 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpsilon*: Privacy Metric for Machine Learning Models
Jul 21, 2023



We introduce Epsilon*, a new privacy metric for measuring the privacy risk of a single model instance prior to, during, or after deployment of privacy mitigation strategies. The metric does not require access to the training data sampling or model training algorithm. Epsilon* is a function of true positive and false positive rates in a hypothesis test used by an adversary in a membership inference attack. We distinguish between quantifying the privacy loss of a trained model instance and quantifying the privacy loss of the training mechanism which produces this model instance. Existing approaches in the privacy auditing literature provide lower bounds for the latter, while our metric provides a lower bound for the former by relying on an (${\epsilon}$,${\delta}$)-type of quantification of the privacy of the trained model instance. We establish a relationship between these lower bounds and show how to implement Epsilon* to avoid numerical and noise amplification instability. We further show in experiments on benchmark public data sets that Epsilon* is sensitive to privacy risk mitigation by training with differential privacy (DP), where the value of Epsilon* is reduced by up to 800% compared to the Epsilon* values of non-DP trained baseline models. This metric allows privacy auditors to be independent of model owners, and enables all decision-makers to visualize the privacy-utility landscape to make informed decisions regarding the trade-offs between model privacy and utility.
Greykite: Deploying Flexible Forecasting at Scale at LinkedIn
Jul 15, 2022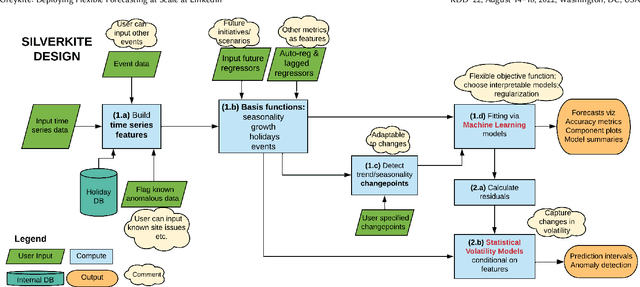
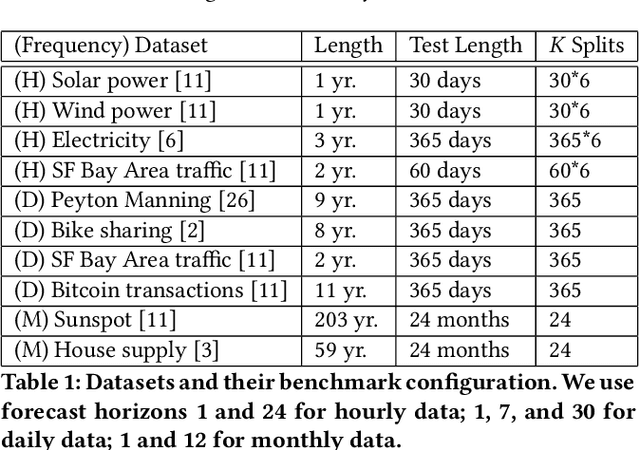
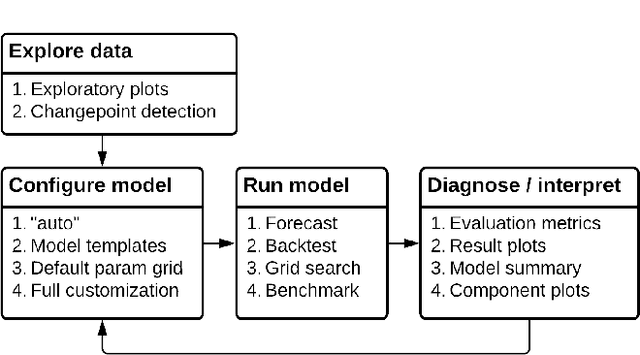
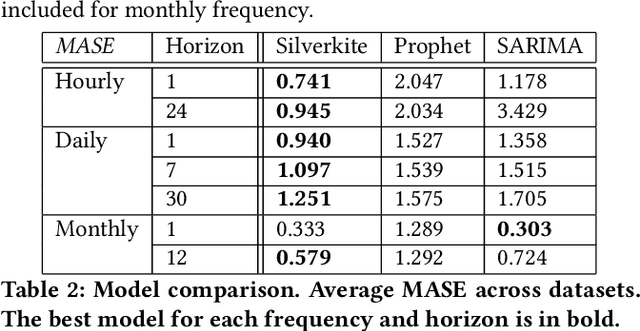
Forecasts help businesses allocate resources and achieve objectives. At LinkedIn, product owners use forecasts to set business targets, track outlook, and monitor health. Engineers use forecasts to efficiently provision hardware. Developing a forecasting solution to meet these needs requires accurate and interpretable forecasts on diverse time series with sub-hourly to quarterly frequencies. We present Greykite, an open-source Python library for forecasting that has been deployed on over twenty use cases at LinkedIn. Its flagship algorithm, Silverkite, provides interpretable, fast, and highly flexible univariate forecasts that capture effects such as time-varying growth and seasonality, autocorrelation, holidays, and regressors. The library enables self-serve accuracy and trust by facilitating data exploration, model configuration, execution, and interpretation. Our benchmark results show excellent out-of-the-box speed and accuracy on datasets from a variety of domains. Over the past two years, Greykite forecasts have been trusted by Finance, Engineering, and Product teams for resource planning and allocation, target setting and progress tracking, anomaly detection and root cause analysis. We expect Greykite to be useful to forecast practitioners with similar applications who need accurate, interpretable forecasts that capture complex dynamics common to time series related to human activity.