: by understanding the goal via MLLMs, the system can selectively activate relevant sensing modalities, dynamically allocate bandwidth, and determine computation placement. Thus, R2X is fundamentally an intent-to-resource orchestration problem where sensing, communication, and computation are jointly optimized to maximize task-level success under resource constraints. This survey examines how integrated design paves the way for multi-robot coordination under MLLM guidance. We review state-of-the-art sensing modalities, communication strategies, and computing approaches, highlighting how reasoning is split between on-device models and powerful edge/cloud servers. We present four end-to-end demonstrations (sense -> communicate -> compute -> act): (i) digital-twin warehouse navigation with predictive link context, (ii) mobility-driven proactive MCS control, (iii) a FollowMe robot with a semantic-sensing switch, and (iv) real-hardware open-vocabulary trash sorting via edge-assisted MLLM grounding. We emphasize system-level metrics -- payload, latency, and success -- to show why R2X orchestration outperforms purely on-device baselines.
Accuracy-Delay Trade-Off in LLM Offloading via Token-Level Uncertainty
Feb 08, 2026Large language models (LLMs) offer significant potential for intelligent mobile services but are computationally intensive for resource-constrained devices. Mobile edge computing (MEC) allows such devices to offload inference tasks to edge servers (ESs), yet introduces latency due to communication and serverside queuing, especially in multi-user environments. In this work, we propose an uncertainty-aware offloading framework that dynamically decides whether to perform inference locally or offload it to the ES, based on token-level uncertainty and resource constraints. We define a margin-based token-level uncertainty metric and demonstrate its correlation with model accuracy. Leveraging this metric, we design a greedy offloading algorithm (GOA) that minimizes delay while maintaining accuracy by prioritizing offloading for highuncertainty queries. Our experiments show that GOA consistently achieves a favorable trade-off, outperforming baseline strategies in both accuracy and latency across varying user densities, and operates with practical computation time. These results establish GOA as a scalable and effective solution for LLM inference in MEC environments.
End-to-End Secure Connection Probability in MultiLayer Networks with Heterogeneous Rician Fading
Feb 08, 2026Ensuring physical-layer security in non-terrestrial networks (NTNs) is challenging due to their global coverage and multi-hop relaying across heterogeneous network layers, where the locations and channels of potential eavesdroppers are typically unknown. In this work, we derive a tractable closedform expression of the end-to-end secure connection probability (SCP) of multi-hop relay routes under heterogeneous Rician fading. The resulting formula shares the same functional form as prior Rayleigh-based approximations but for the coefficients, thereby providing analytical support for the effectiveness of heuristic posterior coefficient calibration adopted in prior work. Numerical experiments under various conditions show that the proposed scheme estimates the SCP with an 1%p error in most cases; and doubles the accuracy compared with the conventional scheme even in the worst case. As a case study, we apply the proposed framework to real-world space-air-groundsea integrated network dataset, showing that the derived SCP accurately captures observed security trends in practical settings.
Semantic Pilot Design for Data-Aided Channel Estimation Using a Large Language Model
Feb 04, 2026This paper proposes a semantic pilot design for data-aided channel estimation in text-inclusive data transmission, using a large language model (LLM). In this scenario, channel impairments often appear as typographical errors in the decoded text, which can be corrected using an LLM. The proposed method compares the initially decoded text with the LLM-corrected version to identify reliable decoded symbols. A set of selected symbols, referred to as a semantic pilot, is used as an additional pilot for data-aided channel estimation. To the best of our knowledge, this work is the first to leverage semantic information for reliable symbol selection. Simulation results demonstrate that the proposed scheme outperforms conventional pilot-only estimation, achieving lower normalized mean squared error and phase error of the estimated channel, as well as reduced bit error rate.
User-Centric Stream Sensing for Grant-Free Access: Deep Learning with Covariance Differencing
Jan 14, 2026Grant-free (GF) access is essential for massive connectivity but faces collision risks due to uncoordinated transmissions. While user-side sensing can mitigate these collisions by enabling autonomous transmission decisions, conventional methods become ineffective in overloaded scenarios where active streams exceed receive antennas. To address this problem, we propose a differential stream sensing framework that reframes the problem from estimating the total stream count to isolating newly activated streams via covariance differencing. We analyze the covariance deviation induced by channel variations to establish a theoretical bound based on channel correlation for determining the sensing window size. To mitigate residual interference from finite sampling, a deep learning (DL) classifier is integrated. Simulations across both independent and identically distributed flat Rayleigh fading and standardized channel environments demonstrate that the proposed method consistently outperforms non-DL baselines and remains robust in overloaded scenarios.
ALERT Open Dataset and Input-Size-Agnostic Vision Transformer for Driver Activity Recognition using IR-UWB
Dec 13, 2025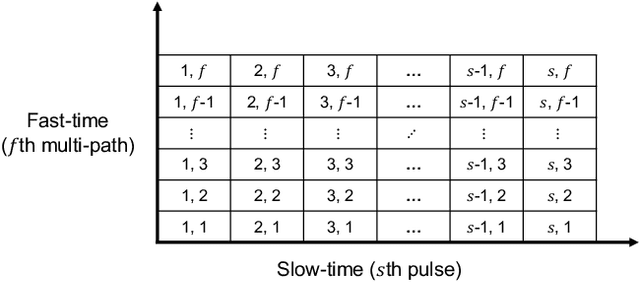
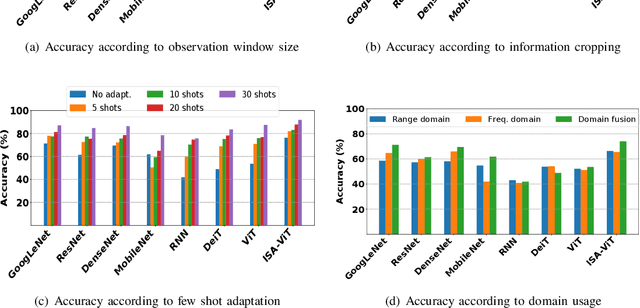
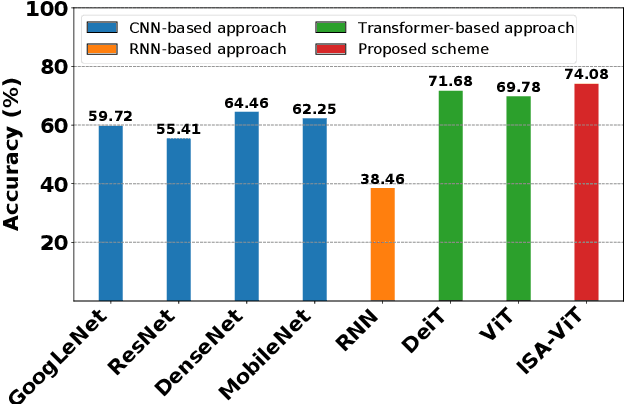
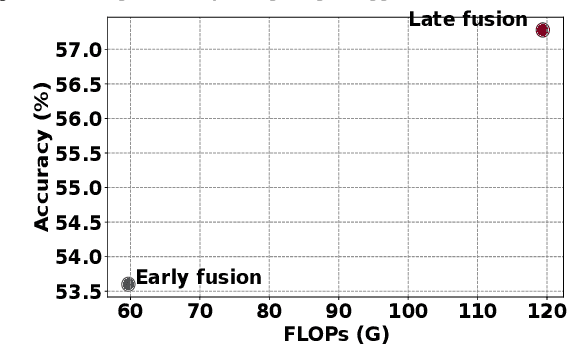
Distracted driving contributes to fatal crashes worldwide. To address this, researchers are using driver activity recognition (DAR) with impulse radio ultra-wideband (IR-UWB) radar, which offers advantages such as interference resistance, low power consumption, and privacy preservation. However, two challenges limit its adoption: the lack of large-scale real-world UWB datasets covering diverse distracted driving behaviors, and the difficulty of adapting fixed-input Vision Transformers (ViTs) to UWB radar data with non-standard dimensions. This work addresses both challenges. We present the ALERT dataset, which contains 10,220 radar samples of seven distracted driving activities collected in real driving conditions. We also propose the input-size-agnostic Vision Transformer (ISA-ViT), a framework designed for radar-based DAR. The proposed method resizes UWB data to meet ViT input requirements while preserving radar-specific information such as Doppler shifts and phase characteristics. By adjusting patch configurations and leveraging pre-trained positional embedding vectors (PEVs), ISA-ViT overcomes the limitations of naive resizing approaches. In addition, a domain fusion strategy combines range- and frequency-domain features to further improve classification performance. Comprehensive experiments demonstrate that ISA-ViT achieves a 22.68% accuracy improvement over an existing ViT-based approach for UWB-based DAR. By publicly releasing the ALERT dataset and detailing our input-size-agnostic strategy, this work facilitates the development of more robust and scalable distracted driving detection systems for real-world deployment.
Faithful and Fast Influence Function via Advanced Sampling
Oct 30, 2025How can we explain the influence of training data on black-box models? Influence functions (IFs) offer a post-hoc solution by utilizing gradients and Hessians. However, computing the Hessian for an entire dataset is resource-intensive, necessitating a feasible alternative. A common approach involves randomly sampling a small subset of the training data, but this method often results in highly inconsistent IF estimates due to the high variance in sample configurations. To address this, we propose two advanced sampling techniques based on features and logits. These samplers select a small yet representative subset of the entire dataset by considering the stochastic distribution of features or logits, thereby enhancing the accuracy of IF estimations. We validate our approach through class removal experiments, a typical application of IFs, using the F1-score to measure how effectively the model forgets the removed class while maintaining inference consistency on the remaining classes. Our method reduces computation time by 30.1% and memory usage by 42.2%, or improves the F1-score by 2.5% compared to the baseline.
Large Multimodal Models-Empowered Task-Oriented Autonomous Communications: Design Methodology and Implementation Challenges
Oct 23, 2025Large language models (LLMs) and large multimodal models (LMMs) have achieved unprecedented breakthrough, showcasing remarkable capabilities in natural language understanding, generation, and complex reasoning. This transformative potential has positioned them as key enablers for 6G autonomous communications among machines, vehicles, and humanoids. In this article, we provide an overview of task-oriented autonomous communications with LLMs/LMMs, focusing on multimodal sensing integration, adaptive reconfiguration, and prompt/fine-tuning strategies for wireless tasks. We demonstrate the framework through three case studies: LMM-based traffic control, LLM-based robot scheduling, and LMM-based environment-aware channel estimation. From experimental results, we show that the proposed LLM/LMM-aided autonomous systems significantly outperform conventional and discriminative deep learning (DL) model-based techniques, maintaining robustness under dynamic objectives, varying input parameters, and heterogeneous multimodal conditions where conventional static optimization degrades.
Multiple Active STAR-RIS-Assisted Secure Integrated Sensing and Communication via Cooperative Beamforming
Jul 24, 2025This paper explores an integrated sensing and communication (ISAC) network empowered by multiple active simultaneously transmitting and reflecting reconfigurable intelligent surfaces (STAR-RISs). A base station (BS) furnishes downlink communication to multiple users while concurrently interrogating a sensing target. We jointly optimize the BS transmit beamformer and the reflection/transmission coefficients of every active STAR-RIS in order to maximize the aggregate communication sum-rate, subject to (i) a stringent sensing signal-to-interference-plus-noise ratio (SINR) requirement, (ii) an upper bound on the leakage of confidential information, and (iii) individual hardware and total power constraints at both the BS and the STAR-RISs. The resulting highly non-convex program is tackled with an efficient alternating optimization (AO) framework. First, the original formulation is reformulated into an equivalent yet more tractable representation and partitioned into subproblems. The BS beamformer is updated in closed form via the Karush-Kuhn-Tucker (KKT) conditions, whereas the STAR-RIS reflection and transmission vectors are refined through successive convex approximation (SCA), yielding a semidefinite program that is then solved via semidefinite relaxation. Comprehensive simulations demonstrate that the proposed algorithm delivers substantial sum-rate gains over passive-RIS and single STAR-RIS baselines, all the while rigorously meeting the prescribed sensing and security constraints.
Joint Spectrum Sensing and Resource Allocation for OFDMA-based Underwater Acoustic Communications
Jun 16, 2025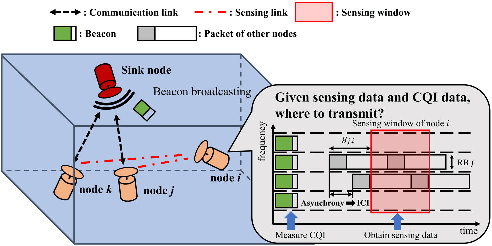
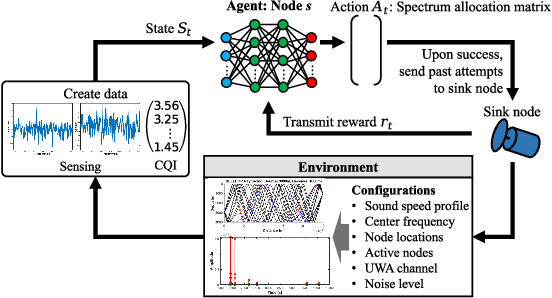
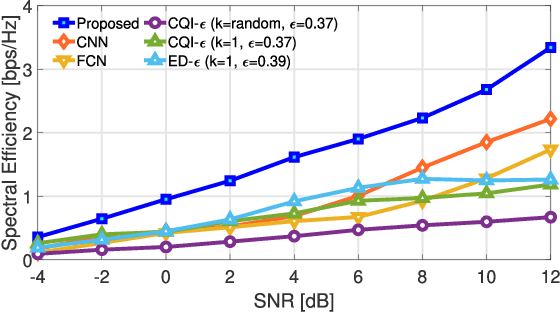
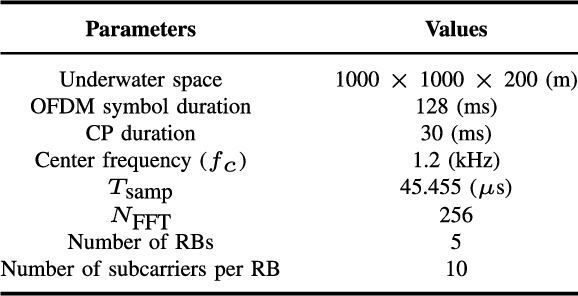
Underwater acoustic (UWA) communications generally rely on cognitive radio (CR)-based ad-hoc networks due to challenges such as long propagation delay, limited channel resources, and high attenuation. To address the constraints of limited frequency resources, UWA communications have recently incorporated orthogonal frequency division multiple access (OFDMA), significantly enhancing spectral efficiency (SE) through multiplexing gains. Still, {the} low propagation speed of UWA signals, combined with {the} dynamic underwater environment, creates asynchrony in multiple access scenarios. This causes inaccurate spectrum sensing as inter-carrier interference (ICI) increases, which leads to difficulties in resource allocation. As efficient resource allocation is essential for achieving high-quality communication in OFDMA-based CR networks, these challenges degrade communication reliability in UWA systems. To resolve the issue, we propose an end-to-end sensing and resource optimization method using deep reinforcement learning (DRL) in an OFDMA-based UWA-CR network. Through extensive simulations, we confirm that the proposed method is superior to baseline schemes, outperforming other methods by 42.9 % in SE and 4.4 % in communication success rate.