 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgetuGEMM: Area-Power-Efficient Temporal Unary GEMM Architecture for Low-Precision Edge AI
Dec 23, 2024General matrix multiplication (GEMM) is a ubiquitous computing kernel/algorithm for data processing in diverse applications, including artificial intelligence (AI) and deep learning (DL). Recent shift towards edge computing has inspired GEMM architectures based on unary computing, which are predominantly stochastic and rate-coded systems. This paper proposes a novel GEMM architecture based on temporal-coding, called tuGEMM, that performs exact computation. We introduce two variants of tuGEMM, serial and parallel, with distinct area/power-latency trade-offs. Post-synthesis Power-Performance-Area (PPA) in 45 nm CMOS are reported for 2-bit, 4-bit, and 8-bit computations. The designs illustrate significant advantages in area-power efficiency over state-of-the-art stochastic unary systems especially at low precisions, e.g. incurring just 0.03 mm^2 and 9 mW for 4 bits, and 0.01 mm^2 and 4 mW for 2 bits. This makes tuGEMM ideal for power constrained mobile and edge devices performing always-on real-time sensory processing.
BaFTA: Backprop-Free Test-Time Adaptation For Zero-Shot Vision-Language Models
Jun 18, 2024



Large-scale pretrained vision-language models like CLIP have demonstrated remarkable zero-shot image classification capabilities across diverse domains. To enhance CLIP's performance while preserving the zero-shot paradigm, various test-time prompt tuning methods have been introduced to refine class embeddings through unsupervised learning objectives during inference. However, these methods often encounter challenges in selecting appropriate learning rates to prevent collapsed training in the absence of validation data during test-time adaptation. In this study, we propose a novel backpropagation-free algorithm BaFTA for test-time adaptation of vision-language models. Instead of fine-tuning text prompts to refine class embeddings, our approach directly estimates class centroids using online clustering within a projected embedding space that aligns text and visual embeddings. We dynamically aggregate predictions from both estimated and original class embeddings, as well as from distinct augmented views, by assessing the reliability of each prediction using R\'enyi Entropy. Through extensive experiments, we demonstrate that BaFTA consistently outperforms state-of-the-art test-time adaptation methods in both effectiveness and efficiency.
ReCLIP: Refine Contrastive Language Image Pre-Training with Source Free Domain Adaptation
Aug 04, 2023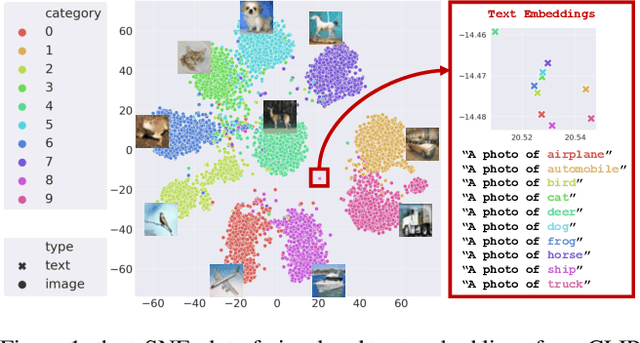
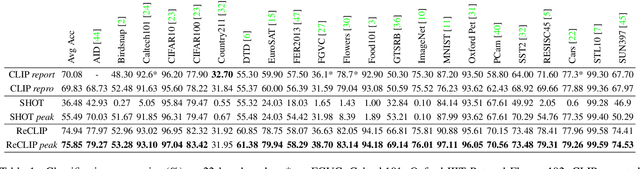
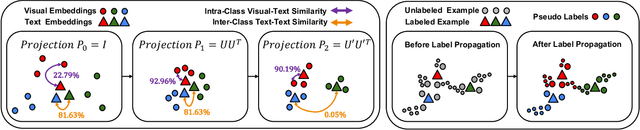
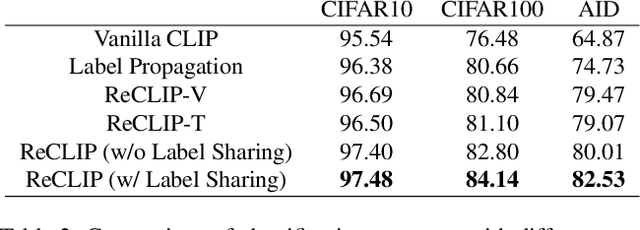
Large-scale Pre-Training Vision-Language Model such as CLIP has demonstrated outstanding performance in zero-shot classification, e.g. achieving 76.3% top-1 accuracy on ImageNet without seeing any example, which leads to potential benefits to many tasks that have no labeled data. However, while applying CLIP to a downstream target domain, the presence of visual and text domain gaps and cross-modality misalignment can greatly impact the model performance. To address such challenges, we propose ReCLIP, the first source-free domain adaptation method for vision-language models, which does not require any source data or target labeled data. ReCLIP first learns a projection space to mitigate the misaligned visual-text embeddings and learns pseudo labels, and then deploys cross-modality self-training with the pseudo labels, to update visual and text encoders, refine labels and reduce domain gaps and misalignments iteratively. With extensive experiments, we demonstrate ReCLIP reduces the average error rate of CLIP from 30.17% to 25.06% on 22 image classification benchmarks.
Greykite: Deploying Flexible Forecasting at Scale at LinkedIn
Jul 15, 2022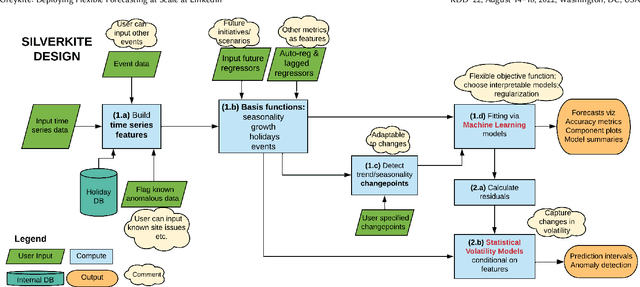
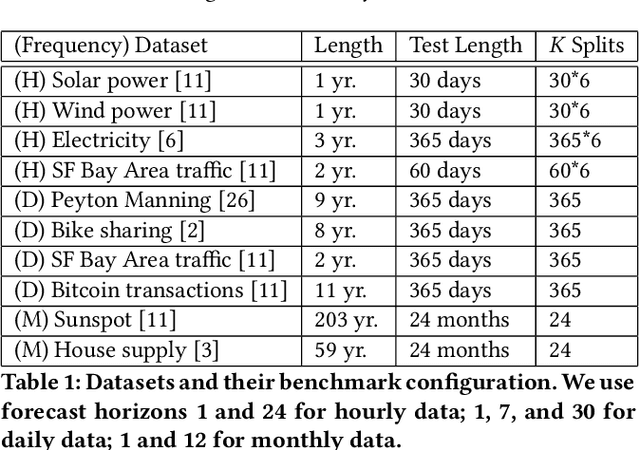
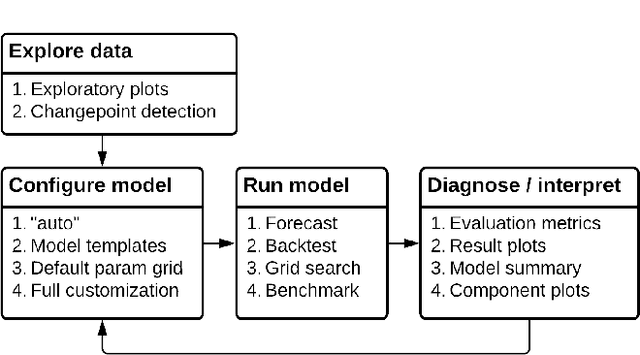
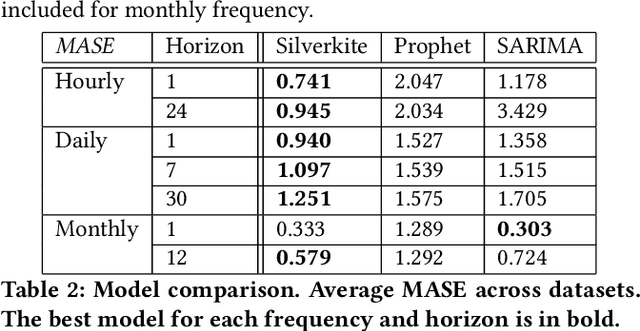
Forecasts help businesses allocate resources and achieve objectives. At LinkedIn, product owners use forecasts to set business targets, track outlook, and monitor health. Engineers use forecasts to efficiently provision hardware. Developing a forecasting solution to meet these needs requires accurate and interpretable forecasts on diverse time series with sub-hourly to quarterly frequencies. We present Greykite, an open-source Python library for forecasting that has been deployed on over twenty use cases at LinkedIn. Its flagship algorithm, Silverkite, provides interpretable, fast, and highly flexible univariate forecasts that capture effects such as time-varying growth and seasonality, autocorrelation, holidays, and regressors. The library enables self-serve accuracy and trust by facilitating data exploration, model configuration, execution, and interpretation. Our benchmark results show excellent out-of-the-box speed and accuracy on datasets from a variety of domains. Over the past two years, Greykite forecasts have been trusted by Finance, Engineering, and Product teams for resource planning and allocation, target setting and progress tracking, anomaly detection and root cause analysis. We expect Greykite to be useful to forecast practitioners with similar applications who need accurate, interpretable forecasts that capture complex dynamics common to time series related to human activity.