 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-based Object Grounding and Robot Grasp Detection with Spatial Reasoning
Sep 09, 2025Enabling robots to grasp objects specified through natural language is essential for effective human-robot interaction, yet it remains a significant challenge. Existing approaches often struggle with open-form language expressions and typically assume unambiguous target objects without duplicates. Moreover, they frequently rely on costly, dense pixel-wise annotations for both object grounding and grasp configuration. We present Attribute-based Object Grounding and Robotic Grasping (OGRG), a novel framework that interprets open-form language expressions and performs spatial reasoning to ground target objects and predict planar grasp poses, even in scenes containing duplicated object instances. We investigate OGRG in two settings: (1) Referring Grasp Synthesis (RGS) under pixel-wise full supervision, and (2) Referring Grasp Affordance (RGA) using weakly supervised learning with only single-pixel grasp annotations. Key contributions include a bi-directional vision-language fusion module and the integration of depth information to enhance geometric reasoning, improving both grounding and grasping performance. Experiment results show that OGRG outperforms strong baselines in tabletop scenes with diverse spatial language instructions. In RGS, it operates at 17.59 FPS on a single NVIDIA RTX 2080 Ti GPU, enabling potential use in closed-loop or multi-object sequential grasping, while delivering superior grounding and grasp prediction accuracy compared to all the baselines considered. Under the weakly supervised RGA setting, OGRG also surpasses baseline grasp-success rates in both simulation and real-robot trials, underscoring the effectiveness of its spatial reasoning design. Project page: https://z.umn.edu/ogrg
UA-Pose: Uncertainty-Aware 6D Object Pose Estimation and Online Object Completion with Partial References
Jun 09, 2025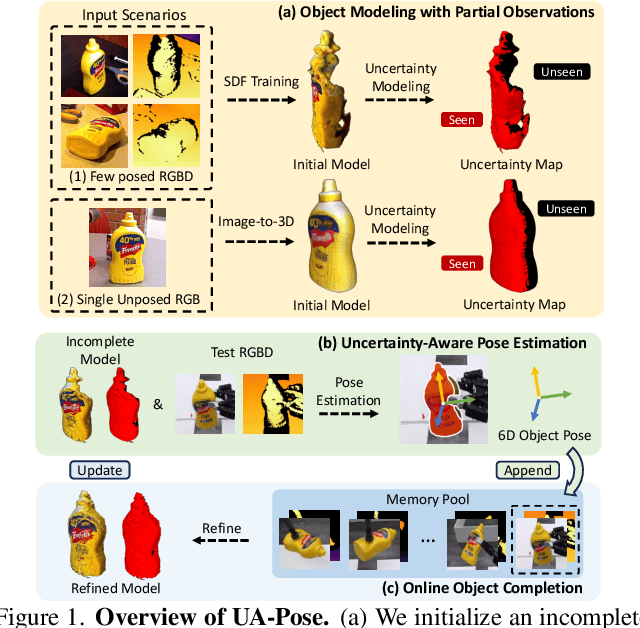

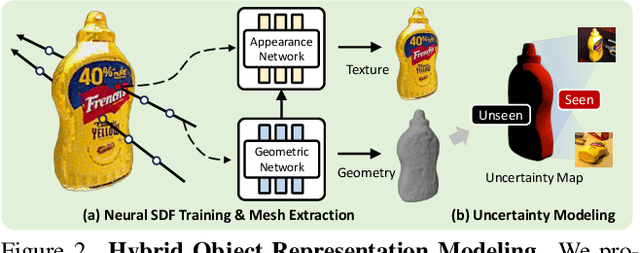

6D object pose estimation has shown strong generalizability to novel objects. However, existing methods often require either a complete, well-reconstructed 3D model or numerous reference images that fully cover the object. Estimating 6D poses from partial references, which capture only fragments of an object's appearance and geometry, remains challenging. To address this, we propose UA-Pose, an uncertainty-aware approach for 6D object pose estimation and online object completion specifically designed for partial references. We assume access to either (1) a limited set of RGBD images with known poses or (2) a single 2D image. For the first case, we initialize a partial object 3D model based on the provided images and poses, while for the second, we use image-to-3D techniques to generate an initial object 3D model. Our method integrates uncertainty into the incomplete 3D model, distinguishing between seen and unseen regions. This uncertainty enables confidence assessment in pose estimation and guides an uncertainty-aware sampling strategy for online object completion, enhancing robustness in pose estimation accuracy and improving object completeness. We evaluate our method on the YCB-Video, YCBInEOAT, and HO3D datasets, including RGBD sequences of YCB objects manipulated by robots and human hands. Experimental results demonstrate significant performance improvements over existing methods, particularly when object observations are incomplete or partially captured. Project page: https://minfenli.github.io/UA-Pose/
ReCLIP: Refine Contrastive Language Image Pre-Training with Source Free Domain Adaptation
Aug 04, 2023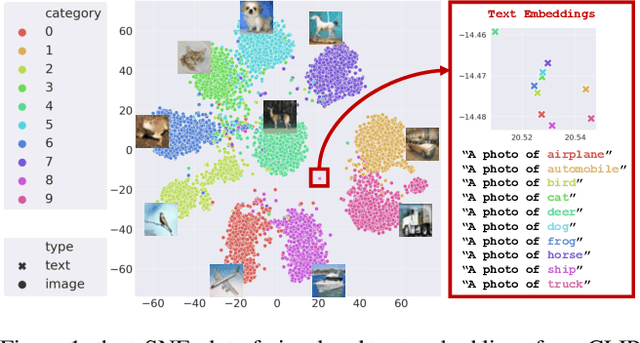
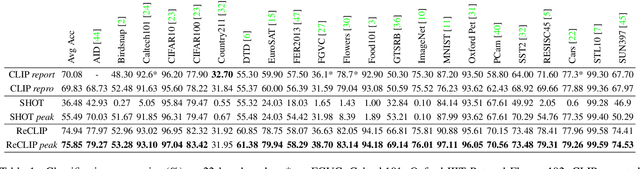
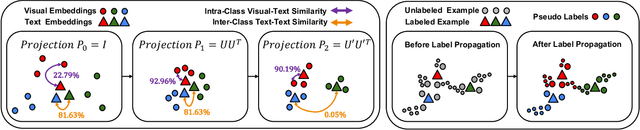
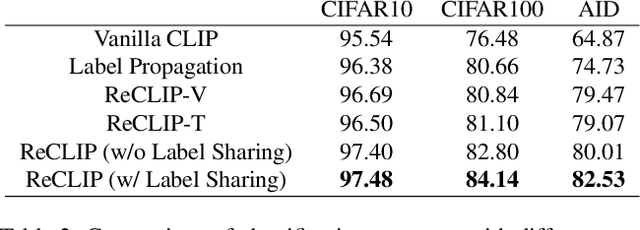
Large-scale Pre-Training Vision-Language Model such as CLIP has demonstrated outstanding performance in zero-shot classification, e.g. achieving 76.3% top-1 accuracy on ImageNet without seeing any example, which leads to potential benefits to many tasks that have no labeled data. However, while applying CLIP to a downstream target domain, the presence of visual and text domain gaps and cross-modality misalignment can greatly impact the model performance. To address such challenges, we propose ReCLIP, the first source-free domain adaptation method for vision-language models, which does not require any source data or target labeled data. ReCLIP first learns a projection space to mitigate the misaligned visual-text embeddings and learns pseudo labels, and then deploys cross-modality self-training with the pseudo labels, to update visual and text encoders, refine labels and reduce domain gaps and misalignments iteratively. With extensive experiments, we demonstrate ReCLIP reduces the average error rate of CLIP from 30.17% to 25.06% on 22 image classification benchmarks.
CameraPose: Weakly-Supervised Monocular 3D Human Pose Estimation by Leveraging In-the-wild 2D Annotations
Jan 08, 2023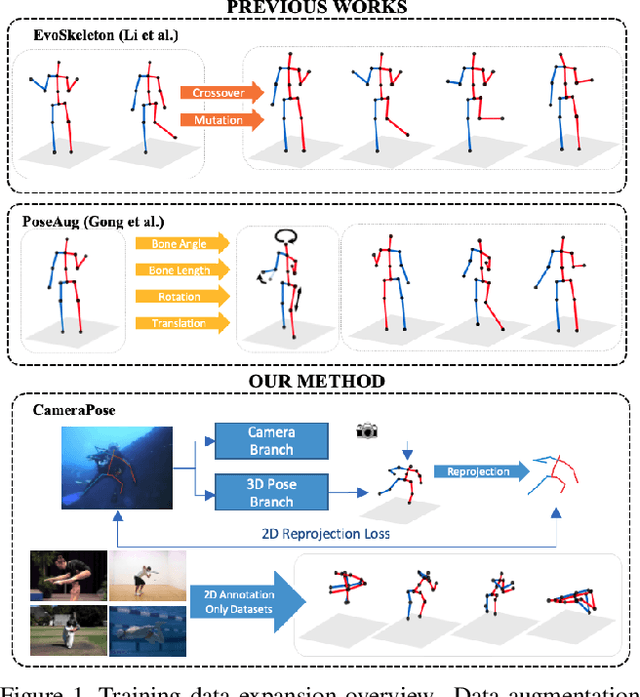
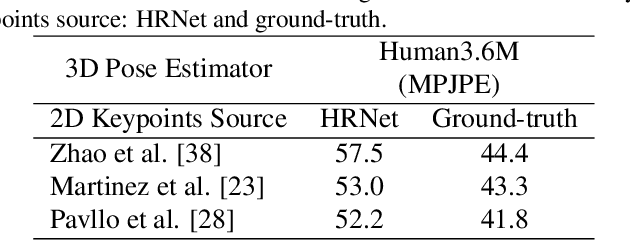
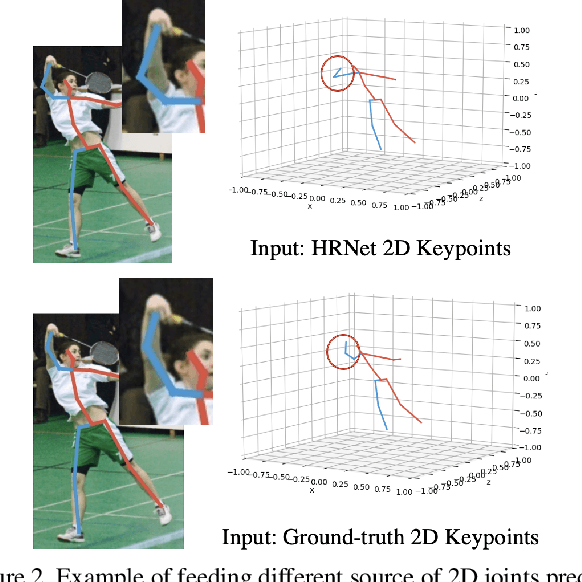

To improve the generalization of 3D human pose estimators, many existing deep learning based models focus on adding different augmentations to training poses. However, data augmentation techniques are limited to the "seen" pose combinations and hard to infer poses with rare "unseen" joint positions. To address this problem, we present CameraPose, a weakly-supervised framework for 3D human pose estimation from a single image, which can not only be applied on 2D-3D pose pairs but also on 2D alone annotations. By adding a camera parameter branch, any in-the-wild 2D annotations can be fed into our pipeline to boost the training diversity and the 3D poses can be implicitly learned by reprojecting back to 2D. Moreover, CameraPose introduces a refinement network module with confidence-guided loss to further improve the quality of noisy 2D keypoints extracted by 2D pose estimators. Experimental results demonstrate that the CameraPose brings in clear improvements on cross-scenario datasets. Notably, it outperforms the baseline method by 3mm on the most challenging dataset 3DPW. In addition, by combining our proposed refinement network module with existing 3D pose estimators, their performance can be improved in cross-scenario evaluation.
Building Hierarchies of Concepts via Crowdsourcing
Aug 01, 2015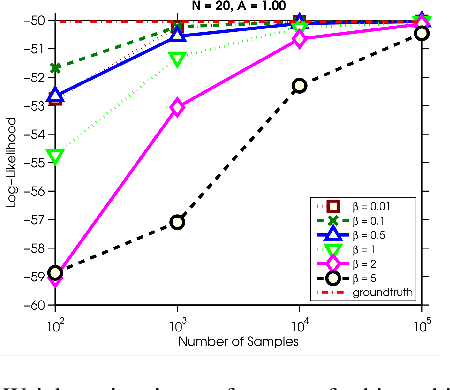
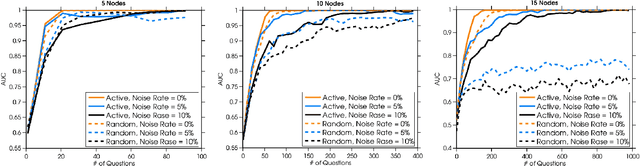

Hierarchies of concepts are useful in many applications from navigation to organization of objects. Usually, a hierarchy is created in a centralized manner by employing a group of domain experts, a time-consuming and expensive process. The experts often design one single hierarchy to best explain the semantic relationships among the concepts, and ignore the natural uncertainty that may exist in the process. In this paper, we propose a crowdsourcing system to build a hierarchy and furthermore capture the underlying uncertainty. Our system maintains a distribution over possible hierarchies and actively selects questions to ask using an information gain criterion. We evaluate our methodology on simulated data and on a set of real world application domains. Experimental results show that our system is robust to noise, efficient in picking questions, cost-effective and builds high quality hierarchies.