 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast TreeSHAP: Accelerating SHAP Value Computation for Trees
Paper and Code

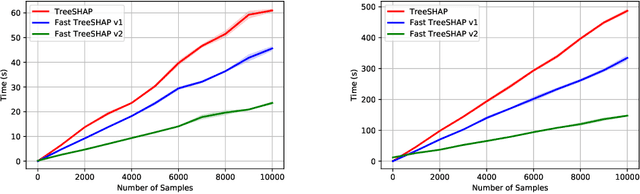


SHAP (SHapley Additive exPlanation) values are one of the leading tools for interpreting machine learning models, with strong theoretical guarantees (consistency, local accuracy) and a wide availability of implementations and use cases. Even though computing SHAP values takes exponential time in general, TreeSHAP takes polynomial time on tree-based models. While the speedup is significant, TreeSHAP can still dominate the computation time of industry-level machine learning solutions on datasets with millions or more entries, causing delays in post-hoc model diagnosis and interpretation service. In this paper we present two new algorithms, Fast TreeSHAP v1 and v2, designed to improve the computational efficiency of TreeSHAP for large datasets. We empirically find that Fast TreeSHAP v1 is 1.5x faster than TreeSHAP while keeping the memory cost unchanged. Similarly, Fast TreeSHAP v2 is 2.5x faster than TreeSHAP, at the cost of a slightly higher memory usage, thanks to the pre-computation of expensive TreeSHAP steps. We also show that Fast TreeSHAP v2 is well-suited for multi-time model interpretations, resulting in as high as 3x faster explanation of newly incoming samples.