 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Video Depth Estimation Based on Ego-motion and Disparity Consensus
Paper and Code
Sep 03, 2019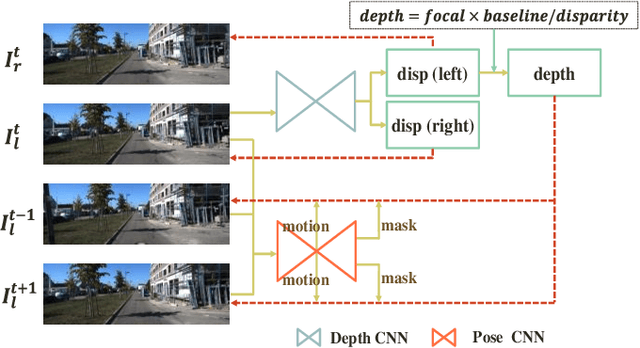
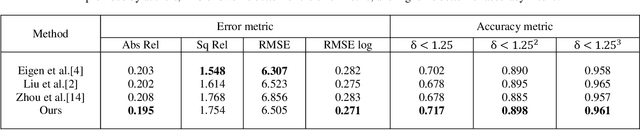
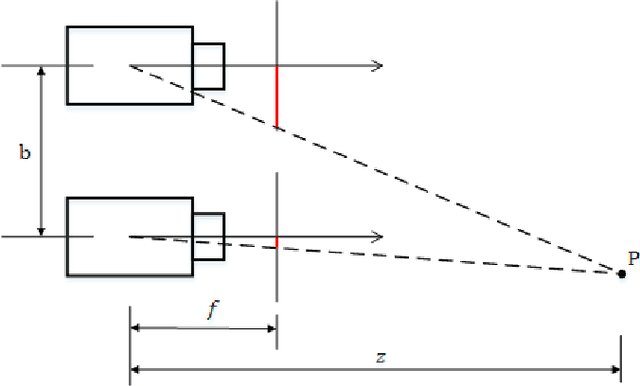

Unsupervised learning based depth estimation methods have received more and more attention as they do not need vast quantities of densely labeled data for training which are touch to acquire. In this paper, we propose a novel unsupervised monocular video depth estimation method in natural scenes by taking advantage of the state-of-the-art method of Zhou et al. which jointly estimates depth and camera motion. Our method advances beyond the baseline method by three aspects: 1) we add an additional signal as supervision to the baseline method by incorporating left-right binocular images reconstruction loss based on the estimated disparities, thus the left frame can be reconstructed by the temporal frames and right frames of stereo vision; 2) the network is trained by jointly using two kinds of view syntheses loss and left-right disparity consistency regularization to estimate depth and pose simultaneously; 3) we use the edge aware smooth L2 regularization to smooth the depth map while preserving the contour of the target. Extensive experiments on the KITTI autonomous driving dataset and Make3D dataset indicate the superiority of our algorithm in training efficiency. We can achieve competitive results with the baseline by only 3/5 times training data. The experimental results also show that our method even outperforms the classical supervised methods that using either ground truth depth or given pose for training.