 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo4OOD: Rethinking Egocentric Video Domain Generalization via Covariate Shift Scoring
Jan 21, 2026Egocentric video action recognition under domain shifts remains challenging due to large intra-class spatio-temporal variability, long-tailed feature distributions, and strong correlations between actions and environments. Existing benchmarks for egocentric domain generalization often conflate covariate shifts with concept shifts, making it difficult to reliably evaluate a model's ability to generalize across input distributions. To address this limitation, we introduce Ego4OOD, a domain generalization benchmark derived from Ego4D that emphasizes measurable covariate diversity while reducing concept shift through semantically coherent, moment-level action categories. Ego4OOD spans eight geographically distinct domains and is accompanied by a clustering-based covariate shift metric that provides a quantitative proxy for domain difficulty. We further leverage a one-vs-all binary training objective that decomposes multi-class action recognition into independent binary classification tasks. This formulation is particularly well-suited for covariate shift by reducing interference between visually similar classes under feature distribution shift. Using this formulation, we show that a lightweight two-layer fully connected network achieves performance competitive with state-of-the-art egocentric domain generalization methods on both Argo1M and Ego4OOD, despite using fewer parameters and no additional modalities. Our empirical analysis demonstrates a clear relationship between measured covariate shift and recognition performance, highlighting the importance of controlled benchmarks and quantitative domain characterization for studying out-of-distribution generalization in egocentric video.
Adapting Pretrained Networks for Image Quality Assessment on High Dynamic Range Displays
May 01, 2024
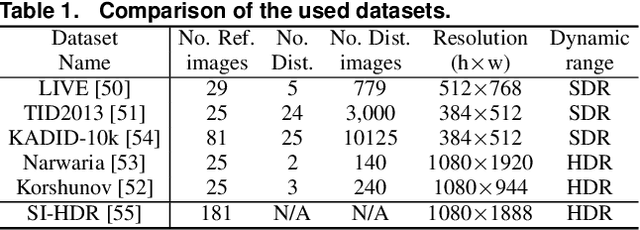


Conventional image quality metrics (IQMs), such as PSNR and SSIM, are designed for perceptually uniform gamma-encoded pixel values and cannot be directly applied to perceptually non-uniform linear high-dynamic-range (HDR) colors. Similarly, most of the available datasets consist of standard-dynamic-range (SDR) images collected in standard and possibly uncontrolled viewing conditions. Popular pre-trained neural networks are likewise intended for SDR inputs, restricting their direct application to HDR content. On the other hand, training HDR models from scratch is challenging due to limited available HDR data. In this work, we explore more effective approaches for training deep learning-based models for image quality assessment (IQA) on HDR data. We leverage networks pre-trained on SDR data (source domain) and re-target these models to HDR (target domain) with additional fine-tuning and domain adaptation. We validate our methods on the available HDR IQA datasets, demonstrating that models trained with our combined recipe outperform previous baselines, converge much quicker, and reliably generalize to HDR inputs.
VTAMIQ: Transformers for Attention Modulated Image Quality Assessment
Oct 04, 2021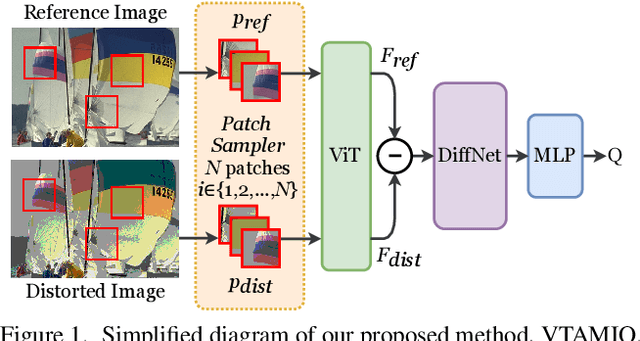
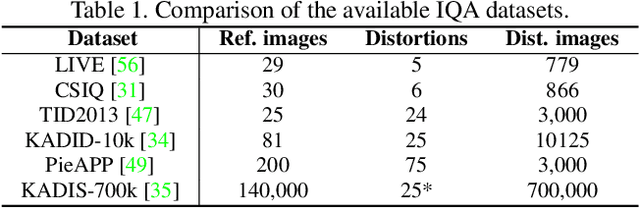


Following the major successes of self-attention and Transformers for image analysis, we investigate the use of such attention mechanisms in the context of Image Quality Assessment (IQA) and propose a novel full-reference IQA method, Vision Transformer for Attention Modulated Image Quality (VTAMIQ). Our method achieves competitive or state-of-the-art performance on the existing IQA datasets and significantly outperforms previous metrics in cross-database evaluations. Most patch-wise IQA methods treat each patch independently; this partially discards global information and limits the ability to model long-distance interactions. We avoid this problem altogether by employing a transformer to encode a sequence of patches as a single global representation, which by design considers interdependencies between patches. We rely on various attention mechanisms -- first with self-attention within the Transformer, and second with channel attention within our difference modulation network -- specifically to reveal and enhance the more salient features throughout our architecture. With large-scale pre-training for both classification and IQA tasks, VTAMIQ generalizes well to unseen sets of images and distortions, further demonstrating the strength of transformer-based networks for vision modelling.