 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Scaling of Policy Constraints for Offline Reinforcement Learning
Aug 27, 2025Offline reinforcement learning (RL) enables learning effective policies from fixed datasets without any environment interaction. Existing methods typically employ policy constraints to mitigate the distribution shift encountered during offline RL training. However, because the scale of the constraints varies across tasks and datasets of differing quality, existing methods must meticulously tune hyperparameters to match each dataset, which is time-consuming and often impractical. We propose Adaptive Scaling of Policy Constraints (ASPC), a second-order differentiable framework that dynamically balances RL and behavior cloning (BC) during training. We theoretically analyze its performance improvement guarantee. In experiments on 39 datasets across four D4RL domains, ASPC using a single hyperparameter configuration outperforms other adaptive constraint methods and state-of-the-art offline RL algorithms that require per-dataset tuning while incurring only minimal computational overhead. The code will be released at https://github.com/Colin-Jing/ASPC.
Enhancing Boundary Segmentation for Topological Accuracy with Skeleton-based Methods
Apr 29, 2024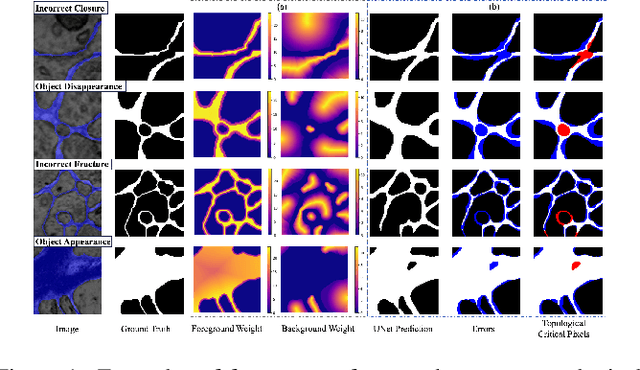
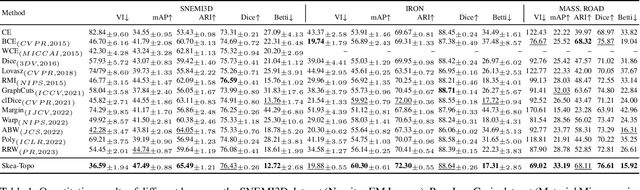
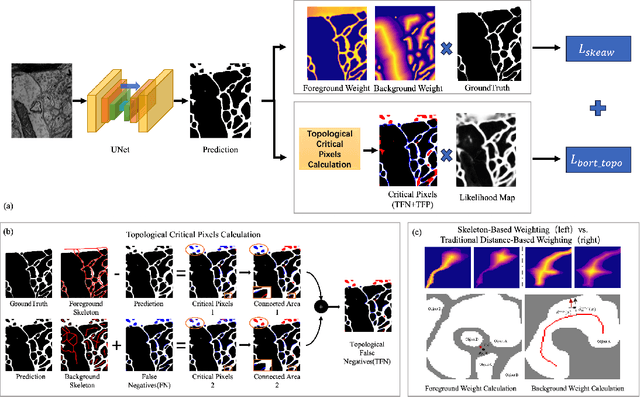

Topological consistency plays a crucial role in the task of boundary segmentation for reticular images, such as cell membrane segmentation in neuron electron microscopic images, grain boundary segmentation in material microscopic images and road segmentation in aerial images. In these fields, topological changes in segmentation results have a serious impact on the downstream tasks, which can even exceed the misalignment of the boundary itself. To enhance the topology accuracy in segmentation results, we propose the Skea-Topo Aware loss, which is a novel loss function that takes into account the shape of each object and topological significance of the pixels. It consists of two components. First, the skeleton-aware weighted loss improves the segmentation accuracy by better modeling the object geometry with skeletons. Second, a boundary rectified term effectively identifies and emphasizes topological critical pixels in the prediction errors using both foreground and background skeletons in the ground truth and predictions. Experiments prove that our method improves topological consistency by up to 7 points in VI compared to 13 state-of-art methods, based on objective and subjective assessments across three different boundary segmentation datasets. The code is available at https://github.com/clovermini/Skea_topo.
MatSAM: Efficient Materials Microstructure Extraction via Visual Large Model
Jan 11, 2024Accurate and efficient extraction of microstructures in microscopic images of materials plays a critical role in the exploration of structure-property relationships and the optimization of process parameters. Deep learning-based image segmentation techniques that rely on manual annotation are time-consuming and labor-intensive and hardly meet the demand for model transferability and generalization. Segment Anything Model (SAM), a large visual model with powerful deep feature representation and zero-shot generalization capabilities, has provided new solutions for image segmentation. However, directly applying SAM to segmenting microstructures in microscopic images of materials without human annotation cannot achieve the expected results, as the difficulty of adapting its native prompt engineering to the dense and dispersed characteristics of key microstructures in materials microscopy images. In this paper, we propose MatSAM, a general and efficient microstructure extraction solution based on SAM. A new point-based prompts generation strategy is designed, grounded on the distribution and shape of materials microstructures. It generates prompts for different microscopic images, fuses the prompts of the region of interest (ROI) key points and grid key points, and integrates post-processing methods for quantitative characterization of materials microstructures. For common microstructures including grain boundary and phase, MatSAM achieves superior segmentation performance to conventional methods and is even preferable to supervised learning methods evaluated on 18 materials microstructures imaged by the optical microscope (OM) and scanning electron microscope (SEM). We believe that MatSAM can significantly reduce the cost of quantitative characterization of materials microstructures and accelerate the design of new materials.
Spatial-Related Sensors Matters: 3D Human Motion Reconstruction Assisted with Textual Semantics
Dec 27, 2023



Leveraging wearable devices for motion reconstruction has emerged as an economical and viable technique. Certain methodologies employ sparse Inertial Measurement Units (IMUs) on the human body and harness data-driven strategies to model human poses. However, the reconstruction of motion based solely on sparse IMUs data is inherently fraught with ambiguity, a consequence of numerous identical IMU readings corresponding to different poses. In this paper, we explore the spatial importance of multiple sensors, supervised by text that describes specific actions. Specifically, uncertainty is introduced to derive weighted features for each IMU. We also design a Hierarchical Temporal Transformer (HTT) and apply contrastive learning to achieve precise temporal and feature alignment of sensor data with textual semantics. Experimental results demonstrate our proposed approach achieves significant improvements in multiple metrics compared to existing methods. Notably, with textual supervision, our method not only differentiates between ambiguous actions such as sitting and standing but also produces more precise and natural motion.
Dense residual Transformer for image denoising
May 14, 2022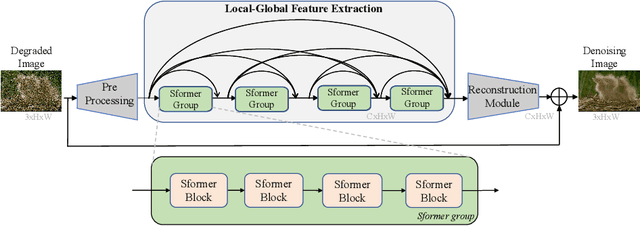
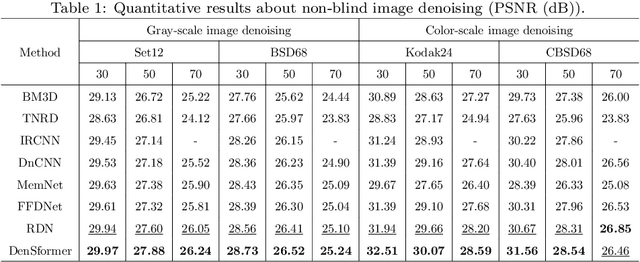
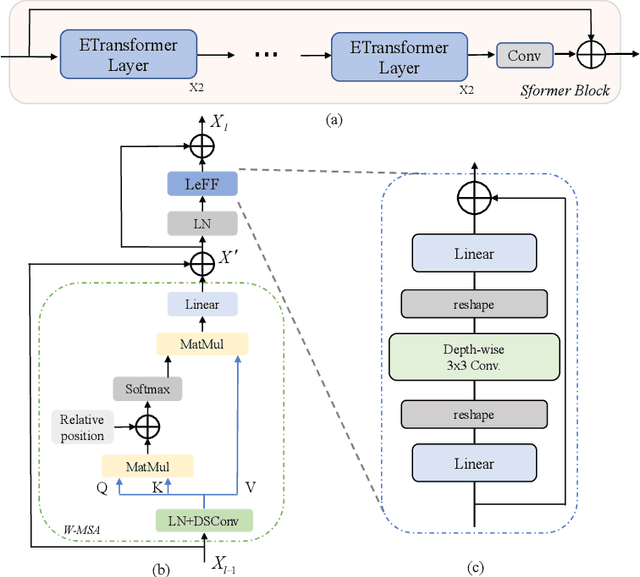
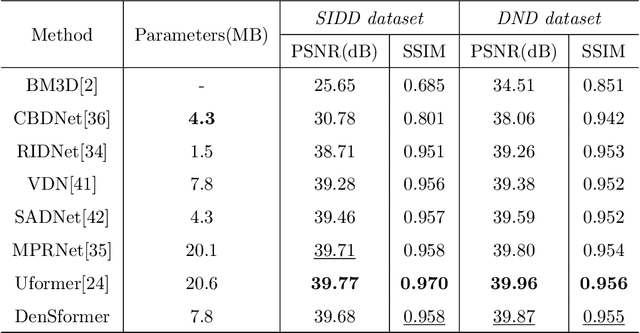
Image denoising is an important low-level computer vision task, which aims to reconstruct a noise-free and high-quality image from a noisy image. With the development of deep learning, convolutional neural network (CNN) has been gradually applied and achieved great success in image denoising, image compression, image enhancement, etc. Recently, Transformer has been a hot technique, which is widely used to tackle computer vision tasks. However, few Transformer-based methods have been proposed for low-level vision tasks. In this paper, we proposed an image denoising network structure based on Transformer, which is named DenSformer. DenSformer consists of three modules, including a preprocessing module, a local-global feature extraction module, and a reconstruction module. Specifically, the local-global feature extraction module consists of several Sformer groups, each of which has several ETransformer layers and a convolution layer, together with a residual connection. These Sformer groups are densely skip-connected to fuse the feature of different layers, and they jointly capture the local and global information from the given noisy images. We conduct our model on comprehensive experiments. Experimental results prove that our DenSformer achieves improvement compared to some state-of-the-art methods, both for the synthetic noise data and real noise data, in the objective and subjective evaluations.
Data privacy protection in microscopic image analysis for material data mining
Nov 09, 2021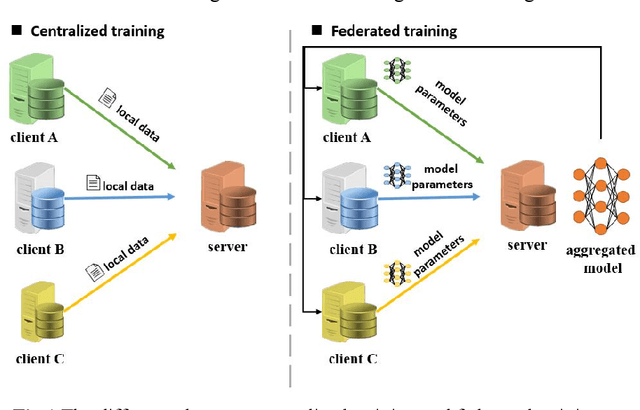
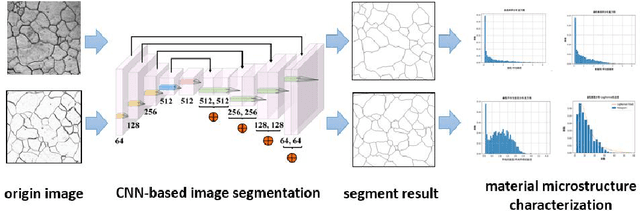
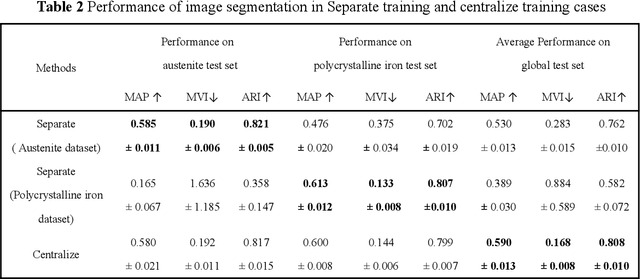
Recent progress in material data mining has been driven by high-capacity models trained on large datasets. However, collecting experimental data has been extremely costly owing to the amount of human effort and expertise required. Therefore, material researchers are often reluctant to easily disclose their private data, which leads to the problem of data island, and it is difficult to collect a large amount of data to train high-quality models. In this study, a material microstructure image feature extraction algorithm FedTransfer based on data privacy protection is proposed. The core contributions are as follows: 1) the federated learning algorithm is introduced into the polycrystalline microstructure image segmentation task to make full use of different user data to carry out machine learning, break the data island and improve the model generalization ability under the condition of ensuring the privacy and security of user data; 2) A data sharing strategy based on style transfer is proposed. By sharing style information of images that is not urgent for user confidentiality, it can reduce the performance penalty caused by the distribution difference of data among different users.
Gradient Aware Cascade Network for Multi-Focus Image Fusion
Oct 17, 2020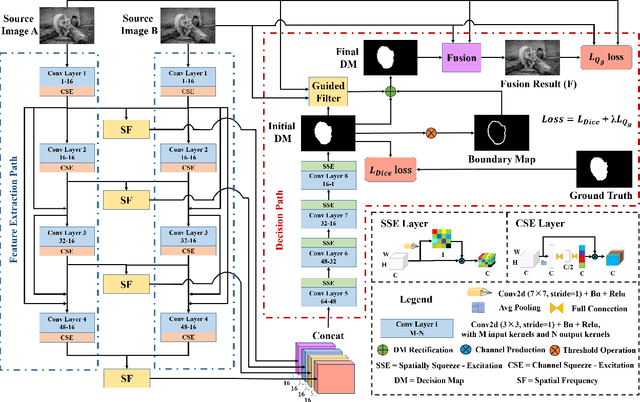
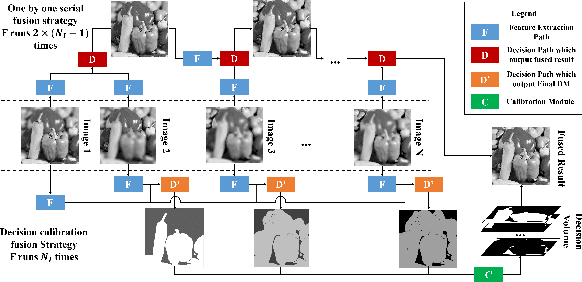
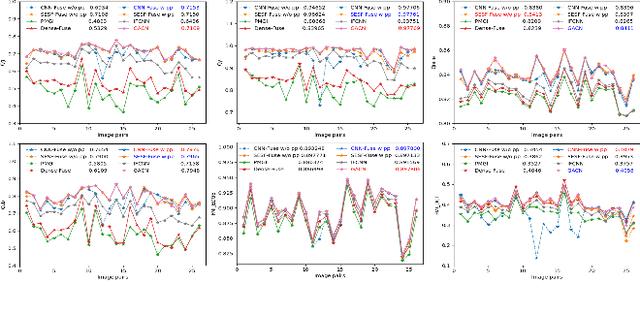

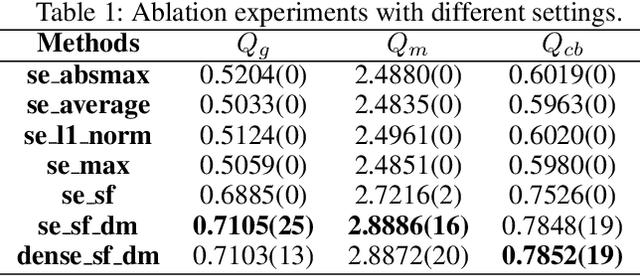
The general aim of multi-focus image fusion is to gather focused regions of different images to generate a unique all-in-focus fused image. Deep learning based methods become the mainstream of image fusion by virtue of its powerful feature representation ability. However, most of the existing deep learning structures failed to balance fusion quality and end-to-end implementation convenience. End-to-end decoder design often leads to poor performance because of its non-linear mapping mechanism. On the other hand, generating an intermediate decision map achieves better quality for the fused image, but relies on the rectification with empirical post-processing parameter choices. In this work, to handle the requirements of both output image quality and comprehensive simplicity of structure implementation, we propose a cascade network to simultaneously generate decision map and fused result with an end-to-end training procedure. It avoids the dependence on empirical post-processing methods in the inference stage. To improve the fusion quality, we introduce a gradient aware loss function to preserve gradient information in output fused image. In addition, we design a decision calibration strategy to decrease the time consumption in the application of multiple image fusion. Extensive experiments are conducted to compare with 16 different state-of-the-art multi-focus image fusion structures with 6 assessment metrics. The results prove that our designed structure can generally ameliorate the output fused image quality, while implementation efficiency increases over 30\% for multiple image fusion.
SESF-Fuse: An Unsupervised Deep Model for Multi-Focus Image Fusion
Aug 21, 2019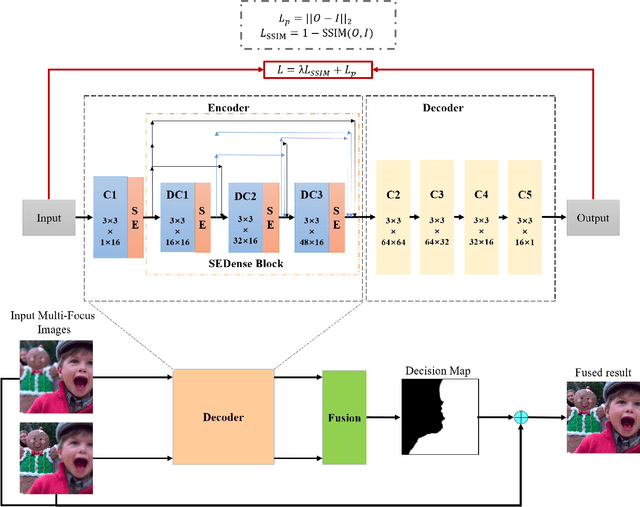
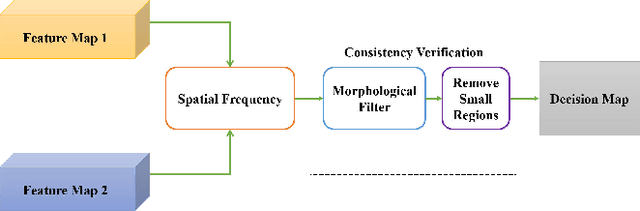
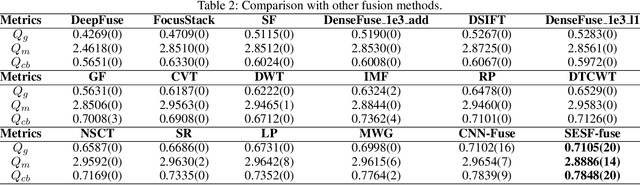
In this work, we propose a novel unsupervised deep learning model to address multi-focus image fusion problem. First, we train an encoder-decoder network in unsupervised manner to acquire deep feature of input images. And then we utilize these features and spatial frequency to measure activity level and decision map. Finally, we apply some consistency verification methods to adjust the decision map and draw out fused result. The key point behind of proposed method is that only the objects within the depth-of-field (DOF) have sharp appearance in the photograph while other objects are likely to be blurred. In contrast to previous works, our method analyzes sharp appearance in deep feature instead of original image. Experimental results demonstrate that the proposed method achieves the state-of-art fusion performance compared to existing 16 fusion methods in objective and subjective assessment.
Style transfer based data augmentation in material microscopic image processing
May 24, 2019



Recently progress in material microscopic image semantic segmentation has been driven by high-capacity models trained on large datasets. However, collecting microscopic images with pixel-level labels has been extremely costly due to the amount of human effort required. In this paper, we present an approach to rapidly creating microscopic images with pixel-level labels from material 3d simulated models. Usually images extracted directly from those 3d simulated models are not realistic enough. It is easy to get semantic labels, though. We introduce style transfer technique to make simulated image data more similar to real microscopic data. We validate the presented approach by using real image data from experiment and simulated image data from Monte Carlo Potts Models, which simulate the growth of polycrystal. Experiments show that using the acquired simulated image data and style transfer technique to supplement real images of polycrystalline iron significantly improves the mean precision of image processing. Besides, models trained with simulated image data and just 1/3 of the real data outperform models trained on the complete real image data. In the study of such polycrystalline materials, this approach can reduce pressure of getting and labeling images from microscopes. Also, it can be applied to numbers of other material images.
WPU-Net:Boundary learning by using weighted propagation in convolution network
May 22, 2019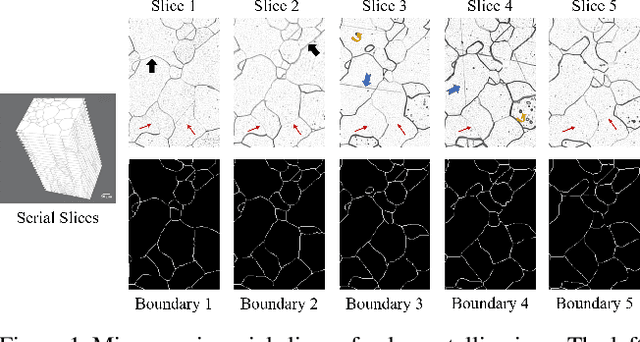
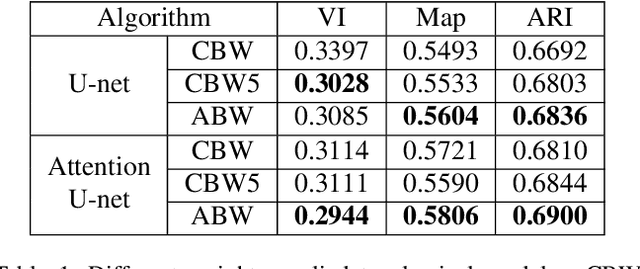
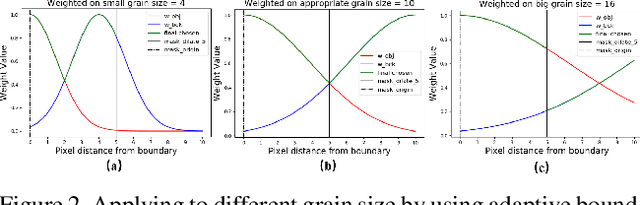
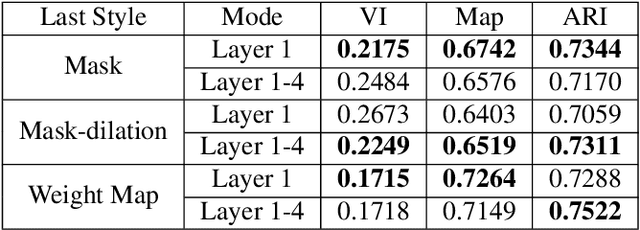
Deep learning has driven great progress in natural and biological image processing. However, in materials science and engineering, there are often some flaws and indistinctions in material microscopic images induced from complex sample preparation, even due to the material itself, hindering the detection of target objects. In this work, we propose WPU-net that redesign the architecture and weighted loss of U-Net to force the network to integrate information from adjacent slices and pay more attention to the topology in this boundary detection task. Then, the WPU-net was applied into a typical material example, i.e., the grain boundary detection of polycrystalline material. Experiments demonstrate that the proposed method achieves promising performance compared to state-of-the-art methods. Besides, we propose a new method for object tracking between adjacent slices, which can effectively reconstruct the 3D structure of the whole material while maintaining relative accuracy.