 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Augmentation Based Momentum Memory Intrinsic Reward for Sparse Reward Visual Scenes
Paper and Code
May 19, 2022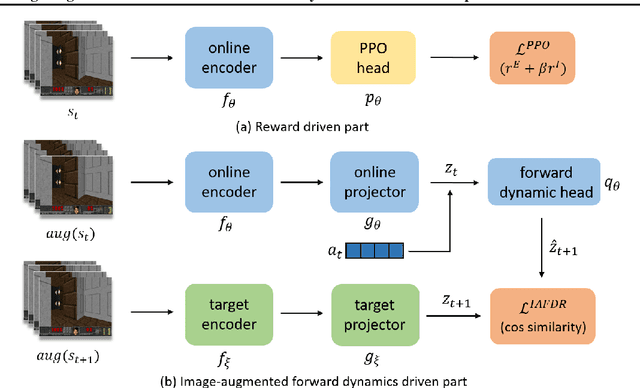
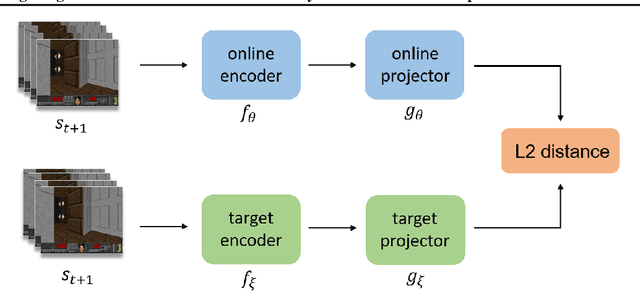

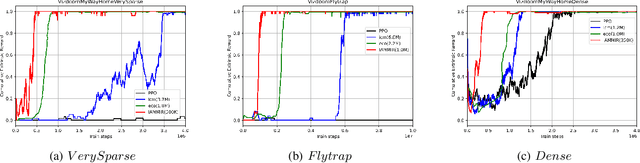
Many scenes in real life can be abstracted to the sparse reward visual scenes, where it is difficult for an agent to tackle the task under the condition of only accepting images and sparse rewards. We propose to decompose this problem into two sub-problems: the visual representation and the sparse reward. To address them, a novel framework IAMMIR combining the self-supervised representation learning with the intrinsic motivation is presented. For visual representation, a representation driven by a combination of the imageaugmented forward dynamics and the reward is acquired. For sparse rewards, a new type of intrinsic reward is designed, the Momentum Memory Intrinsic Reward (MMIR). It utilizes the difference of the outputs from the current model (online network) and the historical model (target network) to present the agent's state familiarity. Our method is evaluated on the visual navigation task with sparse rewards in Vizdoom. Experiments demonstrate that our method achieves the state of the art performance in sample efficiency, at least 2 times faster than the existing methods reaching 100% success rate.