 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning of Depth and Ego-Motion from Video by Alternative Training and Geometric Constraints from 3D to 2D
Paper and Code
Aug 04, 2021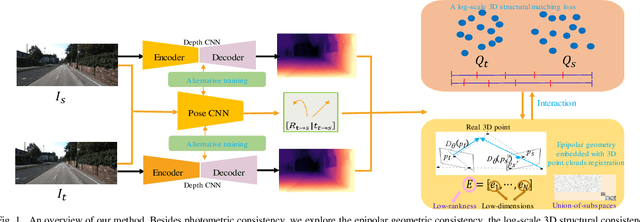
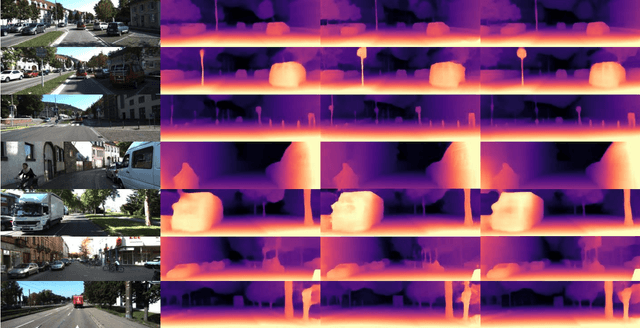
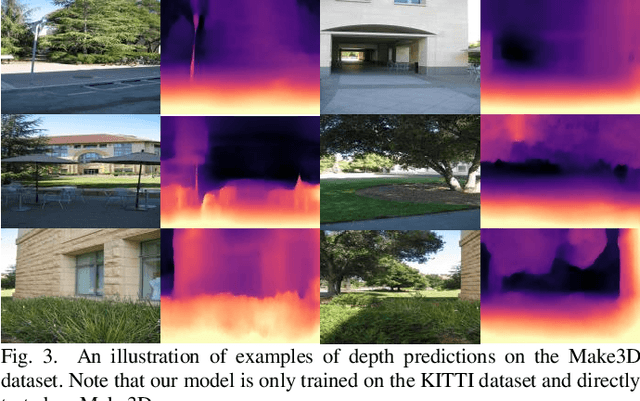
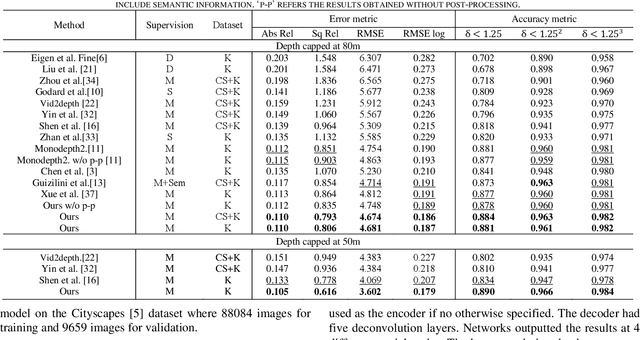
Self-supervised learning of depth and ego-motion from unlabeled monocular video has acquired promising results and drawn extensive attention. Most existing methods jointly train the depth and pose networks by photometric consistency of adjacent frames based on the principle of structure-from-motion (SFM). However, the coupling relationship of the depth and pose networks seriously influences the learning performance, and the re-projection relations is sensitive to scale ambiguity, especially for pose learning. In this paper, we aim to improve the depth-pose learning performance without the auxiliary tasks and address the above issues by alternative training each task and incorporating the epipolar geometric constraints into the Iterative Closest Point (ICP) based point clouds match process. Distinct from jointly training the depth and pose networks, our key idea is to better utilize the mutual dependency of these two tasks by alternatively training each network with respective losses while fixing the other. We also design a log-scale 3D structural consistency loss to put more emphasis on the smaller depth values during training. To makes the optimization easier, we further incorporate the epipolar geometry into the ICP based learning process for pose learning. Extensive experiments on various benchmarks datasets indicate the superiority of our algorithm over the state-of-the-art self-supervised methods.