 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeloEdit: Training-Free Consistent and Continuous Instruction-Based Image Editing via Velocity Field Decomposition
Mar 11, 2026Instruction-based image editing aims to modify source content according to textual instructions. However, existing methods built upon flow matching often struggle to maintain consistency in non-edited regions due to denoising-induced reconstruction errors that cause drift in preserved content. Moreover, they typically lack fine-grained control over edit strength. To address these limitations, we propose VeloEdit, a training-free method that enables highly consistent and continuously controllable editing. VeloEdit dynamically identifies editing regions by quantifying the discrepancy between the velocity fields responsible for preserving source content and those driving the desired edits. Based on this partition, we enforce consistency in preservation regions by substituting the editing velocity with the source-restoring velocity, while enabling continuous modulation of edit intensity in target regions via velocity interpolation. Unlike prior works that rely on complex attention manipulation or auxiliary trainable modules, VeloEdit operates directly on the velocity fields. Extensive experiments on Flux.1 Kontext and Qwen-Image-Edit demonstrate that VeloEdit improves visual consistency and editing continuity with negligible additional computational cost. Code is available at https://github.com/xmulzq/VeloEdit.
Enhancing Boundary Segmentation for Topological Accuracy with Skeleton-based Methods
Apr 29, 2024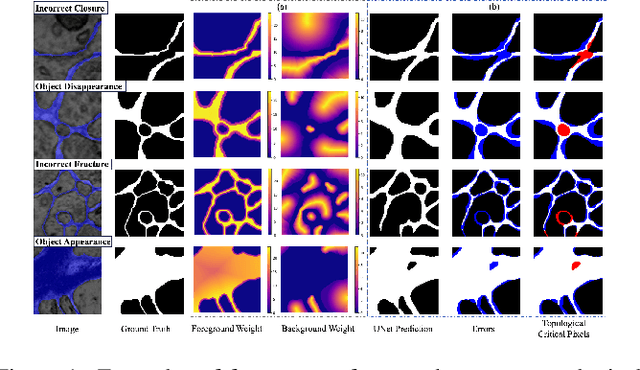
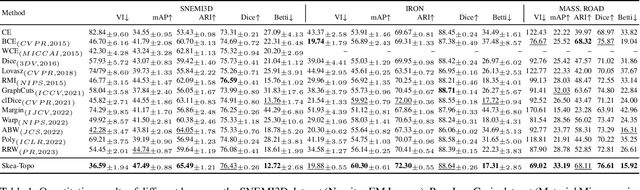
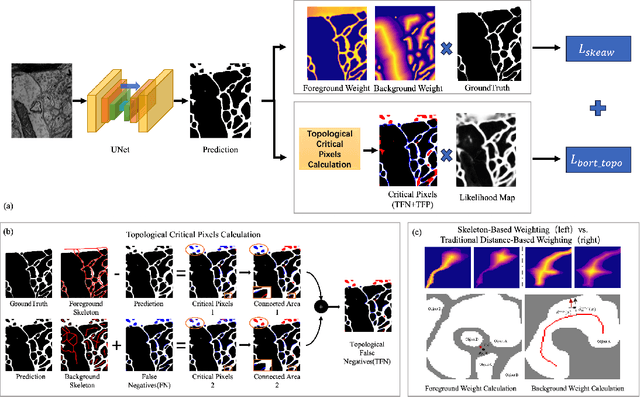

Topological consistency plays a crucial role in the task of boundary segmentation for reticular images, such as cell membrane segmentation in neuron electron microscopic images, grain boundary segmentation in material microscopic images and road segmentation in aerial images. In these fields, topological changes in segmentation results have a serious impact on the downstream tasks, which can even exceed the misalignment of the boundary itself. To enhance the topology accuracy in segmentation results, we propose the Skea-Topo Aware loss, which is a novel loss function that takes into account the shape of each object and topological significance of the pixels. It consists of two components. First, the skeleton-aware weighted loss improves the segmentation accuracy by better modeling the object geometry with skeletons. Second, a boundary rectified term effectively identifies and emphasizes topological critical pixels in the prediction errors using both foreground and background skeletons in the ground truth and predictions. Experiments prove that our method improves topological consistency by up to 7 points in VI compared to 13 state-of-art methods, based on objective and subjective assessments across three different boundary segmentation datasets. The code is available at https://github.com/clovermini/Skea_topo.
Aspect-based Sentiment Classification with Sequential Cross-modal Semantic Graph
Aug 19, 2022
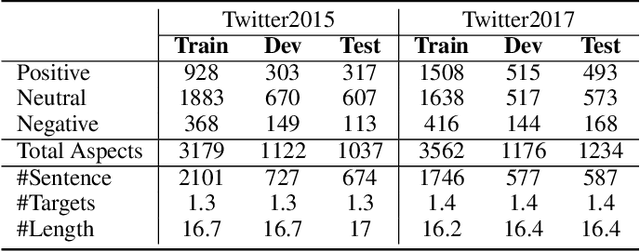
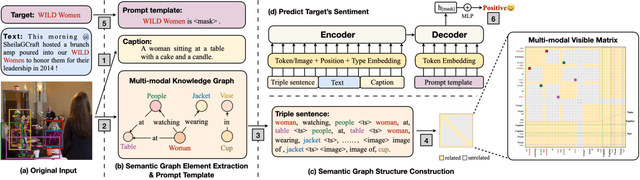
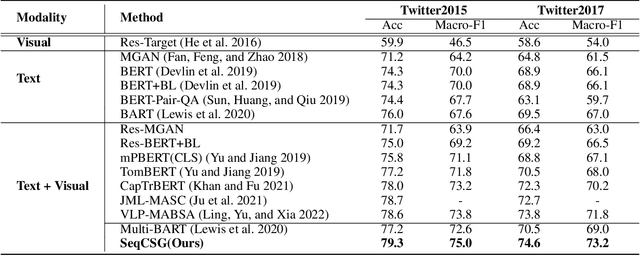
Multi-modal aspect-based sentiment classification (MABSC) is an emerging classification task that aims to classify the sentiment of a given target such as a mentioned entity in data with different modalities. In typical multi-modal data with text and image, previous approaches do not make full use of the fine-grained semantics of the image, especially in conjunction with the semantics of the text and do not fully consider modeling the relationship between fine-grained image information and target, which leads to insufficient use of image and inadequate to identify fine-grained aspects and opinions. To tackle these limitations, we propose a new framework SeqCSG including a method to construct sequential cross-modal semantic graphs and an encoder-decoder model. Specifically, we extract fine-grained information from the original image, image caption, and scene graph, and regard them as elements of the cross-modal semantic graph as well as tokens from texts. The cross-modal semantic graph is represented as a sequence with a multi-modal visible matrix indicating relationships between elements. In order to effectively utilize the cross-modal semantic graph, we propose an encoder-decoder method with a target prompt template. Experimental results show that our approach outperforms existing methods and achieves the state-of-the-art on two standard datasets MABSC. Further analysis demonstrates the effectiveness of each component and our model can implicitly learn the correlation between the target and fine-grained information of the image.