 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^3$IT: A Benchmark for Spatially Situated Social Intelligence Test
Dec 23, 2025
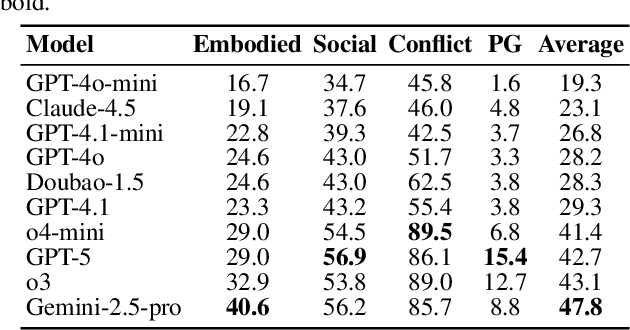
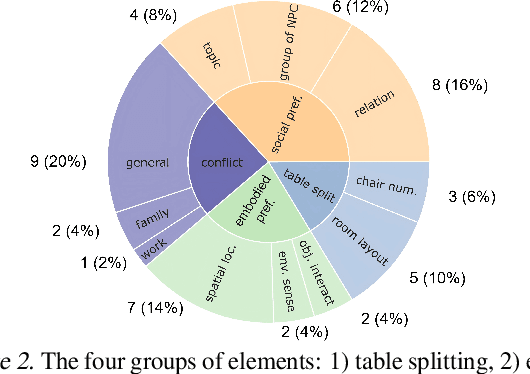

The integration of embodied agents into human environments demands embodied social intelligence: reasoning over both social norms and physical constraints. However, existing evaluations fail to address this integration, as they are limited to either disembodied social reasoning (e.g., in text) or socially-agnostic physical tasks. Both approaches fail to assess an agent's ability to integrate and trade off both physical and social constraints within a realistic, embodied context. To address this challenge, we introduce Spatially Situated Social Intelligence Test (S$^{3}$IT), a benchmark specifically designed to evaluate embodied social intelligence. It is centered on a novel and challenging seat-ordering task, requiring an agent to arrange seating in a 3D environment for a group of large language model-driven (LLM-driven) NPCs with diverse identities, preferences, and intricate interpersonal relationships. Our procedurally extensible framework generates a vast and diverse scenario space with controllable difficulty, compelling the agent to acquire preferences through active dialogue, perceive the environment via autonomous exploration, and perform multi-objective optimization within a complex constraint network. We evaluate state-of-the-art LLMs on S$^{3}$IT and found that they still struggle with this problem, showing an obvious gap compared with the human baseline. Results imply that LLMs have deficiencies in spatial intelligence, yet simultaneously demonstrate their ability to achieve near human-level competence in resolving conflicts that possess explicit textual cues.
TongSIM: A General Platform for Simulating Intelligent Machines
Dec 23, 2025As artificial intelligence (AI) rapidly advances, especially in multimodal large language models (MLLMs), research focus is shifting from single-modality text processing to the more complex domains of multimodal and embodied AI. Embodied intelligence focuses on training agents within realistic simulated environments, leveraging physical interaction and action feedback rather than conventionally labeled datasets. Yet, most existing simulation platforms remain narrowly designed, each tailored to specific tasks. A versatile, general-purpose training environment that can support everything from low-level embodied navigation to high-level composite activities, such as multi-agent social simulation and human-AI collaboration, remains largely unavailable. To bridge this gap, we introduce TongSIM, a high-fidelity, general-purpose platform for training and evaluating embodied agents. TongSIM offers practical advantages by providing over 100 diverse, multi-room indoor scenarios as well as an open-ended, interaction-rich outdoor town simulation, ensuring broad applicability across research needs. Its comprehensive evaluation framework and benchmarks enable precise assessment of agent capabilities, such as perception, cognition, decision-making, human-robot cooperation, and spatial and social reasoning. With features like customized scenes, task-adaptive fidelity, diverse agent types, and dynamic environmental simulation, TongSIM delivers flexibility and scalability for researchers, serving as a unified platform that accelerates training, evaluation, and advancement toward general embodied intelligence.
Spatial-Related Sensors Matters: 3D Human Motion Reconstruction Assisted with Textual Semantics
Dec 27, 2023Leveraging wearable devices for motion reconstruction has emerged as an economical and viable technique. Certain methodologies employ sparse Inertial Measurement Units (IMUs) on the human body and harness data-driven strategies to model human poses. However, the reconstruction of motion based solely on sparse IMUs data is inherently fraught with ambiguity, a consequence of numerous identical IMU readings corresponding to different poses. In this paper, we explore the spatial importance of multiple sensors, supervised by text that describes specific actions. Specifically, uncertainty is introduced to derive weighted features for each IMU. We also design a Hierarchical Temporal Transformer (HTT) and apply contrastive learning to achieve precise temporal and feature alignment of sensor data with textual semantics. Experimental results demonstrate our proposed approach achieves significant improvements in multiple metrics compared to existing methods. Notably, with textual supervision, our method not only differentiates between ambiguous actions such as sitting and standing but also produces more precise and natural motion.
Flow Guided Short-term Trackers with Cascade Detection for Long-term Tracking
Sep 01, 2019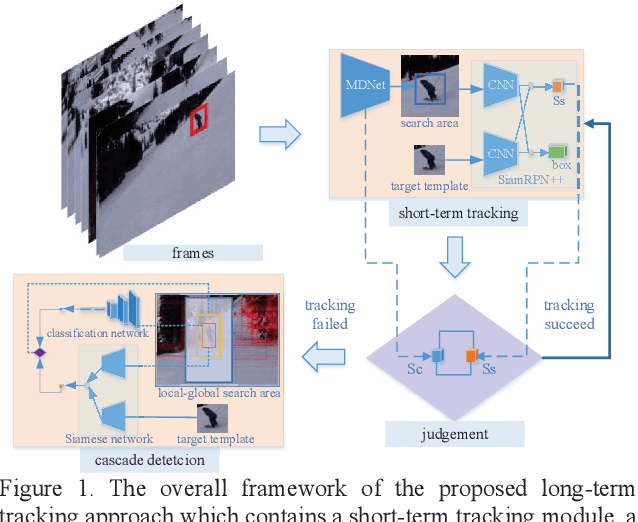
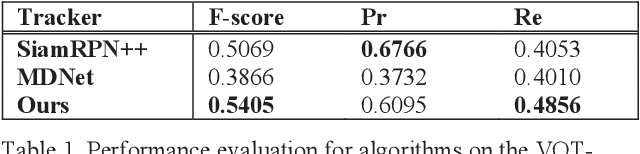
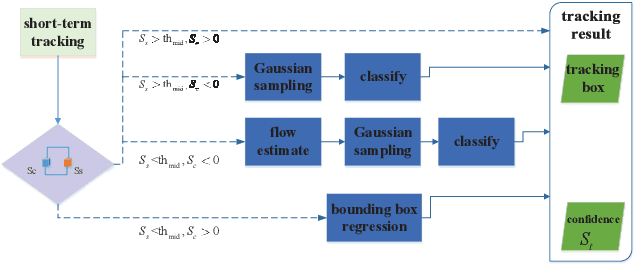

Object tracking has been studied for decades, but most of the existing works are focused on the short-term tracking. For a long sequence, the object is often fully occluded or out of view for a long time, and existing short-term object tracking algorithms often lose the target, and it is difficult to re-catch the target even if it reappears again. In this paper a novel long-term object tracking algorithm flow_MDNet_RPN is proposed, in which a tracking result judgement module and a detection module are added to the short-term object tracking algorithm. Experiments show that the proposed long-term tracking algorithm is effective to the problem of target disappearance.