 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpsilon*: Privacy Metric for Machine Learning Models
Jul 21, 2023



We introduce Epsilon*, a new privacy metric for measuring the privacy risk of a single model instance prior to, during, or after deployment of privacy mitigation strategies. The metric does not require access to the training data sampling or model training algorithm. Epsilon* is a function of true positive and false positive rates in a hypothesis test used by an adversary in a membership inference attack. We distinguish between quantifying the privacy loss of a trained model instance and quantifying the privacy loss of the training mechanism which produces this model instance. Existing approaches in the privacy auditing literature provide lower bounds for the latter, while our metric provides a lower bound for the former by relying on an (${\epsilon}$,${\delta}$)-type of quantification of the privacy of the trained model instance. We establish a relationship between these lower bounds and show how to implement Epsilon* to avoid numerical and noise amplification instability. We further show in experiments on benchmark public data sets that Epsilon* is sensitive to privacy risk mitigation by training with differential privacy (DP), where the value of Epsilon* is reduced by up to 800% compared to the Epsilon* values of non-DP trained baseline models. This metric allows privacy auditors to be independent of model owners, and enables all decision-makers to visualize the privacy-utility landscape to make informed decisions regarding the trade-offs between model privacy and utility.
Unlocking Sales Growth: Account Prioritization Engine with Explainable AI
Jun 12, 2023



B2B sales requires effective prediction of customer growth, identification of upsell potential, and mitigation of churn risks. LinkedIn sales representatives traditionally relied on intuition and fragmented data signals to assess customer performance. This resulted in significant time investment in data understanding as well as strategy formulation and under-investment in active selling. To overcome this challenge, we developed a data product called Account Prioritizer, an intelligent sales account prioritization engine. It uses machine learning recommendation models and integrated account-level explanation algorithms within the sales CRM to automate the manual process of sales book prioritization. A successful A/B test demonstrated that the Account Prioritizer generated a substantial +8.08% increase in renewal bookings for the LinkedIn Business.
Confounder Analysis in Measuring Representation in Product Funnels
Jun 07, 2022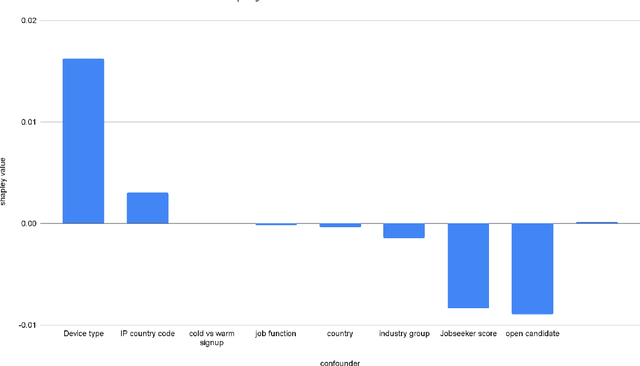
This paper discusses an application of Shapley values in the causal inference field, specifically on how to select the top confounder variables for coarsened exact matching method in a scalable way. We use a dataset from an observational experiment involving LinkedIn members as a use case to test its applicability, and show that Shapley values are highly informational and can be leveraged for its robust importance-ranking capability.
Fast TreeSHAP: Accelerating SHAP Value Computation for Trees
Sep 20, 2021
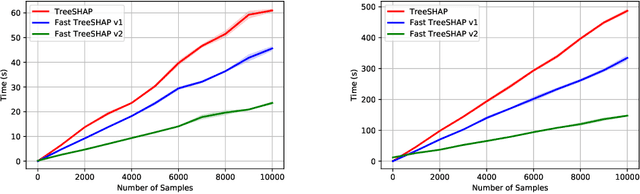


SHAP (SHapley Additive exPlanation) values are one of the leading tools for interpreting machine learning models, with strong theoretical guarantees (consistency, local accuracy) and a wide availability of implementations and use cases. Even though computing SHAP values takes exponential time in general, TreeSHAP takes polynomial time on tree-based models. While the speedup is significant, TreeSHAP can still dominate the computation time of industry-level machine learning solutions on datasets with millions or more entries, causing delays in post-hoc model diagnosis and interpretation service. In this paper we present two new algorithms, Fast TreeSHAP v1 and v2, designed to improve the computational efficiency of TreeSHAP for large datasets. We empirically find that Fast TreeSHAP v1 is 1.5x faster than TreeSHAP while keeping the memory cost unchanged. Similarly, Fast TreeSHAP v2 is 2.5x faster than TreeSHAP, at the cost of a slightly higher memory usage, thanks to the pre-computation of expensive TreeSHAP steps. We also show that Fast TreeSHAP v2 is well-suited for multi-time model interpretations, resulting in as high as 3x faster explanation of newly incoming samples.
Intellige: A User-Facing Model Explainer for Narrative Explanations
May 27, 2021
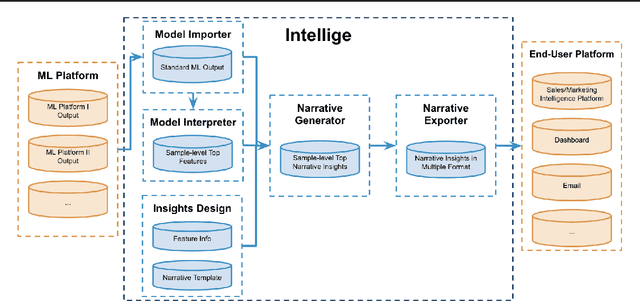

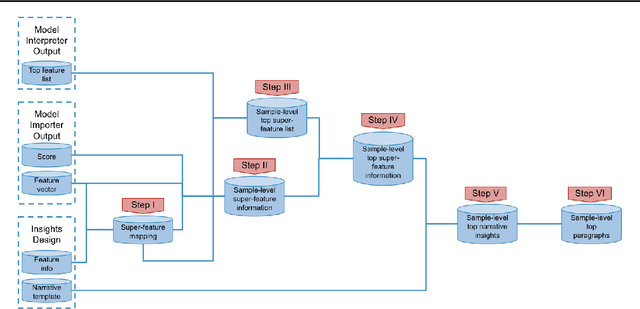
Predictive machine learning models often lack interpretability, resulting in low trust from model end users despite having high predictive performance. While many model interpretation approaches return top important features to help interpret model predictions, these top features may not be well-organized or intuitive to end users, which limits model adoption rates. In this paper, we propose Intellige, a user-facing model explainer that creates user-digestible interpretations and insights reflecting the rationale behind model predictions. Intellige builds an end-to-end pipeline from machine learning platforms to end user platforms, and provides users with an interface for implementing model interpretation approaches and for customizing narrative insights. Intellige is a platform consisting of four components: Model Importer, Model Interpreter, Narrative Generator, and Narrative Exporter. We describe these components, and then demonstrate the effectiveness of Intellige through use cases at LinkedIn. Quantitative performance analyses indicate that Intellige's narrative insights lead to lifts in adoption rates of predictive model recommendations, as well as to increases in downstream key metrics such as revenue when compared to previous approaches, while qualitative analyses indicate positive feedback from end users.
Estimating Time-Varying Graphical Models
Apr 11, 2018
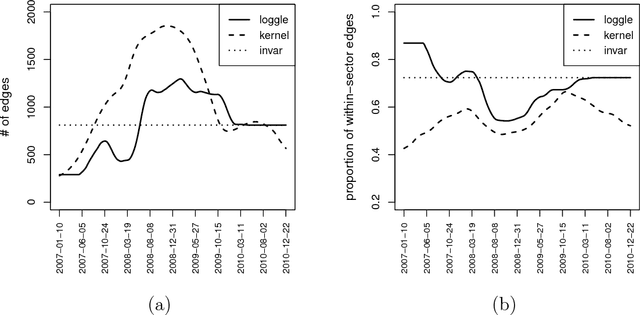


In this paper, we study time-varying graphical models based on data measured over a temporal grid. Such models are motivated by the needs to describe and understand evolving interacting relationships among a set of random variables in many real applications, for instance the study of how stocks interact with each other and how such interactions change over time. We propose a new model, LOcal Group Graphical Lasso Estimation (loggle), under the assumption that the graph topology changes gradually over time. Specifically, loggle uses a novel local group-lasso type penalty to efficiently incorporate information from neighboring time points and to impose structural smoothness of the graphs. We implement an ADMM based algorithm to fit the loggle model. This algorithm utilizes blockwise fast computation and pseudo-likelihood approximation to improve computational efficiency. An R package loggle has also been developed. We evaluate the performance of loggle by simulation experiments. We also apply loggle to S&P 500 stock price data and demonstrate that loggle is able to reveal the interacting relationships among stocks and among industrial sectors in a time period that covers the recent global financial crisis.