 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Image Deraining Transformer Network with Dynamic Dual Self-Attention
Paper and Code
Aug 15, 2023
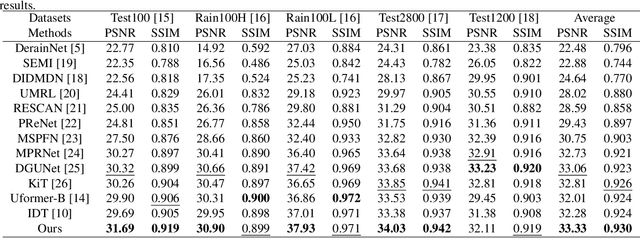
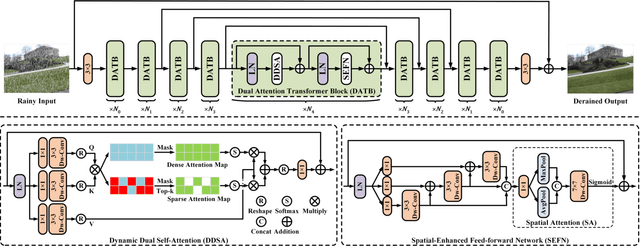

Recently, Transformer-based architecture has been introduced into single image deraining task due to its advantage in modeling non-local information. However, existing approaches tend to integrate global features based on a dense self-attention strategy since it tend to uses all similarities of the tokens between the queries and keys. In fact, this strategy leads to ignoring the most relevant information and inducing blurry effect by the irrelevant representations during the feature aggregation. To this end, this paper proposes an effective image deraining Transformer with dynamic dual self-attention (DDSA), which combines both dense and sparse attention strategies to better facilitate clear image reconstruction. Specifically, we only select the most useful similarity values based on top-k approximate calculation to achieve sparse attention. In addition, we also develop a novel spatial-enhanced feed-forward network (SEFN) to further obtain a more accurate representation for achieving high-quality derained results. Extensive experiments on benchmark datasets demonstrate the effectiveness of our proposed method.