 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-based Object Grounding and Robot Grasp Detection with Spatial Reasoning
Sep 09, 2025Enabling robots to grasp objects specified through natural language is essential for effective human-robot interaction, yet it remains a significant challenge. Existing approaches often struggle with open-form language expressions and typically assume unambiguous target objects without duplicates. Moreover, they frequently rely on costly, dense pixel-wise annotations for both object grounding and grasp configuration. We present Attribute-based Object Grounding and Robotic Grasping (OGRG), a novel framework that interprets open-form language expressions and performs spatial reasoning to ground target objects and predict planar grasp poses, even in scenes containing duplicated object instances. We investigate OGRG in two settings: (1) Referring Grasp Synthesis (RGS) under pixel-wise full supervision, and (2) Referring Grasp Affordance (RGA) using weakly supervised learning with only single-pixel grasp annotations. Key contributions include a bi-directional vision-language fusion module and the integration of depth information to enhance geometric reasoning, improving both grounding and grasping performance. Experiment results show that OGRG outperforms strong baselines in tabletop scenes with diverse spatial language instructions. In RGS, it operates at 17.59 FPS on a single NVIDIA RTX 2080 Ti GPU, enabling potential use in closed-loop or multi-object sequential grasping, while delivering superior grounding and grasp prediction accuracy compared to all the baselines considered. Under the weakly supervised RGA setting, OGRG also surpasses baseline grasp-success rates in both simulation and real-robot trials, underscoring the effectiveness of its spatial reasoning design. Project page: https://z.umn.edu/ogrg
POp-GS: Next Best View in 3D-Gaussian Splatting with P-Optimality
Mar 10, 2025In this paper, we present a novel algorithm for quantifying uncertainty and information gained within 3D Gaussian Splatting (3D-GS) through P-Optimality. While 3D-GS has proven to be a useful world model with high-quality rasterizations, it does not natively quantify uncertainty. Quantifying uncertainty in parameters of 3D-GS is necessary to understand the information gained from acquiring new images as in active perception, or identify redundant images which can be removed from memory due to resource constraints in online 3D-GS SLAM. We propose to quantify uncertainty and information gain in 3D-GS by reformulating the problem through the lens of optimal experimental design, which is a classical solution to measuring information gain. By restructuring information quantification of 3D-GS through optimal experimental design, we arrive at multiple solutions, of which T-Optimality and D-Optimality perform the best quantitatively and qualitatively as measured on two popular datasets. Additionally, we propose a block diagonal approximation of the 3D-GS uncertainty, which provides a measure of correlation for computing more accurate information gain, at the expense of a greater computation cost.
Modeling Uncertainty in 3D Gaussian Splatting through Continuous Semantic Splatting
Nov 04, 2024In this paper, we present a novel algorithm for probabilistically updating and rasterizing semantic maps within 3D Gaussian Splatting (3D-GS). Although previous methods have introduced algorithms which learn to rasterize features in 3D-GS for enhanced scene understanding, 3D-GS can fail without warning which presents a challenge for safety-critical robotic applications. To address this gap, we propose a method which advances the literature of continuous semantic mapping from voxels to ellipsoids, combining the precise structure of 3D-GS with the ability to quantify uncertainty of probabilistic robotic maps. Given a set of images, our algorithm performs a probabilistic semantic update directly on the 3D ellipsoids to obtain an expectation and variance through the use of conjugate priors. We also propose a probabilistic rasterization which returns per-pixel segmentation predictions with quantifiable uncertainty. We compare our method with similar probabilistic voxel-based methods to verify our extension to 3D ellipsoids, and perform ablation studies on uncertainty quantification and temporal smoothing.
Correspondence-Free SE(3) Point Cloud Registration in RKHS via Unsupervised Equivariant Learning
Jul 29, 2024This paper introduces a robust unsupervised SE(3) point cloud registration method that operates without requiring point correspondences. The method frames point clouds as functions in a reproducing kernel Hilbert space (RKHS), leveraging SE(3)-equivariant features for direct feature space registration. A novel RKHS distance metric is proposed, offering reliable performance amidst noise, outliers, and asymmetrical data. An unsupervised training approach is introduced to effectively handle limited ground truth data, facilitating adaptation to real datasets. The proposed method outperforms classical and supervised methods in terms of registration accuracy on both synthetic (ModelNet40) and real-world (ETH3D) noisy, outlier-rich datasets. To our best knowledge, this marks the first instance of successful real RGB-D odometry data registration using an equivariant method. The code is available at {https://sites.google.com/view/eccv24-equivalign}
CSCPR: Cross-Source-Context Indoor RGB-D Place Recognition
Jul 24, 2024



We present a new algorithm, Cross-Source-Context Place Recognition (CSCPR), for RGB-D indoor place recognition that integrates global retrieval and reranking into a single end-to-end model. Unlike prior approaches that primarily focus on the RGB domain, CSCPR is designed to handle the RGB-D data. We extend the Context-of-Clusters (CoCs) for handling noisy colorized point clouds and introduce two novel modules for reranking: the Self-Context Cluster (SCC) and Cross Source Context Cluster (CSCC), which enhance feature representation and match query-database pairs based on local features, respectively. We also present two new datasets, ScanNetIPR and ARKitIPR. Our experiments demonstrate that CSCPR significantly outperforms state-of-the-art models on these datasets by at least 36.5% in Recall@1 at ScanNet-PR dataset and 44% in new datasets. Code and datasets will be released.
PoCo: Point Context Cluster for RGBD Indoor Place Recognition
Apr 03, 2024We present a novel end-to-end algorithm (PoCo) for the indoor RGB-D place recognition task, aimed at identifying the most likely match for a given query frame within a reference database. The task presents inherent challenges attributed to the constrained field of view and limited range of perception sensors. We propose a new network architecture, which generalizes the recent Context of Clusters (CoCs) to extract global descriptors directly from the noisy point clouds through end-to-end learning. Moreover, we develop the architecture by integrating both color and geometric modalities into the point features to enhance the global descriptor representation. We conducted evaluations on public datasets ScanNet-PR and ARKit with 807 and 5047 scenarios, respectively. PoCo achieves SOTA performance: on ScanNet-PR, we achieve R@1 of 64.63%, a 5.7% improvement from the best-published result CGis (61.12%); on Arkit, we achieve R@1 of 45.12%, a 13.3% improvement from the best-published result CGis (39.82%). In addition, PoCo shows higher efficiency than CGis in inference time (1.75X-faster), and we demonstrate the effectiveness of PoCo in recognizing places within a real-world laboratory environment.
Tabletop Transparent Scene Reconstruction via Epipolar-Guided Optical Flow with Monocular Depth Completion Prior
Oct 15, 2023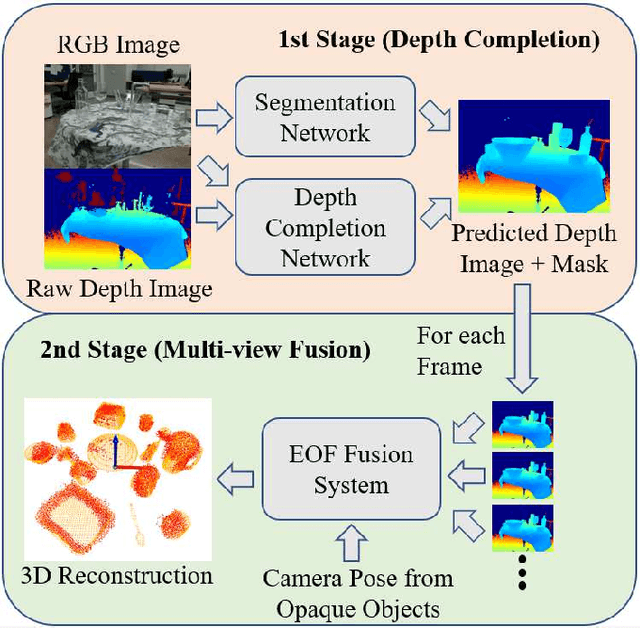


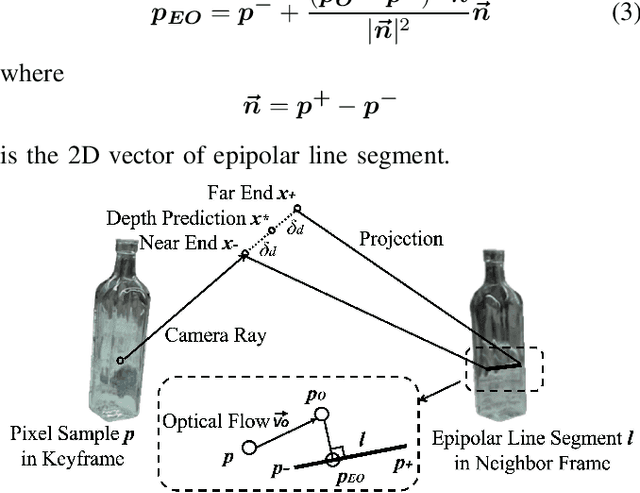
Reconstructing transparent objects using affordable RGB-D cameras is a persistent challenge in robotic perception due to inconsistent appearances across views in the RGB domain and inaccurate depth readings in each single-view. We introduce a two-stage pipeline for reconstructing transparent objects tailored for mobile platforms. In the first stage, off-the-shelf monocular object segmentation and depth completion networks are leveraged to predict the depth of transparent objects, furnishing single-view shape prior. Subsequently, we propose Epipolar-guided Optical Flow (EOF) to fuse several single-view shape priors from the first stage to a cross-view consistent 3D reconstruction given camera poses estimated from opaque part of the scene. Our key innovation lies in EOF which employs boundary-sensitive sampling and epipolar-line constraints into optical flow to accurately establish 2D correspondences across multiple views on transparent objects. Quantitative evaluations demonstrate that our pipeline significantly outperforms baseline methods in 3D reconstruction quality, paving the way for more adept robotic perception and interaction with transparent objects.