 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline,Target-Free LiDAR-Camera Extrinsic Calibration via Cross-Modal Mask Matching
Paper and Code
Apr 28, 2024
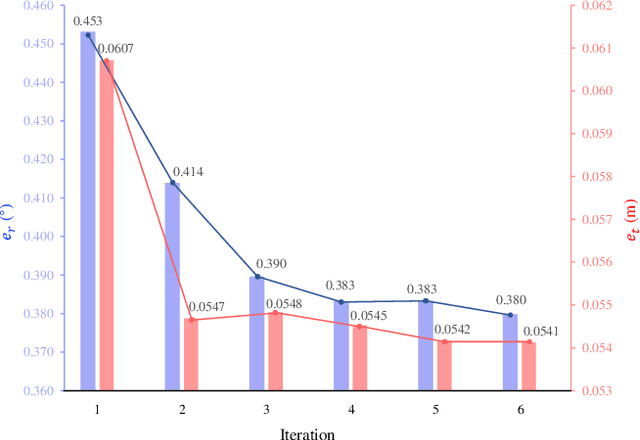
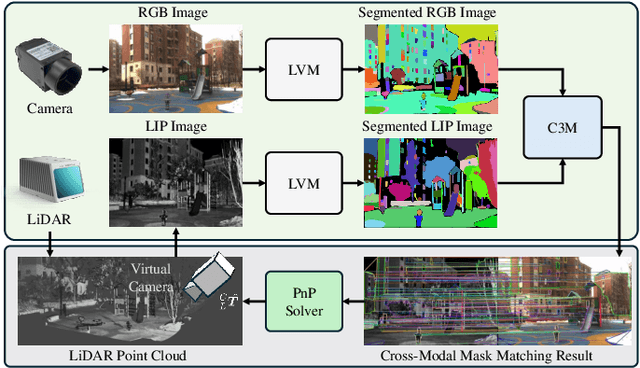
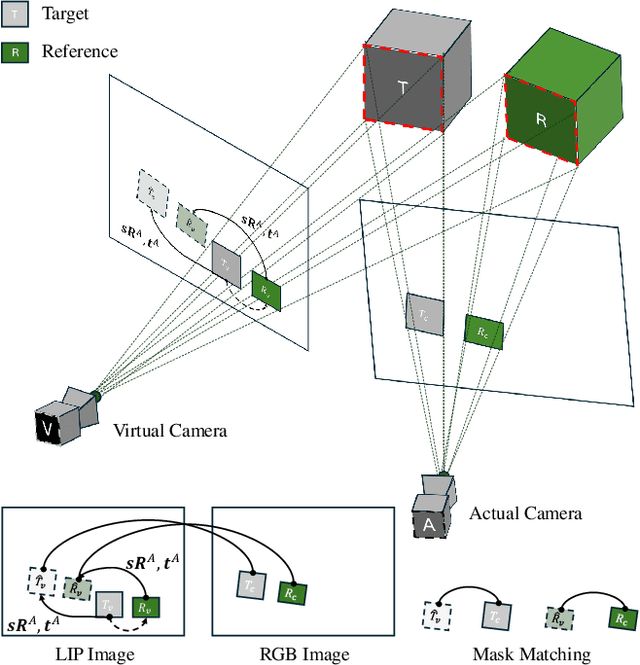
LiDAR-camera extrinsic calibration (LCEC) is crucial for data fusion in intelligent vehicles. Offline, target-based approaches have long been the preferred choice in this field. However, they often demonstrate poor adaptability to real-world environments. This is largely because extrinsic parameters may change significantly due to moderate shocks or during extended operations in environments with vibrations. In contrast, online, target-free approaches provide greater adaptability yet typically lack robustness, primarily due to the challenges in cross-modal feature matching. Therefore, in this article, we unleash the full potential of large vision models (LVMs), which are emerging as a significant trend in the fields of computer vision and robotics, especially for embodied artificial intelligence, to achieve robust and accurate online, target-free LCEC across a variety of challenging scenarios. Our main contributions are threefold: we introduce a novel framework known as MIAS-LCEC, provide an open-source versatile calibration toolbox with an interactive visualization interface, and publish three real-world datasets captured from various indoor and outdoor environments. The cornerstone of our framework and toolbox is the cross-modal mask matching (C3M) algorithm, developed based on a state-of-the-art (SoTA) LVM and capable of generating sufficient and reliable matches. Extensive experiments conducted on these real-world datasets demonstrate the robustness of our approach and its superior performance compared to SoTA methods, particularly for the solid-state LiDARs with super-wide fields of view.