 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Large Language Model Good at Triple Set Prediction? An Empirical Study
Paper and Code
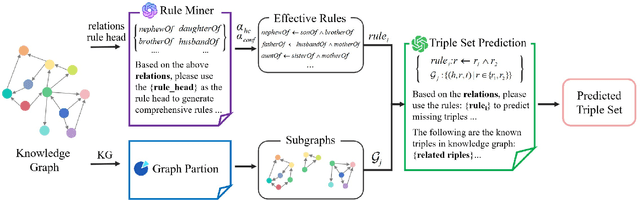



The core of the Knowledge Graph Completion (KGC) task is to predict and complete the missing relations or nodes in a KG. Common KGC tasks are mostly about inferring unknown elements with one or two elements being known in a triple. In comparison, the Triple Set Prediction (TSP) task is a more realistic knowledge graph completion task. It aims to predict all elements of unknown triples based on the information from known triples. In recent years, large language models (LLMs) have exhibited significant advancements in language comprehension, demonstrating considerable potential for KGC tasks. However, the potential of LLM on the TSP task has not yet to be investigated. Thus in this paper we proposed a new framework to explore the strengths and limitations of LLM in the TSP task. Specifically, the framework consists of LLM-based rule mining and LLM-based triple set prediction. The relation list of KG embedded within rich semantic information is first leveraged to prompt LLM in the generation of rules. This process is both efficient and independent of statistical information, making it easier to mine effective and realistic rules. For each subgraph, the specified rule is applied in conjunction with the relevant triples within that subgraph to guide the LLM in predicting the missing triples. Subsequently, the predictions from all subgraphs are consolidated to derive the complete set of predicted triples on KG. Finally, the method is evaluated on the relatively complete CFamily dataset. The experimental results indicate that when LLMs are required to adhere to a large amount of factual knowledge to predict missing triples, significant hallucinations occurs, leading to a noticeable decline in performance. To further explore the causes of this phenomenon, this paper presents a comprehensive analysis supported by a detailed case study.