 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaoCache: Structure-Maintained Video Generation Acceleration
Aug 12, 2025Existing cache-based acceleration methods for video diffusion models primarily skip early or mid denoising steps, which often leads to structural discrepancies relative to full-timestep generation and can hinder instruction following and character consistency. We present TaoCache, a training-free, plug-and-play caching strategy that, instead of residual-based caching, adopts a fixed-point perspective to predict the model's noise output and is specifically effective in late denoising stages. By calibrating cosine similarities and norm ratios of consecutive noise deltas, TaoCache preserves high-resolution structure while enabling aggressive skipping. The approach is orthogonal to complementary accelerations such as Pyramid Attention Broadcast (PAB) and TeaCache, and it integrates seamlessly into DiT-based frameworks. Across Latte-1, OpenSora-Plan v110, and Wan2.1, TaoCache attains substantially higher visual quality (LPIPS, SSIM, PSNR) than prior caching methods under the same speedups.
Learning Image Deraining Transformer Network with Dynamic Dual Self-Attention
Aug 15, 2023
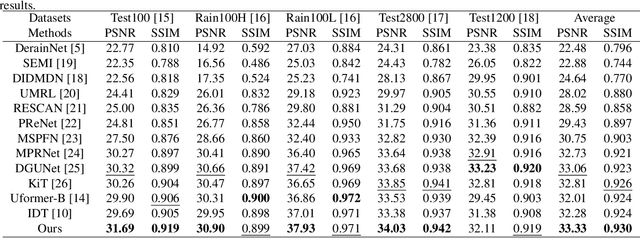
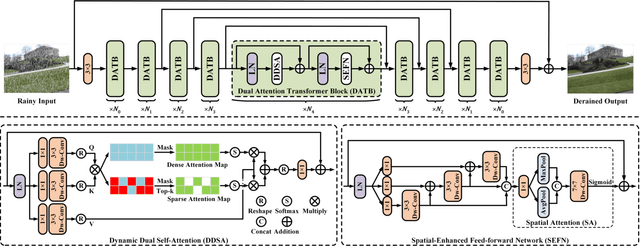

Recently, Transformer-based architecture has been introduced into single image deraining task due to its advantage in modeling non-local information. However, existing approaches tend to integrate global features based on a dense self-attention strategy since it tend to uses all similarities of the tokens between the queries and keys. In fact, this strategy leads to ignoring the most relevant information and inducing blurry effect by the irrelevant representations during the feature aggregation. To this end, this paper proposes an effective image deraining Transformer with dynamic dual self-attention (DDSA), which combines both dense and sparse attention strategies to better facilitate clear image reconstruction. Specifically, we only select the most useful similarity values based on top-k approximate calculation to achieve sparse attention. In addition, we also develop a novel spatial-enhanced feed-forward network (SEFN) to further obtain a more accurate representation for achieving high-quality derained results. Extensive experiments on benchmark datasets demonstrate the effectiveness of our proposed method.
Unpaired Deep Image Dehazing Using Contrastive Disentanglement Learning
Mar 15, 2022
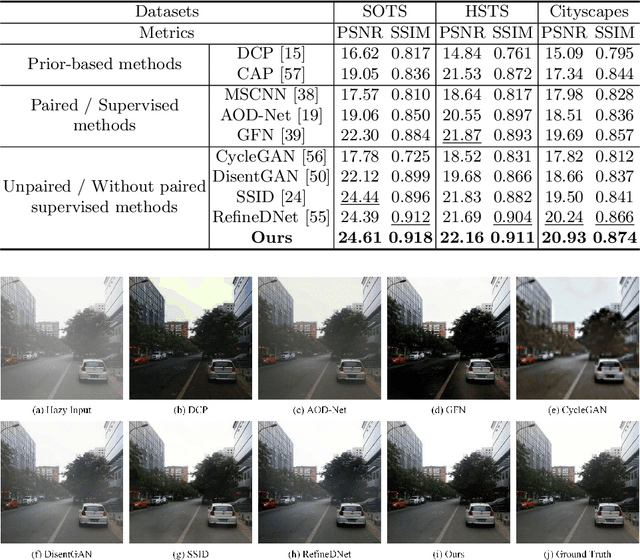
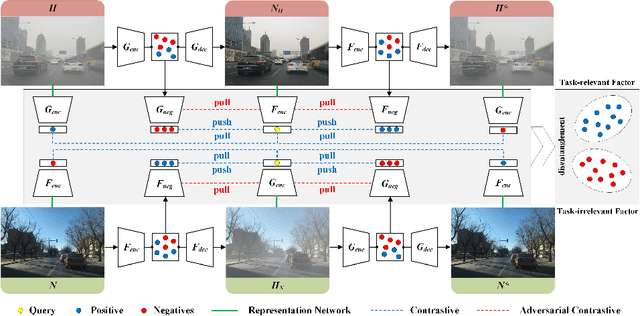
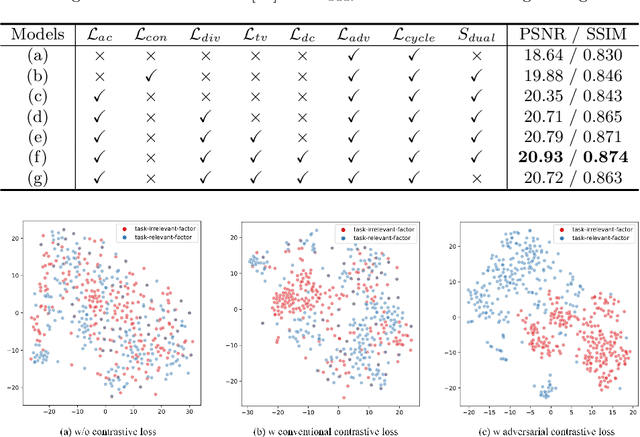
We present an effective unpaired learning based image dehazing network from an unpaired set of clear and hazy images. This paper provides a new perspective to treat image dehazing as a two-class separated factor disentanglement task, i.e, the task-relevant factor of clear image reconstruction and the task-irrelevant factor of haze-relevant distribution. To achieve the disentanglement of these two-class factors in deep feature space, contrastive learning is introduced into a CycleGAN framework to learn disentangled representations by guiding the generated images to be associated with latent factors. With such formulation, the proposed contrastive disentangled dehazing method (CDD-GAN) first develops negative generators to cooperate with the encoder network to update alternately, so as to produce a queue of challenging negative adversaries. Then these negative adversaries are trained end-to-end together with the backbone representation network to enhance the discriminative information and promote factor disentanglement performance by maximizing the adversarial contrastive loss. During the training, we further show that hard negative examples can suppress the task-irrelevant factors and unpaired clear exemples can enhance the task-relevant factors, in order to better facilitate haze removal and help image restoration. Extensive experiments on both synthetic and real-world datasets demonstrate that our method performs favorably against existing state-of-the-art unpaired dehazing approaches.