 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning With Counterfactual Group Relative Policy Advantage For Multi-Agent Reinforcement Learning
Jun 09, 2025Multi-agent reinforcement learning (MARL) has achieved strong performance in cooperative adversarial tasks. However, most existing methods typically train agents against fixed opponent strategies and rely on such meta-static difficulty conditions, which limits their adaptability to changing environments and often leads to suboptimal policies. Inspired by the success of curriculum learning (CL) in supervised tasks, we propose a dynamic CL framework for MARL that employs an self-adaptive difficulty adjustment mechanism. This mechanism continuously modulates opponent strength based on real-time agent training performance, allowing agents to progressively learn from easier to more challenging scenarios. However, the dynamic nature of CL introduces instability due to nonstationary environments and sparse global rewards. To address this challenge, we develop a Counterfactual Group Relative Policy Advantage (CGRPA), which is tightly coupled with the curriculum by providing intrinsic credit signals that reflect each agent's impact under evolving task demands. CGRPA constructs a counterfactual advantage function that isolates individual contributions within group behavior, facilitating more reliable policy updates throughout the curriculum. CGRPA evaluates each agent's contribution through constructing counterfactual action advantage function, providing intrinsic rewards that enhance credit assignment and stabilize learning under non-stationary conditions. Extensive experiments demonstrate that our method improves both training stability and final performance, achieving competitive results against state-of-the-art methods. The code is available at https://github.com/NICE-HKU/CL2MARL-SMAC.
A Comprehensive Survey on Multi-Agent Cooperative Decision-Making: Scenarios, Approaches, Challenges and Perspectives
Mar 17, 2025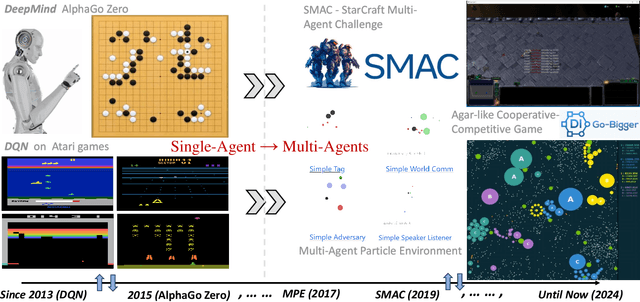

With the rapid development of artificial intelligence, intelligent decision-making techniques have gradually surpassed human levels in various human-machine competitions, especially in complex multi-agent cooperative task scenarios. Multi-agent cooperative decision-making involves multiple agents working together to complete established tasks and achieve specific objectives. These techniques are widely applicable in real-world scenarios such as autonomous driving, drone navigation, disaster rescue, and simulated military confrontations. This paper begins with a comprehensive survey of the leading simulation environments and platforms used for multi-agent cooperative decision-making. Specifically, we provide an in-depth analysis for these simulation environments from various perspectives, including task formats, reward allocation, and the underlying technologies employed. Subsequently, we provide a comprehensive overview of the mainstream intelligent decision-making approaches, algorithms and models for multi-agent systems (MAS). Theseapproaches can be broadly categorized into five types: rule-based (primarily fuzzy logic), game theory-based, evolutionary algorithms-based, deep multi-agent reinforcement learning (MARL)-based, and large language models(LLMs)reasoning-based. Given the significant advantages of MARL andLLMs-baseddecision-making methods over the traditional rule, game theory, and evolutionary algorithms, this paper focuses on these multi-agent methods utilizing MARL and LLMs-based techniques. We provide an in-depth discussion of these approaches, highlighting their methodology taxonomies, advantages, and drawbacks. Further, several prominent research directions in the future and potential challenges of multi-agent cooperative decision-making are also detailed.
Hierarchical Multi-Relational Graph Representation Learning for Large-Scale Prediction of Drug-Drug Interactions
Feb 28, 2024Most existing methods for predicting drug-drug interactions (DDI) predominantly concentrate on capturing the explicit relationships among drugs, overlooking the valuable implicit correlations present between drug pairs (DPs), which leads to weak predictions. To address this issue, this paper introduces a hierarchical multi-relational graph representation learning (HMGRL) approach. Within the framework of HMGRL, we leverage a wealth of drug-related heterogeneous data sources to construct heterogeneous graphs, where nodes represent drugs and edges denote clear and various associations. The relational graph convolutional network (RGCN) is employed to capture diverse explicit relationships between drugs from these heterogeneous graphs. Additionally, a multi-view differentiable spectral clustering (MVDSC) module is developed to capture multiple valuable implicit correlations between DPs. Within the MVDSC, we utilize multiple DP features to construct graphs, where nodes represent DPs and edges denote different implicit correlations. Subsequently, multiple DP representations are generated through graph cutting, each emphasizing distinct implicit correlations. The graph-cutting strategy enables our HMGRL to identify strongly connected communities of graphs, thereby reducing the fusion of irrelevant features. By combining every representation view of a DP, we create high-level DP representations for predicting DDIs. Two genuine datasets spanning three distinct tasks are adopted to gauge the efficacy of our HMGRL. Experimental outcomes unequivocally indicate that HMGRL surpasses several leading-edge methods in performance.
Relation-aware subgraph embedding with co-contrastive learning for drug-drug interaction prediction
Jul 04, 2023Relation-aware subgraph embedding is promising for predicting multi-relational drug-drug interactions (DDIs). Typically, most existing methods begin by constructing a multi-relational DDI graph and then learning relation-aware subgraph embeddings (RaSEs) of drugs from the DDI graph. However, most existing approaches are usually limited in learning RaSEs of new drugs, leading to serious over-fitting when the test DDIs involve such drugs. To alleviate this issue, We propose a novel DDI prediction method based on relation-aware subgraph embedding with co-contrastive learning, RaSECo. RaSECo constructs two heterogeneous drug graphs: a multi-relational DDI graph and a multi-attributes-based drug-drug similarity (DDS) graph. The two graphs are used respectively for learning and propagating the RaSEs of drugs, thereby ensuring that all drugs, including new ones, can aggregate effective RaSEs. Additionally, we employ a cross-view contrastive mechanism to enhance drug-pair (DP) embedding. RaSECo learns DP embeddings from two distinct views (interaction and similarity views) and encourages these views to supervise each other collaboratively to obtain more discriminative DP embeddings. We evaluate the effectiveness of our RaSECo on three different tasks using two real datasets. The experimental results demonstrate that RaSECo outperforms existing state-of-the-art prediction methods.
ChatAgri: Exploring Potentials of ChatGPT on Cross-linguistic Agricultural Text Classification
May 24, 2023In the era of sustainable smart agriculture, a massive amount of agricultural news text is being posted on the Internet, in which massive agricultural knowledge has been accumulated. In this context, it is urgent to explore effective text classification techniques for users to access the required agricultural knowledge with high efficiency. Mainstream deep learning approaches employing fine-tuning strategies on pre-trained language models (PLMs), have demonstrated remarkable performance gains over the past few years. Nonetheless, these methods still face many drawbacks that are complex to solve, including: 1. Limited agricultural training data due to the expensive-cost and labour-intensive annotation; 2. Poor domain transferability, especially of cross-linguistic ability; 3. Complex and expensive large models deployment.Inspired by the extraordinary success brought by the recent ChatGPT (e.g. GPT-3.5, GPT-4), in this work, we systematically investigate and explore the capability and utilization of ChatGPT applying to the agricultural informatization field. ....(shown in article).... Code has been released on Github https://github.com/albert-jin/agricultural_textual_classification_ChatGPT.
Improving Embedded Knowledge Graph Multi-hop Question Answering by introducing Relational Chain Reasoning
Oct 25, 2021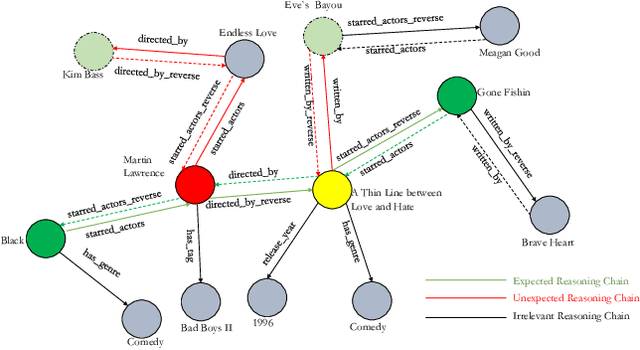
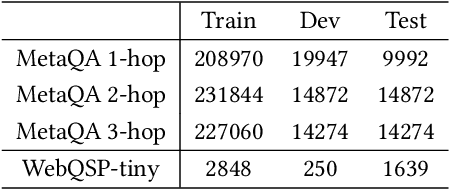
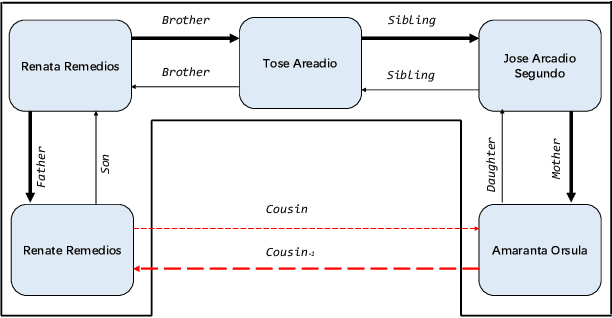
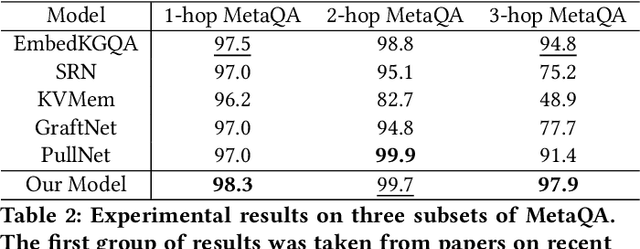
Knowledge Base Question Answering (KBQA) aims to answer userquestions from a knowledge base (KB) by identifying the reasoningrelations between topic entity and answer. As a complex branchtask of KBQA, multi-hop KGQA requires reasoning over multi-hop relational chains preserved in KG to arrive at the right answer.Despite the successes made in recent years, the existing works onanswering multi-hop complex question face the following challenges: i) suffering from poor performances due to the neglect of explicit relational chain order and its relational types reflected inuser questions; ii) failing to consider implicit relations between thetopic entity and the answer implied in structured KG because oflimited neighborhood size constraints in subgraph retrieval based algorithms. To address these issues in multi-hop KGQA, we proposea novel model in this paper, namely Relational Chain-based Embed-ded KGQA (Rce-KGQA), which simultaneously utilizes the explicitrelational chain described in natural language questions and the implicit relational chain stored in structured KG. Our extensiveempirical study on two open-domain benchmarks proves that ourmethod significantly outperforms the state-of-the-art counterpartslike GraftNet, PullNet and EmbedKGQA. Comprehensive ablation experiments also verify the effectiveness of our method for multi-hop KGQA tasks. We have made our model's source code availableat Github: https://github.com/albert-jin/Rce-KGQA.
CvT-ASSD: Convolutional vision-Transformer Based Attentive Single Shot MultiBox Detector
Oct 24, 2021



Due to the success of Bidirectional Encoder Representations from Transformers (BERT) in natural language process (NLP), the multi-head attention transformer has been more and more prevalent in computer-vision researches (CV). However, it still remains a challenge for researchers to put forward complex tasks such as vision detection and semantic segmentation. Although multiple Transformer-Based architectures like DETR and ViT-FRCNN have been proposed to complete object detection task, they inevitably decreases discrimination accuracy and brings down computational efficiency caused by the enormous learning parameters and heavy computational complexity incurred by the traditional self-attention operation. In order to alleviate these issues, we present a novel object detection architecture, named Convolutional vision Transformer Based Attentive Single Shot MultiBox Detector (CvT-ASSD), that built on the top of Convolutional vision Transormer (CvT) with the efficient Attentive Single Shot MultiBox Detector (ASSD). We provide comprehensive empirical evidence showing that our model CvT-ASSD can leads to good system efficiency and performance while being pretrained on large-scale detection datasets such as PASCAL VOC and MS COCO. Code has been released on public github repository at https://github.com/albert-jin/CvT-ASSD.