 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Radiance and Gaze Fields for Visual Attention Modeling in 3D Environments
Mar 10, 2025



We introduce Neural Radiance and Gaze Fields (NeRGs) as a novel approach for representing visual attention patterns in 3D scenes. Our system renders a 2D view of a 3D scene with a pre-trained Neural Radiance Field (NeRF) and visualizes the gaze field for arbitrary observer positions, which may be decoupled from the render camera perspective. We achieve this by augmenting a standard NeRF with an additional neural network that models the gaze probability distribution. The output of a NeRG is a rendered image of the scene viewed from the camera perspective and a pixel-wise salience map representing conditional probability that an observer fixates on a given surface within the 3D scene as visible in the rendered image. Much like how NeRFs perform novel view synthesis, NeRGs enable the reconstruction of gaze patterns from arbitrary perspectives within complex 3D scenes. To ensure consistent gaze reconstructions, we constrain gaze prediction on the 3D structure of the scene and model gaze occlusion due to intervening surfaces when the observer's viewpoint is decoupled from the rendering camera. For training, we leverage ground truth head pose data from skeleton tracking data or predictions from 2D salience models. We demonstrate the effectiveness of NeRGs in a real-world convenience store setting, where head pose tracking data is available.
Adapting Pretrained Networks for Image Quality Assessment on High Dynamic Range Displays
May 01, 2024
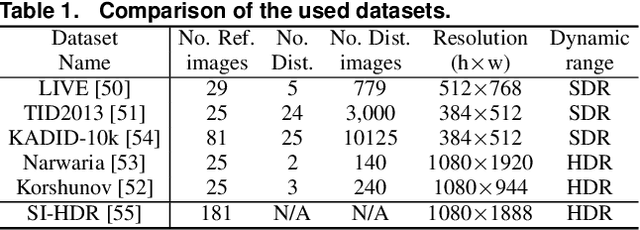


Conventional image quality metrics (IQMs), such as PSNR and SSIM, are designed for perceptually uniform gamma-encoded pixel values and cannot be directly applied to perceptually non-uniform linear high-dynamic-range (HDR) colors. Similarly, most of the available datasets consist of standard-dynamic-range (SDR) images collected in standard and possibly uncontrolled viewing conditions. Popular pre-trained neural networks are likewise intended for SDR inputs, restricting their direct application to HDR content. On the other hand, training HDR models from scratch is challenging due to limited available HDR data. In this work, we explore more effective approaches for training deep learning-based models for image quality assessment (IQA) on HDR data. We leverage networks pre-trained on SDR data (source domain) and re-target these models to HDR (target domain) with additional fine-tuning and domain adaptation. We validate our methods on the available HDR IQA datasets, demonstrating that models trained with our combined recipe outperform previous baselines, converge much quicker, and reliably generalize to HDR inputs.
Learning Neural Implicit Representations with Surface Signal Parameterizations
Nov 01, 2022



Neural implicit surface representations have recently emerged as popular alternative to explicit 3D object encodings, such as polygonal meshes, tabulated points, or voxels. While significant work has improved the geometric fidelity of these representations, much less attention is given to their final appearance. Traditional explicit object representations commonly couple the 3D shape data with auxiliary surface-mapped image data, such as diffuse color textures and fine-scale geometric details in normal maps that typically require a mapping of the 3D surface onto a plane, i.e., a surface parameterization; implicit representations, on the other hand, cannot be easily textured due to lack of configurable surface parameterization. Inspired by this digital content authoring methodology, we design a neural network architecture that implicitly encodes the underlying surface parameterization suitable for appearance data. As such, our model remains compatible with existing mesh-based digital content with appearance data. Motivated by recent work that overfits compact networks to individual 3D objects, we present a new weight-encoded neural implicit representation that extends the capability of neural implicit surfaces to enable various common and important applications of texture mapping. Our method outperforms reasonable baselines and state-of-the-art alternatives.
VTAMIQ: Transformers for Attention Modulated Image Quality Assessment
Oct 04, 2021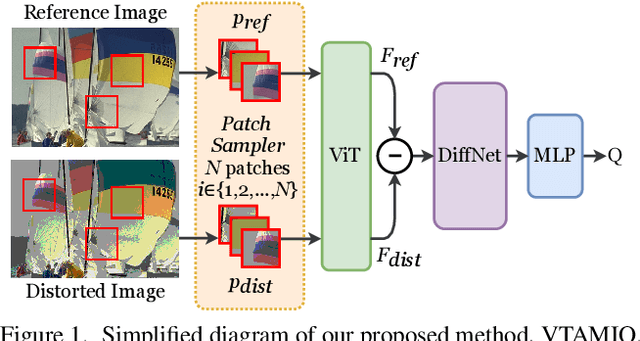


Following the major successes of self-attention and Transformers for image analysis, we investigate the use of such attention mechanisms in the context of Image Quality Assessment (IQA) and propose a novel full-reference IQA method, Vision Transformer for Attention Modulated Image Quality (VTAMIQ). Our method achieves competitive or state-of-the-art performance on the existing IQA datasets and significantly outperforms previous metrics in cross-database evaluations. Most patch-wise IQA methods treat each patch independently; this partially discards global information and limits the ability to model long-distance interactions. We avoid this problem altogether by employing a transformer to encode a sequence of patches as a single global representation, which by design considers interdependencies between patches. We rely on various attention mechanisms -- first with self-attention within the Transformer, and second with channel attention within our difference modulation network -- specifically to reveal and enhance the more salient features throughout our architecture. With large-scale pre-training for both classification and IQA tasks, VTAMIQ generalizes well to unseen sets of images and distortions, further demonstrating the strength of transformer-based networks for vision modelling.