 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Video Depth Estimation Based on Ego-motion and Disparity Consensus
Sep 03, 2019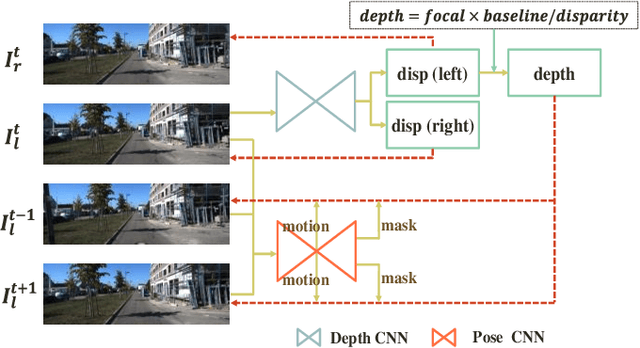
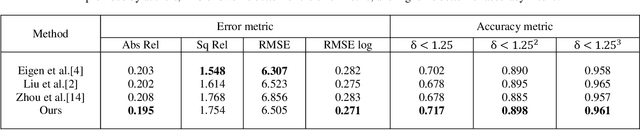
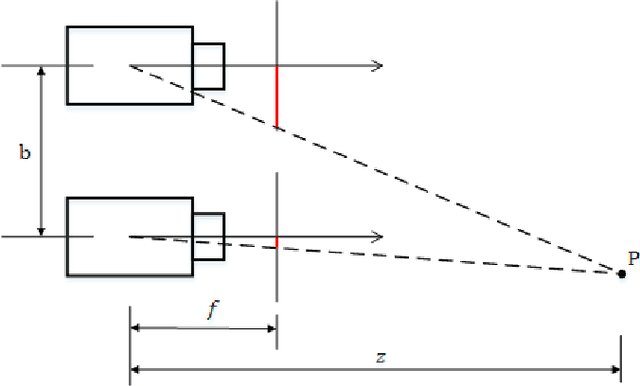

Unsupervised learning based depth estimation methods have received more and more attention as they do not need vast quantities of densely labeled data for training which are touch to acquire. In this paper, we propose a novel unsupervised monocular video depth estimation method in natural scenes by taking advantage of the state-of-the-art method of Zhou et al. which jointly estimates depth and camera motion. Our method advances beyond the baseline method by three aspects: 1) we add an additional signal as supervision to the baseline method by incorporating left-right binocular images reconstruction loss based on the estimated disparities, thus the left frame can be reconstructed by the temporal frames and right frames of stereo vision; 2) the network is trained by jointly using two kinds of view syntheses loss and left-right disparity consistency regularization to estimate depth and pose simultaneously; 3) we use the edge aware smooth L2 regularization to smooth the depth map while preserving the contour of the target. Extensive experiments on the KITTI autonomous driving dataset and Make3D dataset indicate the superiority of our algorithm in training efficiency. We can achieve competitive results with the baseline by only 3/5 times training data. The experimental results also show that our method even outperforms the classical supervised methods that using either ground truth depth or given pose for training.
3D Bounding Box Estimation for Autonomous Vehicles by Cascaded Geometric Constraints and Depurated 2D Detections Using 3D Results
Sep 01, 2019
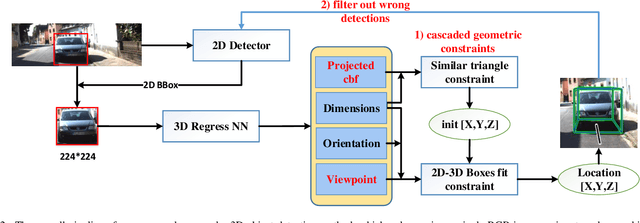
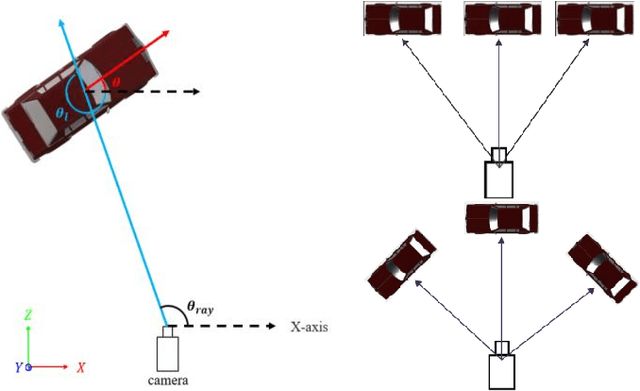
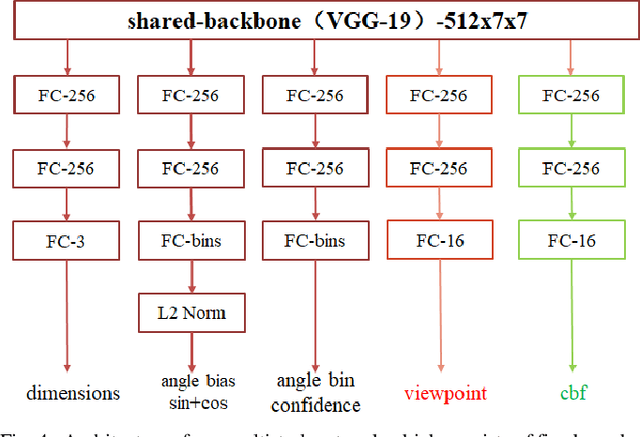
3D object detection is one of the most important tasks in 3D vision perceptual system of autonomous vehicles. In this paper, we propose a novel two stage 3D object detection method aimed at get the optimal solution of object location in 3D space based on regressing two additional 3D object properties by a deep convolutional neural network and combined with cascaded geometric constraints between the 2D and 3D boxes. First, we modify the existing 3D properties regressing network by adding two additional components, viewpoints classification and the center projection of the 3D bounding box s bottom face. Second, we use the predicted center projection combined with similar triangle constraint to acquire an initial 3D bounding box by a closed-form solution. Then, the location predicted by previous step is used as the initial value of the over-determined equations constructed by 2D and 3D boxes fitting constraint with the configuration determined with the classified viewpoint. Finally, we use the recovered physical world information by the 3D detections to filter out the false detection and false alarm in 2D detections. We compare our method with the state-of-the-arts on the KITTI dataset show that although conceptually simple, our method outperforms more complex and computational expensive methods not only by improving the overall precision of 3D detections, but also increasing the orientation estimation precision. Furthermore our method can deal with the truncated objects to some extent and remove the false alarm and false detections in both 2D and 3D detections.