 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Multi-Agent Cooperative Decision-Making: Scenarios, Approaches, Challenges and Perspectives
Mar 17, 2025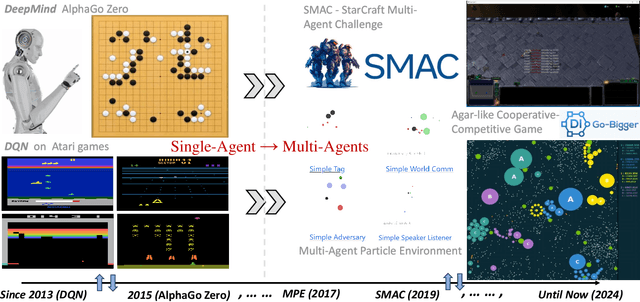

With the rapid development of artificial intelligence, intelligent decision-making techniques have gradually surpassed human levels in various human-machine competitions, especially in complex multi-agent cooperative task scenarios. Multi-agent cooperative decision-making involves multiple agents working together to complete established tasks and achieve specific objectives. These techniques are widely applicable in real-world scenarios such as autonomous driving, drone navigation, disaster rescue, and simulated military confrontations. This paper begins with a comprehensive survey of the leading simulation environments and platforms used for multi-agent cooperative decision-making. Specifically, we provide an in-depth analysis for these simulation environments from various perspectives, including task formats, reward allocation, and the underlying technologies employed. Subsequently, we provide a comprehensive overview of the mainstream intelligent decision-making approaches, algorithms and models for multi-agent systems (MAS). Theseapproaches can be broadly categorized into five types: rule-based (primarily fuzzy logic), game theory-based, evolutionary algorithms-based, deep multi-agent reinforcement learning (MARL)-based, and large language models(LLMs)reasoning-based. Given the significant advantages of MARL andLLMs-baseddecision-making methods over the traditional rule, game theory, and evolutionary algorithms, this paper focuses on these multi-agent methods utilizing MARL and LLMs-based techniques. We provide an in-depth discussion of these approaches, highlighting their methodology taxonomies, advantages, and drawbacks. Further, several prominent research directions in the future and potential challenges of multi-agent cooperative decision-making are also detailed.
Hierarchical Multi-Relational Graph Representation Learning for Large-Scale Prediction of Drug-Drug Interactions
Feb 28, 2024Most existing methods for predicting drug-drug interactions (DDI) predominantly concentrate on capturing the explicit relationships among drugs, overlooking the valuable implicit correlations present between drug pairs (DPs), which leads to weak predictions. To address this issue, this paper introduces a hierarchical multi-relational graph representation learning (HMGRL) approach. Within the framework of HMGRL, we leverage a wealth of drug-related heterogeneous data sources to construct heterogeneous graphs, where nodes represent drugs and edges denote clear and various associations. The relational graph convolutional network (RGCN) is employed to capture diverse explicit relationships between drugs from these heterogeneous graphs. Additionally, a multi-view differentiable spectral clustering (MVDSC) module is developed to capture multiple valuable implicit correlations between DPs. Within the MVDSC, we utilize multiple DP features to construct graphs, where nodes represent DPs and edges denote different implicit correlations. Subsequently, multiple DP representations are generated through graph cutting, each emphasizing distinct implicit correlations. The graph-cutting strategy enables our HMGRL to identify strongly connected communities of graphs, thereby reducing the fusion of irrelevant features. By combining every representation view of a DP, we create high-level DP representations for predicting DDIs. Two genuine datasets spanning three distinct tasks are adopted to gauge the efficacy of our HMGRL. Experimental outcomes unequivocally indicate that HMGRL surpasses several leading-edge methods in performance.
Relation-aware subgraph embedding with co-contrastive learning for drug-drug interaction prediction
Jul 04, 2023Relation-aware subgraph embedding is promising for predicting multi-relational drug-drug interactions (DDIs). Typically, most existing methods begin by constructing a multi-relational DDI graph and then learning relation-aware subgraph embeddings (RaSEs) of drugs from the DDI graph. However, most existing approaches are usually limited in learning RaSEs of new drugs, leading to serious over-fitting when the test DDIs involve such drugs. To alleviate this issue, We propose a novel DDI prediction method based on relation-aware subgraph embedding with co-contrastive learning, RaSECo. RaSECo constructs two heterogeneous drug graphs: a multi-relational DDI graph and a multi-attributes-based drug-drug similarity (DDS) graph. The two graphs are used respectively for learning and propagating the RaSEs of drugs, thereby ensuring that all drugs, including new ones, can aggregate effective RaSEs. Additionally, we employ a cross-view contrastive mechanism to enhance drug-pair (DP) embedding. RaSECo learns DP embeddings from two distinct views (interaction and similarity views) and encourages these views to supervise each other collaboratively to obtain more discriminative DP embeddings. We evaluate the effectiveness of our RaSECo on three different tasks using two real datasets. The experimental results demonstrate that RaSECo outperforms existing state-of-the-art prediction methods.
ChatAgri: Exploring Potentials of ChatGPT on Cross-linguistic Agricultural Text Classification
May 24, 2023In the era of sustainable smart agriculture, a massive amount of agricultural news text is being posted on the Internet, in which massive agricultural knowledge has been accumulated. In this context, it is urgent to explore effective text classification techniques for users to access the required agricultural knowledge with high efficiency. Mainstream deep learning approaches employing fine-tuning strategies on pre-trained language models (PLMs), have demonstrated remarkable performance gains over the past few years. Nonetheless, these methods still face many drawbacks that are complex to solve, including: 1. Limited agricultural training data due to the expensive-cost and labour-intensive annotation; 2. Poor domain transferability, especially of cross-linguistic ability; 3. Complex and expensive large models deployment.Inspired by the extraordinary success brought by the recent ChatGPT (e.g. GPT-3.5, GPT-4), in this work, we systematically investigate and explore the capability and utilization of ChatGPT applying to the agricultural informatization field. ....(shown in article).... Code has been released on Github https://github.com/albert-jin/agricultural_textual_classification_ChatGPT.
Image Augmentation Based Momentum Memory Intrinsic Reward for Sparse Reward Visual Scenes
May 19, 2022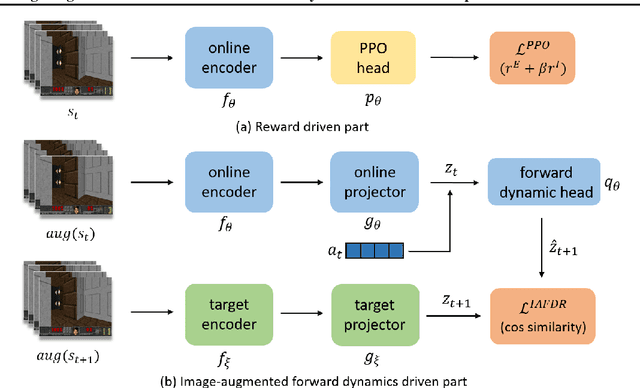
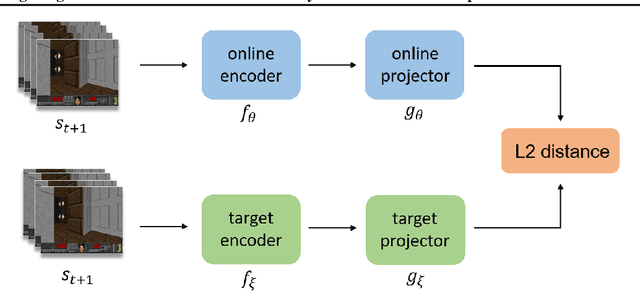

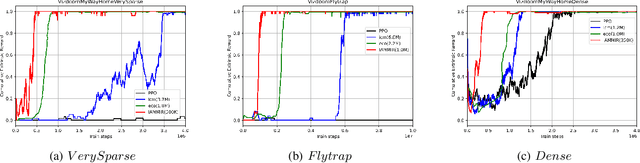
Many scenes in real life can be abstracted to the sparse reward visual scenes, where it is difficult for an agent to tackle the task under the condition of only accepting images and sparse rewards. We propose to decompose this problem into two sub-problems: the visual representation and the sparse reward. To address them, a novel framework IAMMIR combining the self-supervised representation learning with the intrinsic motivation is presented. For visual representation, a representation driven by a combination of the imageaugmented forward dynamics and the reward is acquired. For sparse rewards, a new type of intrinsic reward is designed, the Momentum Memory Intrinsic Reward (MMIR). It utilizes the difference of the outputs from the current model (online network) and the historical model (target network) to present the agent's state familiarity. Our method is evaluated on the visual navigation task with sparse rewards in Vizdoom. Experiments demonstrate that our method achieves the state of the art performance in sample efficiency, at least 2 times faster than the existing methods reaching 100% success rate.
A Resilient Image Matching Method with an Affine Invariant Feature Detector and Descriptor
Dec 29, 2017
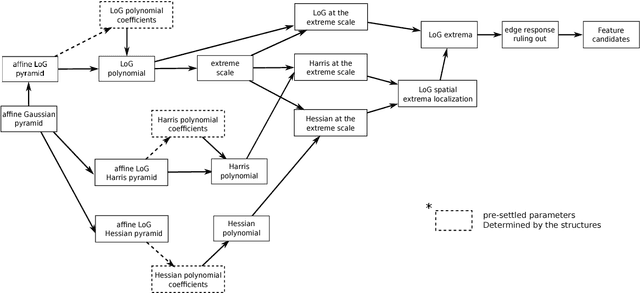
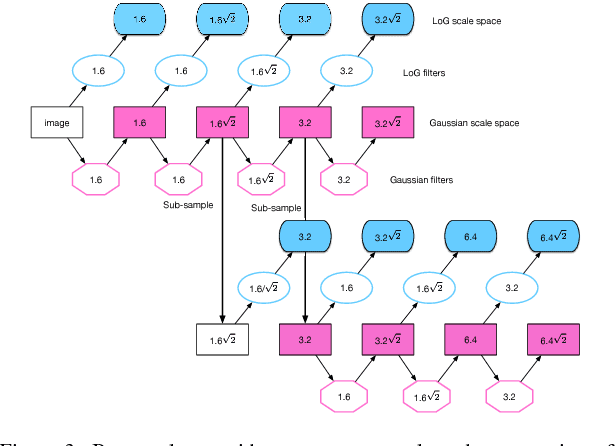
Image feature matching is to seek, localize and identify the similarities across the images. The matched local features between different images can indicate the similarities of their content. Resilience of image feature matching to large view point changes is challenging for a lot of applications such as 3D object reconstruction, object recognition and navigation, etc, which need accurate and robust feature matching from quite different view points. In this paper we propose a novel image feature matching algorithm, integrating our previous proposed Affine Invariant Feature Detector (AIFD) and new proposed Affine Invariant Feature Descriptor (AIFDd). Both stages of this new proposed algorithm can provide sufficient resilience to view point changes. With systematic experiments, we can prove that the proposed method of feature detector and descriptor outperforms other state-of-the-art feature matching algorithms especially on view points robustness. It also performs well under other conditions such as the change of illumination, rotation and compression, etc.