 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-space Decomposition Model for Video Prediction Considering Long-term Motion Trend
Apr 17, 2024Stochastic video prediction enables the consideration of uncertainty in future motion, thereby providing a better reflection of the dynamic nature of the environment. Stochastic video prediction methods based on image auto-regressive recurrent models need to feed their predictions back into the latent space. Conversely, the state-space models, which decouple frame synthesis and temporal prediction, proves to be more efficient. However, inferring long-term temporal information about motion and generalizing to dynamic scenarios under non-stationary assumptions remains an unresolved challenge. In this paper, we propose a state-space decomposition stochastic video prediction model that decomposes the overall video frame generation into deterministic appearance prediction and stochastic motion prediction. Through adaptive decomposition, the model's generalization capability to dynamic scenarios is enhanced. In the context of motion prediction, obtaining a prior on the long-term trend of future motion is crucial. Thus, in the stochastic motion prediction branch, we infer the long-term motion trend from conditional frames to guide the generation of future frames that exhibit high consistency with the conditional frames. Experimental results demonstrate that our model outperforms baselines on multiple datasets.
Landmark Guided Active Exploration with Stable Low-level Policy Learning
Jun 30, 2023Goal-conditioned hierarchical reinforcement learning (GCHRL) decomposes long-horizon tasks into sub-tasks through a hierarchical framework and it has demonstrated promising results across a variety of domains. However, the high-level policy's action space is often excessively large, presenting a significant challenge to effective exploration and resulting in potentially inefficient training. Moreover, the dynamic variability of the low-level policy introduces non-stationarity to the high-level state transition function, significantly impeding the learning of the high-level policy. In this paper, we design a measure of prospect for subgoals by planning in the goal space based on the goal-conditioned value function. Building upon the measure of prospect, we propose a landmark-guided exploration strategy by integrating the measures of prospect and novelty which aims to guide the agent to explore efficiently and improve sample efficiency. To address the non-stationarity arising from the dynamic changes of the low-level policy, we apply a state-specific regularization to the learning of low-level policy, which facilitates stable learning of the hierarchical policy. The experimental results demonstrate that our proposed exploration strategy significantly outperforms the baseline methods across multiple tasks.
Self-supervised Learning of Occlusion Aware Flow Guided 3D Geometry Perception with Adaptive Cross Weighted Loss from Monocular Videos
Aug 10, 2021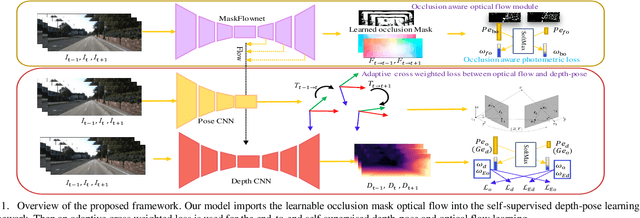
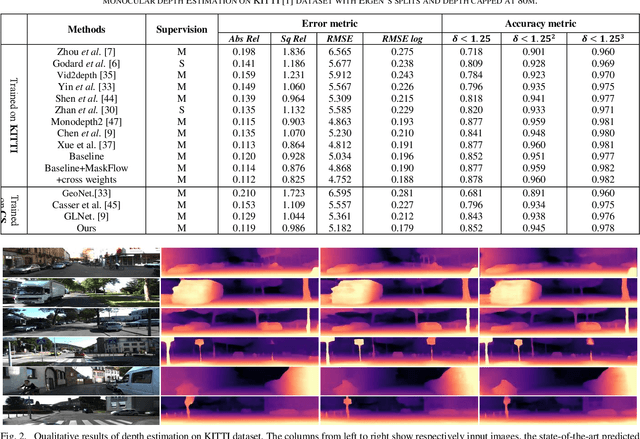
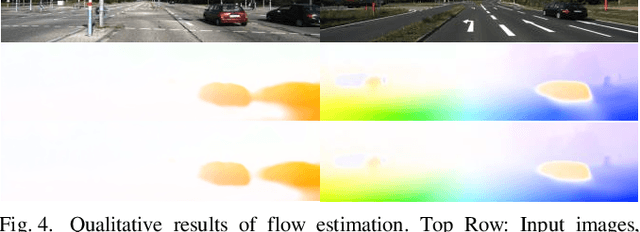
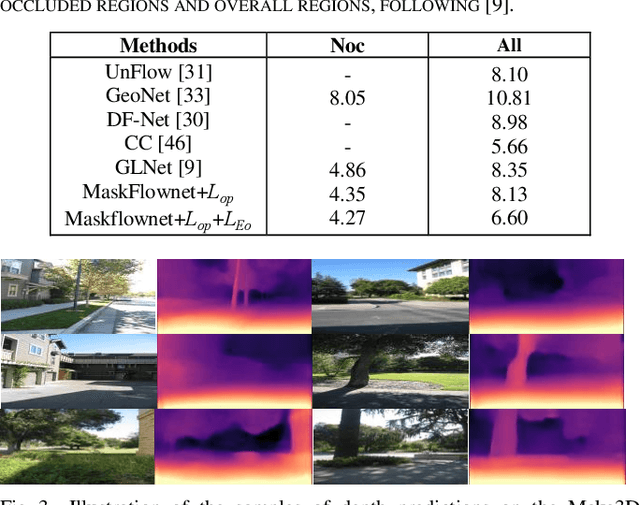
Self-supervised deep learning-based 3D scene understanding methods can overcome the difficulty of acquiring the densely labeled ground-truth and have made a lot of advances. However, occlusions and moving objects are still some of the major limitations. In this paper, we explore the learnable occlusion aware optical flow guided self-supervised depth and camera pose estimation by an adaptive cross weighted loss to address the above limitations. Firstly, we explore to train the learnable occlusion mask fused optical flow network by an occlusion-aware photometric loss with the temporally supplemental information and backward-forward consistency of adjacent views. And then, we design an adaptive cross-weighted loss between the depth-pose and optical flow loss of the geometric and photometric error to distinguish the moving objects which violate the static scene assumption. Our method shows promising results on KITTI, Make3D, and Cityscapes datasets under multiple tasks. We also show good generalization ability under a variety of challenging scenarios.
Self-Supervised Learning of Depth and Ego-Motion from Video by Alternative Training and Geometric Constraints from 3D to 2D
Aug 04, 2021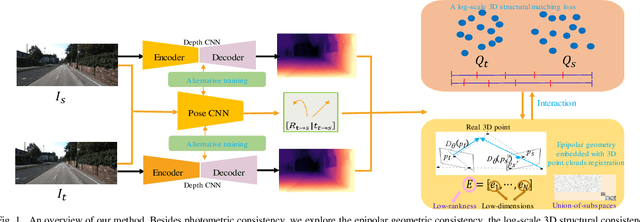
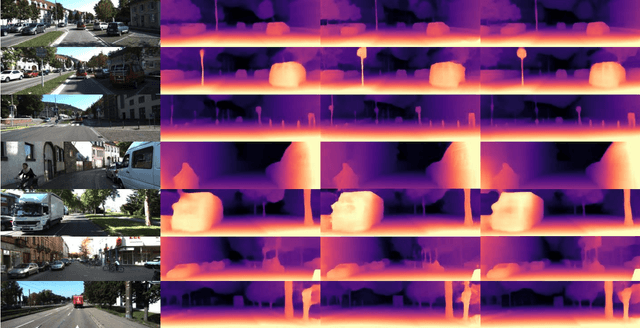
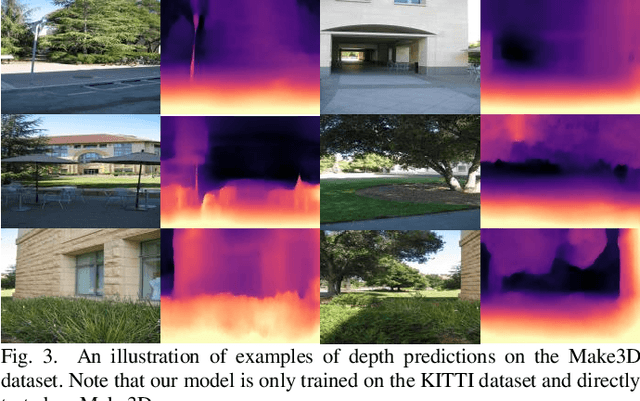
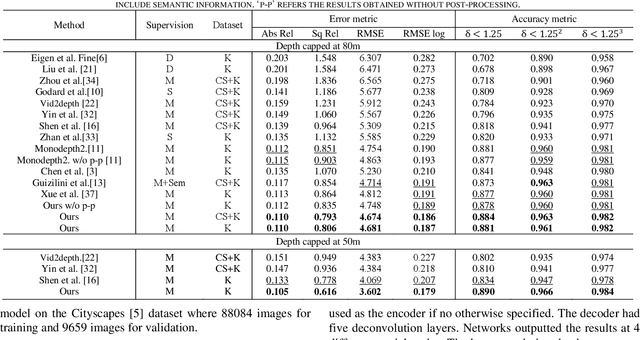
Self-supervised learning of depth and ego-motion from unlabeled monocular video has acquired promising results and drawn extensive attention. Most existing methods jointly train the depth and pose networks by photometric consistency of adjacent frames based on the principle of structure-from-motion (SFM). However, the coupling relationship of the depth and pose networks seriously influences the learning performance, and the re-projection relations is sensitive to scale ambiguity, especially for pose learning. In this paper, we aim to improve the depth-pose learning performance without the auxiliary tasks and address the above issues by alternative training each task and incorporating the epipolar geometric constraints into the Iterative Closest Point (ICP) based point clouds match process. Distinct from jointly training the depth and pose networks, our key idea is to better utilize the mutual dependency of these two tasks by alternatively training each network with respective losses while fixing the other. We also design a log-scale 3D structural consistency loss to put more emphasis on the smaller depth values during training. To makes the optimization easier, we further incorporate the epipolar geometry into the ICP based learning process for pose learning. Extensive experiments on various benchmarks datasets indicate the superiority of our algorithm over the state-of-the-art self-supervised methods.
Unsupervised Video Depth Estimation Based on Ego-motion and Disparity Consensus
Sep 03, 2019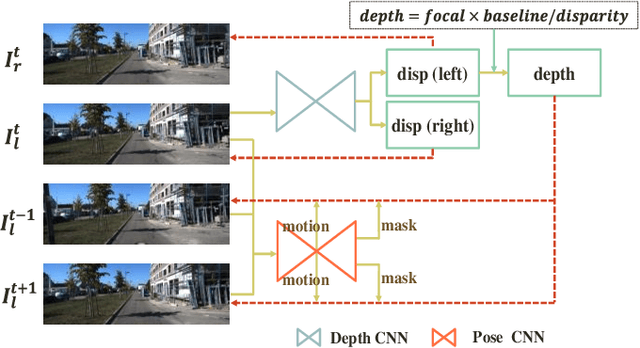
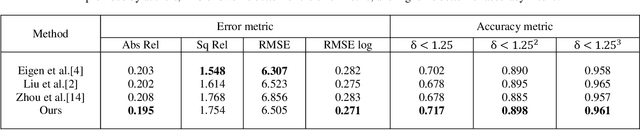
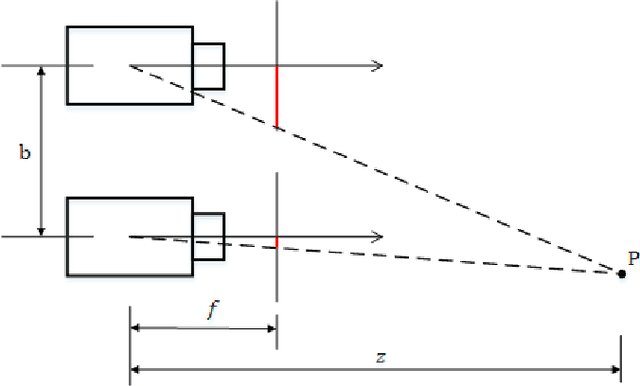

Unsupervised learning based depth estimation methods have received more and more attention as they do not need vast quantities of densely labeled data for training which are touch to acquire. In this paper, we propose a novel unsupervised monocular video depth estimation method in natural scenes by taking advantage of the state-of-the-art method of Zhou et al. which jointly estimates depth and camera motion. Our method advances beyond the baseline method by three aspects: 1) we add an additional signal as supervision to the baseline method by incorporating left-right binocular images reconstruction loss based on the estimated disparities, thus the left frame can be reconstructed by the temporal frames and right frames of stereo vision; 2) the network is trained by jointly using two kinds of view syntheses loss and left-right disparity consistency regularization to estimate depth and pose simultaneously; 3) we use the edge aware smooth L2 regularization to smooth the depth map while preserving the contour of the target. Extensive experiments on the KITTI autonomous driving dataset and Make3D dataset indicate the superiority of our algorithm in training efficiency. We can achieve competitive results with the baseline by only 3/5 times training data. The experimental results also show that our method even outperforms the classical supervised methods that using either ground truth depth or given pose for training.
3D Bounding Box Estimation for Autonomous Vehicles by Cascaded Geometric Constraints and Depurated 2D Detections Using 3D Results
Sep 01, 2019
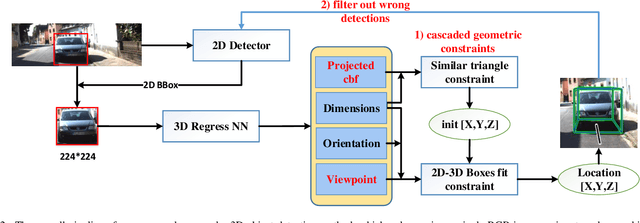
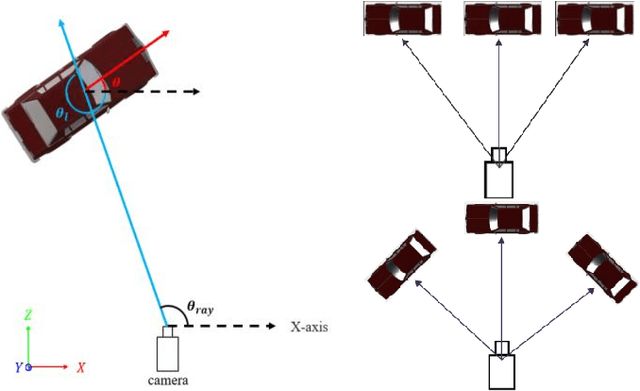
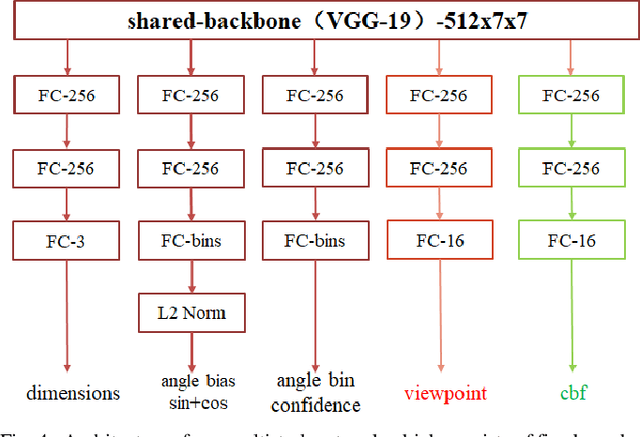
3D object detection is one of the most important tasks in 3D vision perceptual system of autonomous vehicles. In this paper, we propose a novel two stage 3D object detection method aimed at get the optimal solution of object location in 3D space based on regressing two additional 3D object properties by a deep convolutional neural network and combined with cascaded geometric constraints between the 2D and 3D boxes. First, we modify the existing 3D properties regressing network by adding two additional components, viewpoints classification and the center projection of the 3D bounding box s bottom face. Second, we use the predicted center projection combined with similar triangle constraint to acquire an initial 3D bounding box by a closed-form solution. Then, the location predicted by previous step is used as the initial value of the over-determined equations constructed by 2D and 3D boxes fitting constraint with the configuration determined with the classified viewpoint. Finally, we use the recovered physical world information by the 3D detections to filter out the false detection and false alarm in 2D detections. We compare our method with the state-of-the-arts on the KITTI dataset show that although conceptually simple, our method outperforms more complex and computational expensive methods not only by improving the overall precision of 3D detections, but also increasing the orientation estimation precision. Furthermore our method can deal with the truncated objects to some extent and remove the false alarm and false detections in both 2D and 3D detections.