 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning With Counterfactual Group Relative Policy Advantage For Multi-Agent Reinforcement Learning
Jun 09, 2025Multi-agent reinforcement learning (MARL) has achieved strong performance in cooperative adversarial tasks. However, most existing methods typically train agents against fixed opponent strategies and rely on such meta-static difficulty conditions, which limits their adaptability to changing environments and often leads to suboptimal policies. Inspired by the success of curriculum learning (CL) in supervised tasks, we propose a dynamic CL framework for MARL that employs an self-adaptive difficulty adjustment mechanism. This mechanism continuously modulates opponent strength based on real-time agent training performance, allowing agents to progressively learn from easier to more challenging scenarios. However, the dynamic nature of CL introduces instability due to nonstationary environments and sparse global rewards. To address this challenge, we develop a Counterfactual Group Relative Policy Advantage (CGRPA), which is tightly coupled with the curriculum by providing intrinsic credit signals that reflect each agent's impact under evolving task demands. CGRPA constructs a counterfactual advantage function that isolates individual contributions within group behavior, facilitating more reliable policy updates throughout the curriculum. CGRPA evaluates each agent's contribution through constructing counterfactual action advantage function, providing intrinsic rewards that enhance credit assignment and stabilize learning under non-stationary conditions. Extensive experiments demonstrate that our method improves both training stability and final performance, achieving competitive results against state-of-the-art methods. The code is available at https://github.com/NICE-HKU/CL2MARL-SMAC.
State-space Decomposition Model for Video Prediction Considering Long-term Motion Trend
Apr 17, 2024Stochastic video prediction enables the consideration of uncertainty in future motion, thereby providing a better reflection of the dynamic nature of the environment. Stochastic video prediction methods based on image auto-regressive recurrent models need to feed their predictions back into the latent space. Conversely, the state-space models, which decouple frame synthesis and temporal prediction, proves to be more efficient. However, inferring long-term temporal information about motion and generalizing to dynamic scenarios under non-stationary assumptions remains an unresolved challenge. In this paper, we propose a state-space decomposition stochastic video prediction model that decomposes the overall video frame generation into deterministic appearance prediction and stochastic motion prediction. Through adaptive decomposition, the model's generalization capability to dynamic scenarios is enhanced. In the context of motion prediction, obtaining a prior on the long-term trend of future motion is crucial. Thus, in the stochastic motion prediction branch, we infer the long-term motion trend from conditional frames to guide the generation of future frames that exhibit high consistency with the conditional frames. Experimental results demonstrate that our model outperforms baselines on multiple datasets.
Self-Attention Empowered Graph Convolutional Network for Structure Learning and Node Embedding
Mar 06, 2024In representation learning on graph-structured data, many popular graph neural networks (GNNs) fail to capture long-range dependencies, leading to performance degradation. Furthermore, this weakness is magnified when the concerned graph is characterized by heterophily (low homophily). To solve this issue, this paper proposes a novel graph learning framework called the graph convolutional network with self-attention (GCN-SA). The proposed scheme exhibits an exceptional generalization capability in node-level representation learning. The proposed GCN-SA contains two enhancements corresponding to edges and node features. For edges, we utilize a self-attention mechanism to design a stable and effective graph-structure-learning module that can capture the internal correlation between any pair of nodes. This graph-structure-learning module can identify reliable neighbors for each node from the entire graph. Regarding the node features, we modify the transformer block to make it more applicable to enable GCN to fuse valuable information from the entire graph. These two enhancements work in distinct ways to help our GCN-SA capture long-range dependencies, enabling it to perform representation learning on graphs with varying levels of homophily. The experimental results on benchmark datasets demonstrate the effectiveness of the proposed GCN-SA. Compared to other outstanding GNN counterparts, the proposed GCN-SA is competitive.
Hierarchical Multi-Relational Graph Representation Learning for Large-Scale Prediction of Drug-Drug Interactions
Feb 28, 2024Most existing methods for predicting drug-drug interactions (DDI) predominantly concentrate on capturing the explicit relationships among drugs, overlooking the valuable implicit correlations present between drug pairs (DPs), which leads to weak predictions. To address this issue, this paper introduces a hierarchical multi-relational graph representation learning (HMGRL) approach. Within the framework of HMGRL, we leverage a wealth of drug-related heterogeneous data sources to construct heterogeneous graphs, where nodes represent drugs and edges denote clear and various associations. The relational graph convolutional network (RGCN) is employed to capture diverse explicit relationships between drugs from these heterogeneous graphs. Additionally, a multi-view differentiable spectral clustering (MVDSC) module is developed to capture multiple valuable implicit correlations between DPs. Within the MVDSC, we utilize multiple DP features to construct graphs, where nodes represent DPs and edges denote different implicit correlations. Subsequently, multiple DP representations are generated through graph cutting, each emphasizing distinct implicit correlations. The graph-cutting strategy enables our HMGRL to identify strongly connected communities of graphs, thereby reducing the fusion of irrelevant features. By combining every representation view of a DP, we create high-level DP representations for predicting DDIs. Two genuine datasets spanning three distinct tasks are adopted to gauge the efficacy of our HMGRL. Experimental outcomes unequivocally indicate that HMGRL surpasses several leading-edge methods in performance.
Relation-aware subgraph embedding with co-contrastive learning for drug-drug interaction prediction
Jul 04, 2023Relation-aware subgraph embedding is promising for predicting multi-relational drug-drug interactions (DDIs). Typically, most existing methods begin by constructing a multi-relational DDI graph and then learning relation-aware subgraph embeddings (RaSEs) of drugs from the DDI graph. However, most existing approaches are usually limited in learning RaSEs of new drugs, leading to serious over-fitting when the test DDIs involve such drugs. To alleviate this issue, We propose a novel DDI prediction method based on relation-aware subgraph embedding with co-contrastive learning, RaSECo. RaSECo constructs two heterogeneous drug graphs: a multi-relational DDI graph and a multi-attributes-based drug-drug similarity (DDS) graph. The two graphs are used respectively for learning and propagating the RaSEs of drugs, thereby ensuring that all drugs, including new ones, can aggregate effective RaSEs. Additionally, we employ a cross-view contrastive mechanism to enhance drug-pair (DP) embedding. RaSECo learns DP embeddings from two distinct views (interaction and similarity views) and encourages these views to supervise each other collaboratively to obtain more discriminative DP embeddings. We evaluate the effectiveness of our RaSECo on three different tasks using two real datasets. The experimental results demonstrate that RaSECo outperforms existing state-of-the-art prediction methods.
Landmark Guided Active Exploration with Stable Low-level Policy Learning
Jun 30, 2023Goal-conditioned hierarchical reinforcement learning (GCHRL) decomposes long-horizon tasks into sub-tasks through a hierarchical framework and it has demonstrated promising results across a variety of domains. However, the high-level policy's action space is often excessively large, presenting a significant challenge to effective exploration and resulting in potentially inefficient training. Moreover, the dynamic variability of the low-level policy introduces non-stationarity to the high-level state transition function, significantly impeding the learning of the high-level policy. In this paper, we design a measure of prospect for subgoals by planning in the goal space based on the goal-conditioned value function. Building upon the measure of prospect, we propose a landmark-guided exploration strategy by integrating the measures of prospect and novelty which aims to guide the agent to explore efficiently and improve sample efficiency. To address the non-stationarity arising from the dynamic changes of the low-level policy, we apply a state-specific regularization to the learning of low-level policy, which facilitates stable learning of the hierarchical policy. The experimental results demonstrate that our proposed exploration strategy significantly outperforms the baseline methods across multiple tasks.
Image Augmentation Based Momentum Memory Intrinsic Reward for Sparse Reward Visual Scenes
May 19, 2022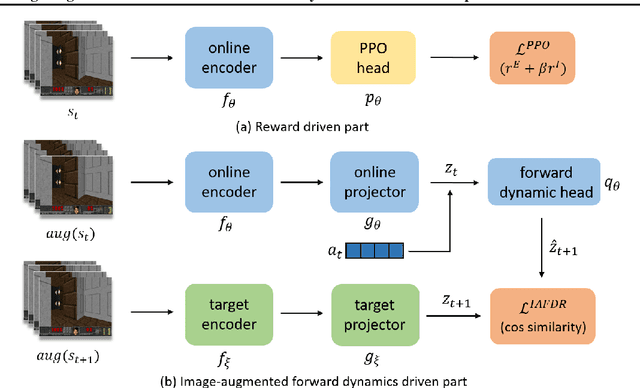
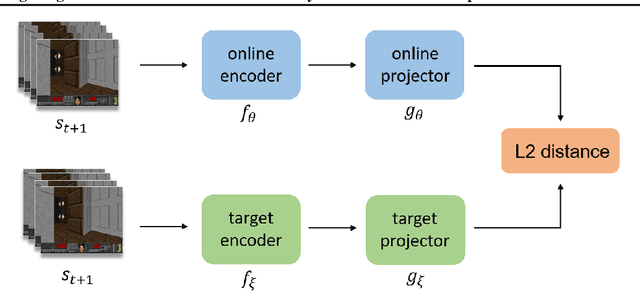

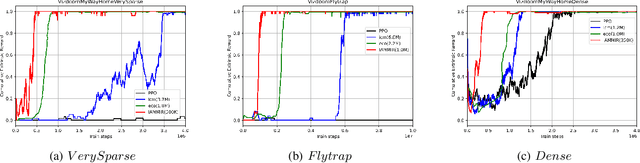
Many scenes in real life can be abstracted to the sparse reward visual scenes, where it is difficult for an agent to tackle the task under the condition of only accepting images and sparse rewards. We propose to decompose this problem into two sub-problems: the visual representation and the sparse reward. To address them, a novel framework IAMMIR combining the self-supervised representation learning with the intrinsic motivation is presented. For visual representation, a representation driven by a combination of the imageaugmented forward dynamics and the reward is acquired. For sparse rewards, a new type of intrinsic reward is designed, the Momentum Memory Intrinsic Reward (MMIR). It utilizes the difference of the outputs from the current model (online network) and the historical model (target network) to present the agent's state familiarity. Our method is evaluated on the visual navigation task with sparse rewards in Vizdoom. Experiments demonstrate that our method achieves the state of the art performance in sample efficiency, at least 2 times faster than the existing methods reaching 100% success rate.
Self-supervised Learning of Occlusion Aware Flow Guided 3D Geometry Perception with Adaptive Cross Weighted Loss from Monocular Videos
Aug 10, 2021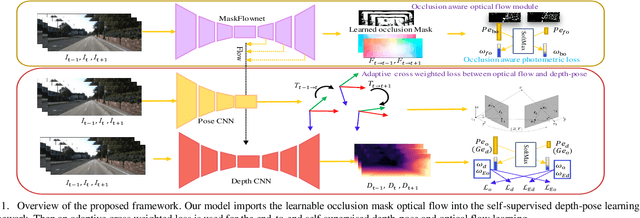
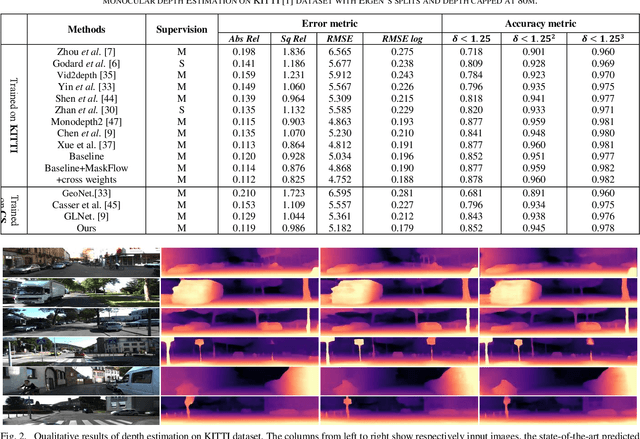
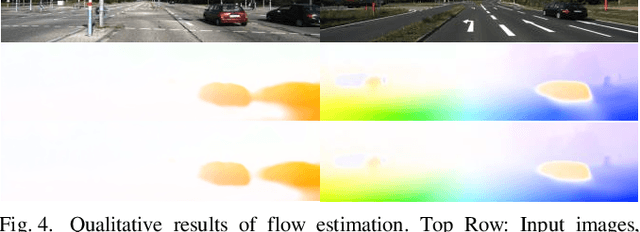
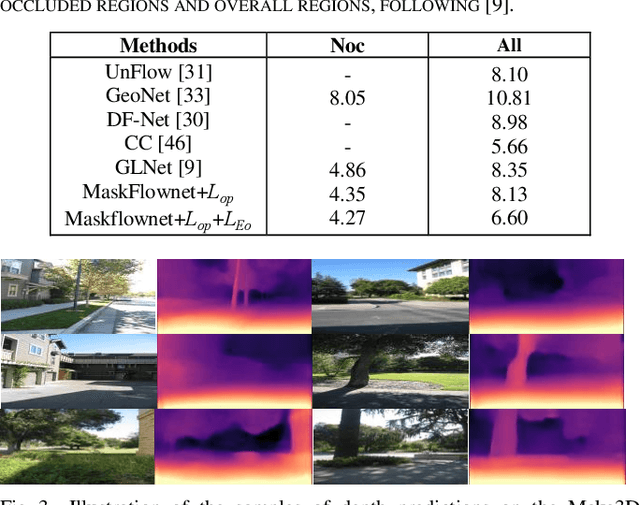
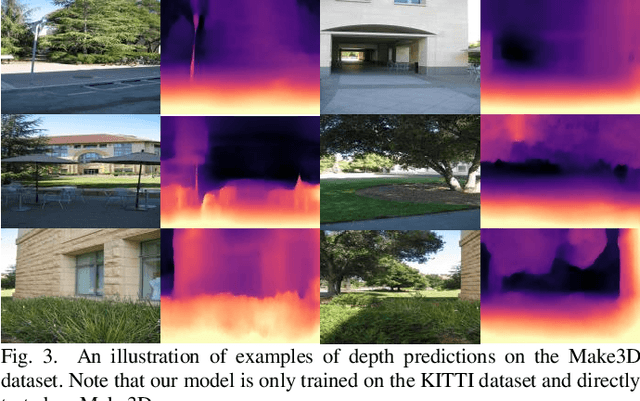
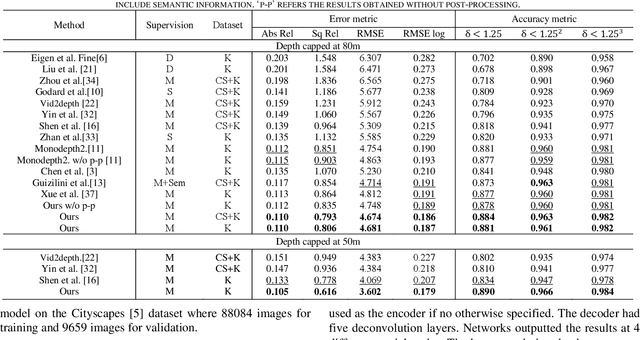
Self-supervised deep learning-based 3D scene understanding methods can overcome the difficulty of acquiring the densely labeled ground-truth and have made a lot of advances. However, occlusions and moving objects are still some of the major limitations. In this paper, we explore the learnable occlusion aware optical flow guided self-supervised depth and camera pose estimation by an adaptive cross weighted loss to address the above limitations. Firstly, we explore to train the learnable occlusion mask fused optical flow network by an occlusion-aware photometric loss with the temporally supplemental information and backward-forward consistency of adjacent views. And then, we design an adaptive cross-weighted loss between the depth-pose and optical flow loss of the geometric and photometric error to distinguish the moving objects which violate the static scene assumption. Our method shows promising results on KITTI, Make3D, and Cityscapes datasets under multiple tasks. We also show good generalization ability under a variety of challenging scenarios.
Self-Supervised Learning of Depth and Ego-Motion from Video by Alternative Training and Geometric Constraints from 3D to 2D
Aug 04, 2021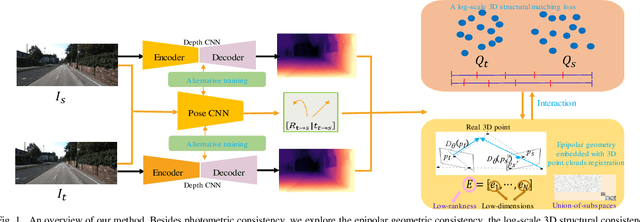
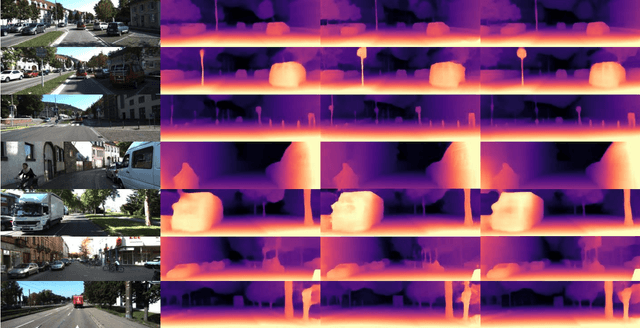
Self-supervised learning of depth and ego-motion from unlabeled monocular video has acquired promising results and drawn extensive attention. Most existing methods jointly train the depth and pose networks by photometric consistency of adjacent frames based on the principle of structure-from-motion (SFM). However, the coupling relationship of the depth and pose networks seriously influences the learning performance, and the re-projection relations is sensitive to scale ambiguity, especially for pose learning. In this paper, we aim to improve the depth-pose learning performance without the auxiliary tasks and address the above issues by alternative training each task and incorporating the epipolar geometric constraints into the Iterative Closest Point (ICP) based point clouds match process. Distinct from jointly training the depth and pose networks, our key idea is to better utilize the mutual dependency of these two tasks by alternatively training each network with respective losses while fixing the other. We also design a log-scale 3D structural consistency loss to put more emphasis on the smaller depth values during training. To makes the optimization easier, we further incorporate the epipolar geometry into the ICP based learning process for pose learning. Extensive experiments on various benchmarks datasets indicate the superiority of our algorithm over the state-of-the-art self-supervised methods.
Trainable Class Prototypes for Few-Shot Learning
Jun 21, 2021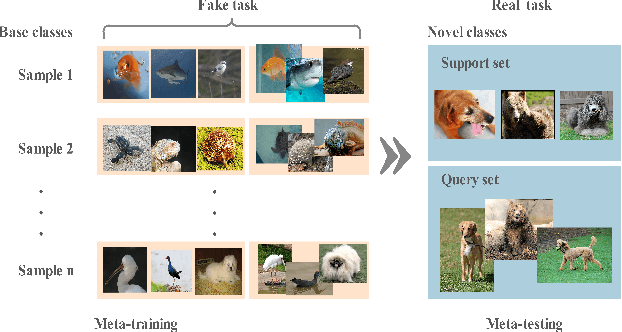
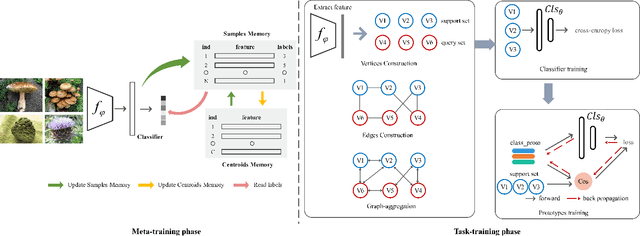
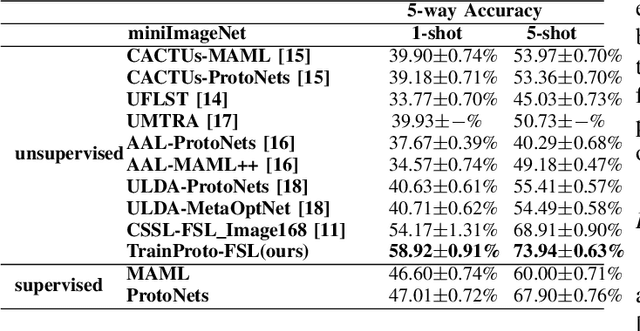

Metric learning is a widely used method for few shot learning in which the quality of prototypes plays a key role in the algorithm. In this paper we propose the trainable prototypes for distance measure instead of the artificial ones within the meta-training and task-training framework. Also to avoid the disadvantages that the episodic meta-training brought, we adopt non-episodic meta-training based on self-supervised learning. Overall we solve the few-shot tasks in two phases: meta-training a transferable feature extractor via self-supervised learning and training the prototypes for metric classification. In addition, the simple attention mechanism is used in both meta-training and task-training. Our method achieves state-of-the-art performance in a variety of established few-shot tasks on the standard few-shot visual classification dataset, with about 20% increase compared to the available unsupervised few-shot learning methods.