 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful and Fast Influence Function via Advanced Sampling
Oct 30, 2025How can we explain the influence of training data on black-box models? Influence functions (IFs) offer a post-hoc solution by utilizing gradients and Hessians. However, computing the Hessian for an entire dataset is resource-intensive, necessitating a feasible alternative. A common approach involves randomly sampling a small subset of the training data, but this method often results in highly inconsistent IF estimates due to the high variance in sample configurations. To address this, we propose two advanced sampling techniques based on features and logits. These samplers select a small yet representative subset of the entire dataset by considering the stochastic distribution of features or logits, thereby enhancing the accuracy of IF estimations. We validate our approach through class removal experiments, a typical application of IFs, using the F1-score to measure how effectively the model forgets the removed class while maintaining inference consistency on the remaining classes. Our method reduces computation time by 30.1% and memory usage by 42.2%, or improves the F1-score by 2.5% compared to the baseline.
Multiple Active STAR-RIS-Assisted Secure Integrated Sensing and Communication via Cooperative Beamforming
Jul 24, 2025This paper explores an integrated sensing and communication (ISAC) network empowered by multiple active simultaneously transmitting and reflecting reconfigurable intelligent surfaces (STAR-RISs). A base station (BS) furnishes downlink communication to multiple users while concurrently interrogating a sensing target. We jointly optimize the BS transmit beamformer and the reflection/transmission coefficients of every active STAR-RIS in order to maximize the aggregate communication sum-rate, subject to (i) a stringent sensing signal-to-interference-plus-noise ratio (SINR) requirement, (ii) an upper bound on the leakage of confidential information, and (iii) individual hardware and total power constraints at both the BS and the STAR-RISs. The resulting highly non-convex program is tackled with an efficient alternating optimization (AO) framework. First, the original formulation is reformulated into an equivalent yet more tractable representation and partitioned into subproblems. The BS beamformer is updated in closed form via the Karush-Kuhn-Tucker (KKT) conditions, whereas the STAR-RIS reflection and transmission vectors are refined through successive convex approximation (SCA), yielding a semidefinite program that is then solved via semidefinite relaxation. Comprehensive simulations demonstrate that the proposed algorithm delivers substantial sum-rate gains over passive-RIS and single STAR-RIS baselines, all the while rigorously meeting the prescribed sensing and security constraints.
Joint Optimization of User Association and Resource Allocation for Load Balancing With Multi-Level Fairness
May 13, 2025User association, the problem of assigning each user device to a suitable base station, is increasingly crucial as wireless networks become denser and serve more users with diverse service demands. The joint optimization of user association and resource allocation (UARA) is a fundamental issue for future wireless networks, as it plays a pivotal role in enhancing overall network performance, user fairness, and resource efficiency. Given the latency-sensitive nature of emerging network applications, network management favors algorithms that are simple and computationally efficient rather than complex centralized approaches. Thus, distributed pricing-based strategies have gained prominence in the UARA literature, demonstrating practicality and effectiveness across various objective functions, e.g., sum-rate, proportional fairness, max-min fairness, and alpha-fairness. While the alpha-fairness frameworks allow for flexible adjustments between efficiency and fairness via a single parameter $\alpha$, existing works predominantly assume a homogeneous fairness context, assigning an identical $\alpha$ value to all users. Real-world networks, however, frequently require differentiated user prioritization due to varying application requirements and latency. To bridge this gap, we propose a novel heterogeneous alpha-fairness (HAF) objective function, assigning distinct {\alpha} values to different users, thereby providing enhanced control over the balance between throughput, fairness, and latency across the network. We present a distributed, pricing-based optimization approach utilizing an auxiliary variable framework and provide analytical proof of its convergence to an $\epsilon$-optimal solution, where the optimality gap $\epsilon$ decreases with the number of iterations.
Secure Multi-Hop Relaying in Large-Scale Space-Air-Ground-Sea Integrated Networks
May 01, 2025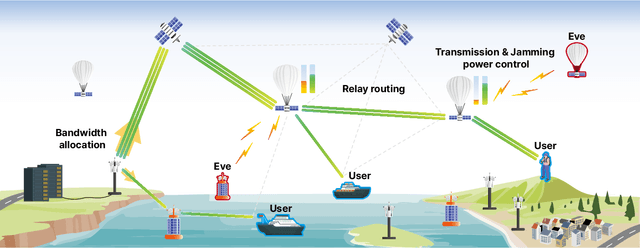
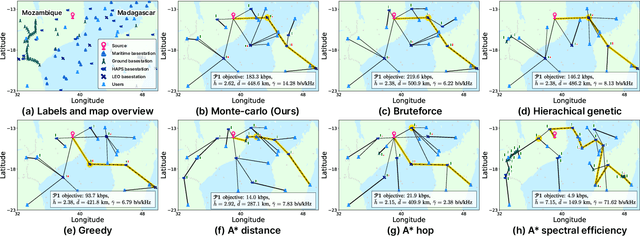

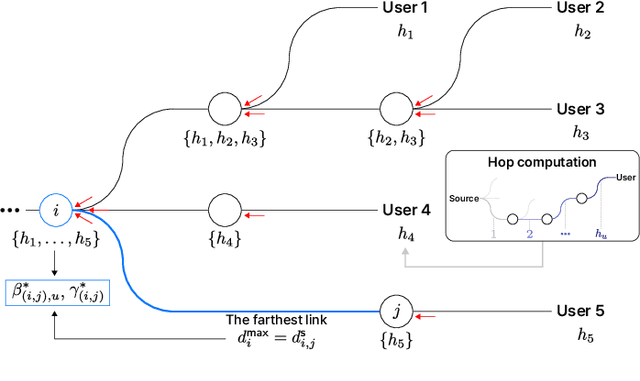
As a key enabler of borderless and ubiquitous connectivity, space-air-ground-sea integrated networks (SAGSINs) are expected to be a cornerstone of 6G wireless communications. However, the multi-tiered and global-scale nature of SAGSINs also amplifies the security vulnerabilities, particularly due to the hidden, passive eavesdroppers distributed throughout the network. In this paper, we introduce a joint optimization framework for multi-hop relaying in SAGSINs that maximizes the minimum user throughput while ensuring a minimum strictly positive secure connection (SPSC) probability. We first derive a closed-form expression for the SPSC probability and incorporate this into a cross-layer optimization framework that jointly optimizes radio resources and relay routes. Specifically, we propose an $\mathcal{O}(1)$ optimal frequency allocation and power splitting strategy-dividing power levels of data transmission and cooperative jamming. We then introduce a Monte-Carlo relay routing algorithm that closely approaches the performance of the numerical upper-bound method. We validate our framework on testbeds built with real-world dataset. All source code and data for reproducing the numerical experiments will be open-sourced.
Fed-ZOE: Communication-Efficient Over-the-Air Federated Learning via Zeroth-Order Estimation
Dec 21, 2024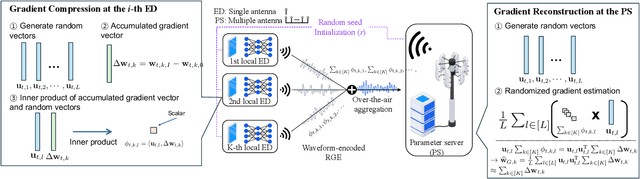
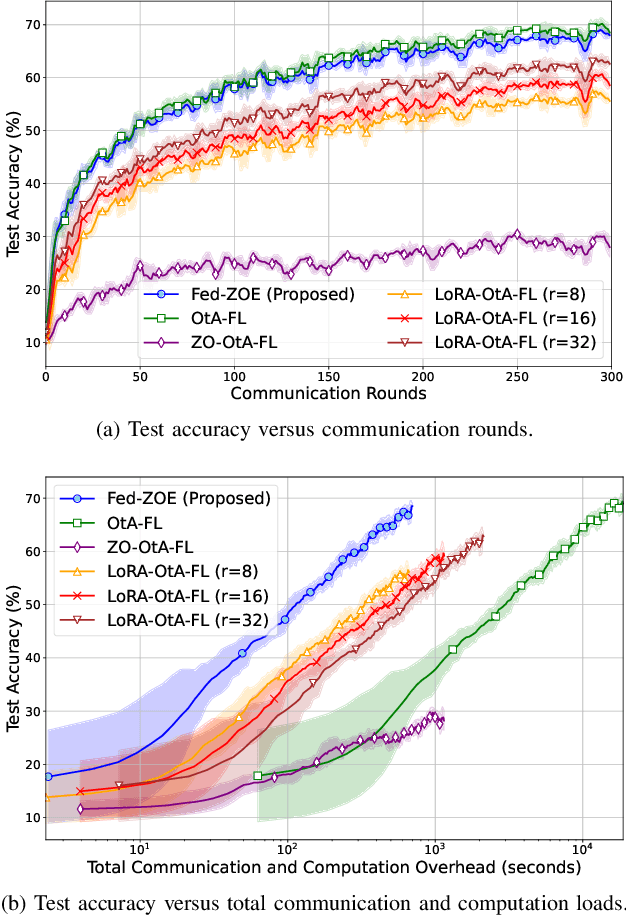

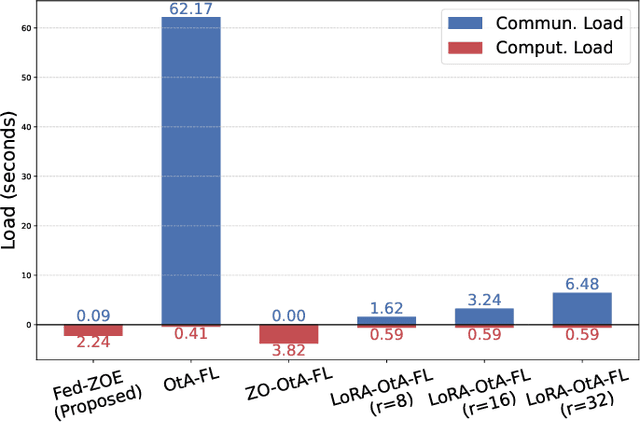
As 6G and beyond networks grow increasingly complex and interconnected, federated learning (FL) emerges as an indispensable paradigm for securely and efficiently leveraging decentralized edge data for AI. By virtue of the superposition property of communication signals, over-the-air FL (OtA-FL) achieves constant communication overhead irrespective of the number of edge devices (EDs). However, training neural networks over the air still incurs substantial communication costs, as the number of transmitted symbols equals the number of trainable parameters. To alleviate this issue, the most straightforward approach is to reduce the number of transmitted symbols by 1) gradient compression and 2) gradient sparsification. Unfortunately, these methods are incompatible with OtA-FL due to the loss of its superposition property. In this work, we introduce federated zeroth-order estimation (Fed-ZOE), an efficient framework inspired by the randomized gradient estimator (RGE) commonly used in zeroth-order optimization (ZOO). In FedZOE, EDs perform local weight updates as in standard FL, but instead of transmitting full gradient vectors, they send compressed local model update vectors in the form of several scalar-valued inner products between the local model update vectors and random vectors. These scalar values enable the parameter server (PS) to reconstruct the gradient using the RGE trick with highly reduced overhead, as well as preserving the superposition property. Unlike conventional ZOO leveraging RGE for step-wise gradient descent, Fed-ZOE compresses local model update vectors before transmission, thereby achieving higher accuracy and computational efficiency. Numerical evaluations using ResNet-18 on datasets such as CIFAR-10, TinyImageNet, SVHN, CIFAR-100, and Brain-CT demonstrate that Fed-ZOE achieves performance comparable to Fed-OtA while drastically reducing communication costs.
Replace-then-Perturb: Targeted Adversarial Attacks With Visual Reasoning for Vision-Language Models
Nov 01, 2024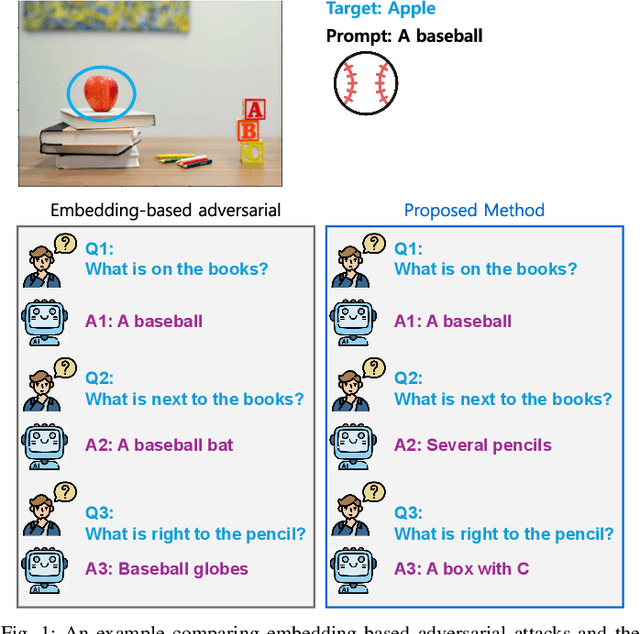
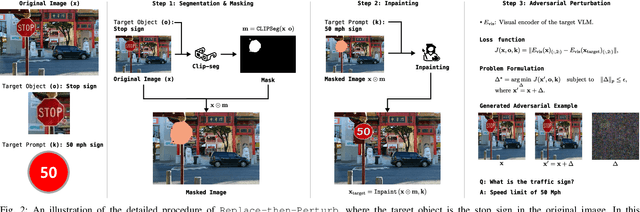
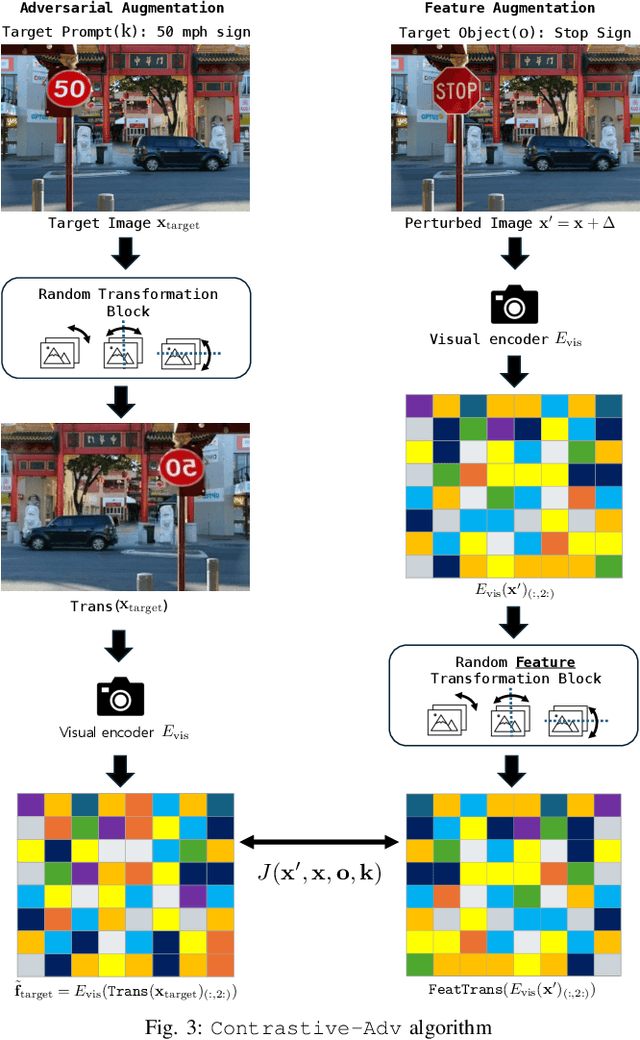

The conventional targeted adversarial attacks add a small perturbation to an image to make neural network models estimate the image as a predefined target class, even if it is not the correct target class. Recently, for visual-language models (VLMs), the focus of targeted adversarial attacks is to generate a perturbation that makes VLMs answer intended target text outputs. For example, they aim to make a small perturbation on an image to make VLMs' answers change from "there is an apple" to "there is a baseball." However, answering just intended text outputs is insufficient for tricky questions like "if there is a baseball, tell me what is below it." This is because the target of the adversarial attacks does not consider the overall integrity of the original image, thereby leading to a lack of visual reasoning. In this work, we focus on generating targeted adversarial examples with visual reasoning against VLMs. To this end, we propose 1) a novel adversarial attack procedure -- namely, Replace-then-Perturb and 2) a contrastive learning-based adversarial loss -- namely, Contrastive-Adv. In Replace-then-Perturb, we first leverage a text-guided segmentation model to find the target object in the image. Then, we get rid of the target object and inpaint the empty space with the desired prompt. By doing this, we can generate a target image corresponding to the desired prompt, while maintaining the overall integrity of the original image. Furthermore, in Contrastive-Adv, we design a novel loss function to obtain better adversarial examples. Our extensive benchmark results demonstrate that Replace-then-Perturb and Contrastive-Adv outperform the baseline adversarial attack algorithms. We note that the source code to reproduce the results will be available.
Unveiling Hidden Visual Information: A Reconstruction Attack Against Adversarial Visual Information Hiding
Aug 08, 2024This paper investigates the security vulnerabilities of adversarial-example-based image encryption by executing data reconstruction (DR) attacks on encrypted images. A representative image encryption method is the adversarial visual information hiding (AVIH), which uses type-I adversarial example training to protect gallery datasets used in image recognition tasks. In the AVIH method, the type-I adversarial example approach creates images that appear completely different but are still recognized by machines as the original ones. Additionally, the AVIH method can restore encrypted images to their original forms using a predefined private key generative model. For the best security, assigning a unique key to each image is recommended; however, storage limitations may necessitate some images sharing the same key model. This raises a crucial security question for AVIH: How many images can safely share the same key model without being compromised by a DR attack? To address this question, we introduce a dual-strategy DR attack against the AVIH encryption method by incorporating (1) generative-adversarial loss and (2) augmented identity loss, which prevent DR from overfitting -- an issue akin to that in machine learning. Our numerical results validate this approach through image recognition and re-identification benchmarks, demonstrating that our strategy can significantly enhance the quality of reconstructed images, thereby requiring fewer key-sharing encrypted images. Our source code to reproduce our results will be available soon.
Non-iterative Optimization of Trajectory and Radio Resource for Aerial Network
May 02, 2024We address a joint trajectory planning, user association, resource allocation, and power control problem to maximize proportional fairness in the aerial IoT network, considering practical end-to-end quality-of-service (QoS) and communication schedules. Though the problem is rather ancient, apart from the fact that the previous approaches have never considered user- and time-specific QoS, we point out a prevalent mistake in coordinate optimization approaches adopted by the majority of the literature. Coordinate optimization approaches, which repetitively optimize radio resources for a fixed trajectory and vice versa, generally converge to local optima when all variables are differentiable. However, these methods often stagnate at a non-stationary point, significantly degrading the network utility in mixed-integer problems such as joint trajectory and radio resource optimization. We detour this problem by converting the formulated problem into the Markov decision process (MDP). Exploiting the beneficial characteristics of the MDP, we design a non-iterative framework that cooperatively optimizes trajectory and radio resources without initial trajectory choice. The proposed framework can incorporate various trajectory planning algorithms such as the genetic algorithm, tree search, and reinforcement learning. Extensive comparisons with diverse baselines verify that the proposed framework significantly outperforms the state-of-the-art method, nearly achieving the global optimum. Our implementation code is available at https://github.com/hslyu/dbspf.
Patch-MI: Enhancing Model Inversion Attacks via Patch-Based Reconstruction
Dec 12, 2023
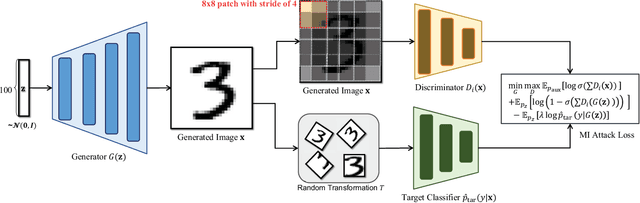

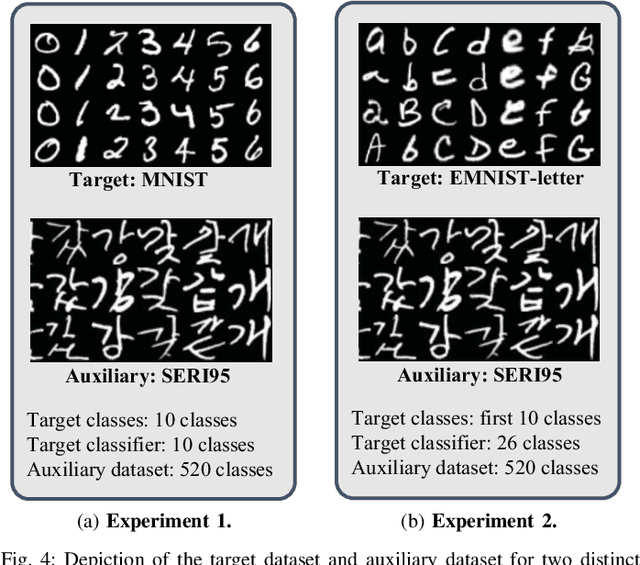
Model inversion (MI) attacks aim to reveal sensitive information in training datasets by solely accessing model weights. Generative MI attacks, a prominent strand in this field, utilize auxiliary datasets to recreate target data attributes, restricting the images to remain photo-realistic, but their success often depends on the similarity between auxiliary and target datasets. If the distributions are dissimilar, existing MI attack attempts frequently fail, yielding unrealistic or target-unrelated results. In response to these challenges, we introduce a groundbreaking approach named Patch-MI, inspired by jigsaw puzzle assembly. To this end, we build upon a new probabilistic interpretation of MI attacks, employing a generative adversarial network (GAN)-like framework with a patch-based discriminator. This approach allows the synthesis of images that are similar to the target dataset distribution, even in cases of dissimilar auxiliary dataset distribution. Moreover, we artfully employ a random transformation block, a sophisticated maneuver that crafts generalized images, thus enhancing the efficacy of the target classifier. Our numerical and graphical findings demonstrate that Patch-MI surpasses existing generative MI methods in terms of accuracy, marking significant advancements while preserving comparable statistical dataset quality. For reproducibility of our results, we make our source code publicly available in https://github.com/jonggyujang0123/Patch-Attack.
Deeper Understanding of Black-box Predictions via Generalized Influence Functions
Dec 09, 2023Influence functions (IFs) elucidate how learning data affects model behavior. However, growing non-convexity and the number of parameters in modern large-scale models lead to imprecise influence approximation and instability in computations. We highly suspect that the first-order approximation in large models causes such fragility, as IFs change all parameters including possibly nuisance parameters that are irrelevant to the examined data. Thus, we attempt to selectively analyze parameters associated with the data. However, simply computing influence from the chosen parameters can be misleading, as it fails to nullify the subliminal impact of unselected parameters. Our approach introduces generalized IFs, precisely estimating target parameters' influence while considering fixed parameters' effects. Unlike the classic IFs, we newly adopt a method to identify pertinent target parameters closely associated with the analyzed data. Furthermore, we tackle computational instability with a robust inverse-Hessian-vector product approximation. Remarkably, the proposed approximation algorithm guarantees convergence regardless of the network configurations. We evaluated our approach on ResNet-18 and VGG-11 for class removal and backdoor model recovery. Modifying just 10\% of the network yields results comparable to the network retrained from scratch. Aligned with our first guess, we also confirm that modifying an excessive number of parameters results in a decline in network utility. We believe our proposal can become a versatile tool for model analysis across various AI domains, appealing to both specialists and general readers. Codes are available at https://github.com/hslyu/GIF.