 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTALENT: Target-aware Efficient Tuning for Referring Image Segmentation
Apr 01, 2026Referring image segmentation aims to segment specific targets based on a natural text expression. Recently, parameter-efficient tuning (PET) has emerged as a promising paradigm. However, existing PET-based methods often suffer from the fact that visual features can't emphasize the text-referred target instance but activate co-category yet unrelated objects. We analyze and quantify this problem, terming it the `non-target activation' (NTA) issue. To address this, we propose a novel framework, TALENT, which utilizes target-aware efficient tuning for PET-based RIS. Specifically, we first propose a Rectified Cost Aggregator (RCA) to efficiently aggregate text-referred features. Then, to calibrate `NTA' into accurate target activation, we adopt a Target-aware Learning Mechanism (TLM), including contextual pairwise consistency learning and target-centric contrastive learning. The former uses the sentence-level text feature to achieve a holistic understanding of the referent and constructs a text-referred affinity map to optimize the semantic association of visual features. The latter further enhances target localization to discover the distinct instance while suppressing associations with other unrelated ones. The two objectives work in concert and address `NTA' effectively. Extensive evaluations show that TALENT outperforms existing methods across various metrics (e.g., 2.5\% mIoU gains on G-Ref val set). Our codes will be released at: https://github.com/Kimsure/TALENT.
TF-SSD: A Strong Pipeline via Synergic Mask Filter for Training-free Co-salient Object Detection
Apr 01, 2026Co-salient Object Detection (CoSOD) aims to segment salient objects that consistently appear across a group of related images. Despite the notable progress achieved by recent training-based approaches, they still remain constrained by the closed-set datasets and exhibit limited generalization. However, few studies explore the potential of Vision Foundation Models (VFMs) to address CoSOD, which demonstrate a strong generalized ability and robust saliency understanding. In this paper, we investigate and leverage VFMs for CoSOD, and further propose a novel training-free method, TF-SSD, through the synergy between SAM and DINO. Specifically, we first utilize SAM to generate comprehensive raw proposals, which serve as a candidate mask pool. Then, we introduce a quality mask generator to filter out redundant masks, thereby acquiring a refined mask set. Since this generator is built upon SAM, it inherently lacks semantic understanding of saliency. To this end, we adopt an intra-image saliency filter that employs DINO's attention maps to identify visually salient masks within individual images. Moreover, to extend saliency understanding across group images, we propose an inter-image prototype selector, which computes similarity scores among cross-image prototypes to select masks with the highest score. These selected masks serve as final predictions for CoSOD. Extensive experiments show that our TF-SSD outperforms existing methods (e.g., 13.7\% gains over the recent training-free method). Codes are available at https://github.com/hzz-yy/TF-SSD.
Precision in Practice: Knowledge Guided Code Summarizing Grounded in Industrial Expectations
Feb 03, 2026Code summaries are essential for helping developers understand code functionality and reducing maintenance and collaboration costs. Although recent advances in large language models (LLMs) have significantly improved automatic code summarization, the practical usefulness of generated summaries in industrial settings remains insufficiently explored. In collaboration with documentation experts from the industrial HarmonyOS project, we conducted a questionnaire study showing that over 57.4% of code summaries produced by state-of-the-art approaches were rejected due to violations of developers' expectations for industrial documentation. Beyond semantic similarity to reference summaries, developers emphasize additional requirements, including the use of appropriate domain terminology, explicit function categorization, and the avoidance of redundant implementation details. To address these expectations, we propose ExpSum, an expectation-aware code summarization approach that integrates function metadata abstraction, informative metadata filtering, context-aware domain knowledge retrieval, and constraint-driven prompting to guide LLMs in generating structured, expectation-aligned summaries. We evaluate ExpSum on the HarmonyOS project and widely used code summarization benchmarks. Experimental results show that ExpSum consistently outperforms all baselines, achieving improvements of up to 26.71% in BLEU-4 and 20.10% in ROUGE-L on HarmonyOS. Furthermore, LLM-based evaluations indicate that ExpSum-generated summaries better align with developer expectations across other projects, demonstrating its effectiveness for industrial code documentation.
Medical Multimodal Foundation Models in Clinical Diagnosis and Treatment: Applications, Challenges, and Future Directions
Dec 03, 2024



Recent advancements in deep learning have significantly revolutionized the field of clinical diagnosis and treatment, offering novel approaches to improve diagnostic precision and treatment efficacy across diverse clinical domains, thus driving the pursuit of precision medicine. The growing availability of multi-organ and multimodal datasets has accelerated the development of large-scale Medical Multimodal Foundation Models (MMFMs). These models, known for their strong generalization capabilities and rich representational power, are increasingly being adapted to address a wide range of clinical tasks, from early diagnosis to personalized treatment strategies. This review offers a comprehensive analysis of recent developments in MMFMs, focusing on three key aspects: datasets, model architectures, and clinical applications. We also explore the challenges and opportunities in optimizing multimodal representations and discuss how these advancements are shaping the future of healthcare by enabling improved patient outcomes and more efficient clinical workflows.
Temporal Consistency Learning of inter-frames for Video Super-Resolution
Nov 03, 2022Video super-resolution (VSR) is a task that aims to reconstruct high-resolution (HR) frames from the low-resolution (LR) reference frame and multiple neighboring frames. The vital operation is to utilize the relative misaligned frames for the current frame reconstruction and preserve the consistency of the results. Existing methods generally explore information propagation and frame alignment to improve the performance of VSR. However, few studies focus on the temporal consistency of inter-frames. In this paper, we propose a Temporal Consistency learning Network (TCNet) for VSR in an end-to-end manner, to enhance the consistency of the reconstructed videos. A spatio-temporal stability module is designed to learn the self-alignment from inter-frames. Especially, the correlative matching is employed to exploit the spatial dependency from each frame to maintain structural stability. Moreover, a self-attention mechanism is utilized to learn the temporal correspondence to implement an adaptive warping operation for temporal consistency among multi-frames. Besides, a hybrid recurrent architecture is designed to leverage short-term and long-term information. We further present a progressive fusion module to perform a multistage fusion of spatio-temporal features. And the final reconstructed frames are refined by these fused features. Objective and subjective results of various experiments demonstrate that TCNet has superior performance on different benchmark datasets, compared to several state-of-the-art methods.
Dense residual Transformer for image denoising
May 14, 2022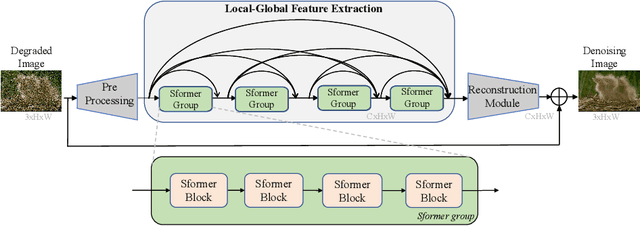
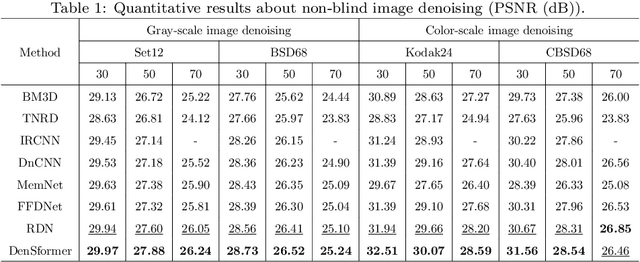
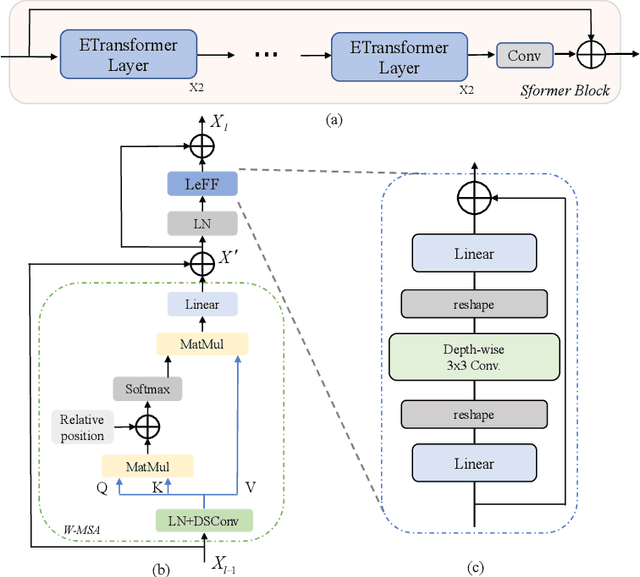
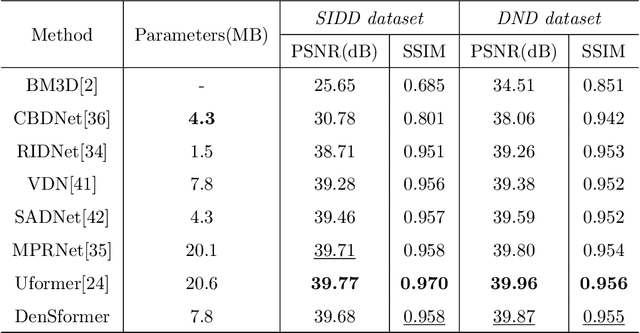
Image denoising is an important low-level computer vision task, which aims to reconstruct a noise-free and high-quality image from a noisy image. With the development of deep learning, convolutional neural network (CNN) has been gradually applied and achieved great success in image denoising, image compression, image enhancement, etc. Recently, Transformer has been a hot technique, which is widely used to tackle computer vision tasks. However, few Transformer-based methods have been proposed for low-level vision tasks. In this paper, we proposed an image denoising network structure based on Transformer, which is named DenSformer. DenSformer consists of three modules, including a preprocessing module, a local-global feature extraction module, and a reconstruction module. Specifically, the local-global feature extraction module consists of several Sformer groups, each of which has several ETransformer layers and a convolution layer, together with a residual connection. These Sformer groups are densely skip-connected to fuse the feature of different layers, and they jointly capture the local and global information from the given noisy images. We conduct our model on comprehensive experiments. Experimental results prove that our DenSformer achieves improvement compared to some state-of-the-art methods, both for the synthetic noise data and real noise data, in the objective and subjective evaluations.
RefineCap: Concept-Aware Refinement for Image Captioning
Sep 08, 2021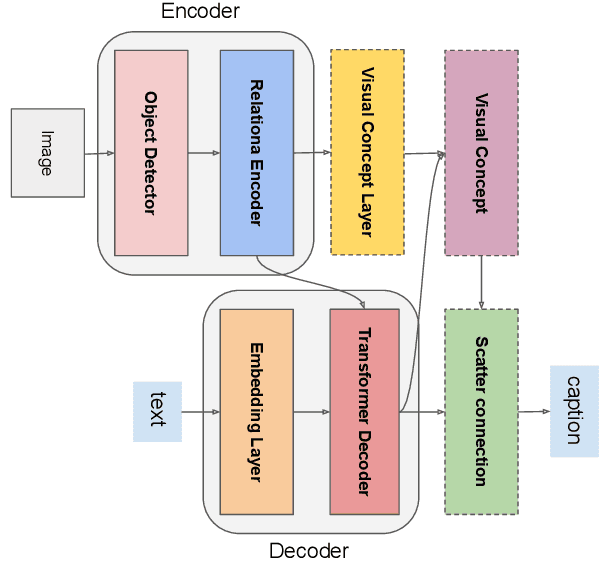
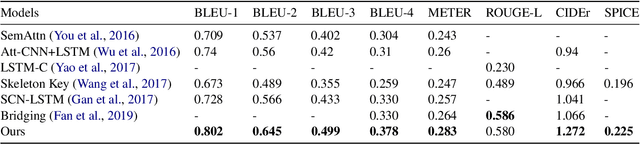

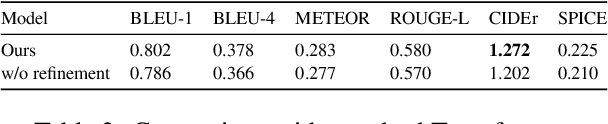
Automatically translating images to texts involves image scene understanding and language modeling. In this paper, we propose a novel model, termed RefineCap, that refines the output vocabulary of the language decoder using decoder-guided visual semantics, and implicitly learns the mapping between visual tag words and images. The proposed Visual-Concept Refinement method can allow the generator to attend to semantic details in the image, thereby generating more semantically descriptive captions. Our model achieves superior performance on the MS-COCO dataset in comparison with previous visual-concept based models.
Neural Text Classification by Jointly Learning to Cluster and Align
Nov 24, 2020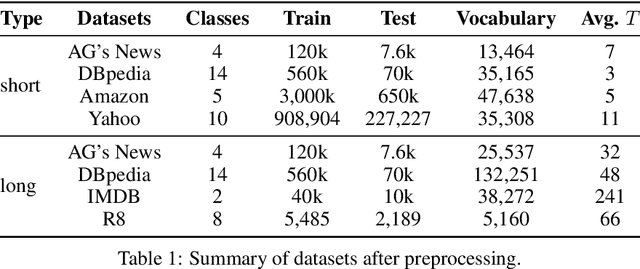
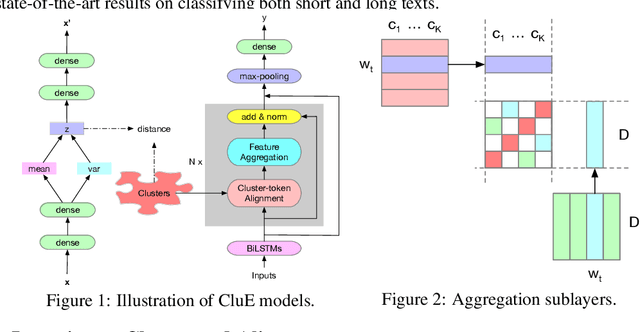
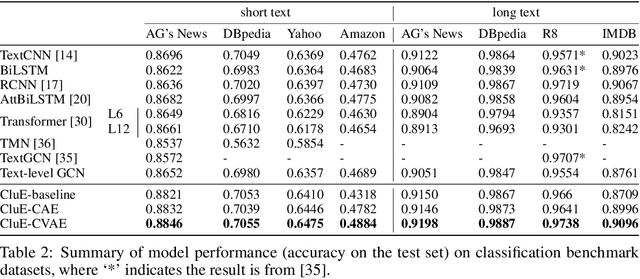

Distributional text clustering delivers semantically informative representations and captures the relevance between each word and semantic clustering centroids. We extend the neural text clustering approach to text classification tasks by inducing cluster centers via a latent variable model and interacting with distributional word embeddings, to enrich the representation of tokens and measure the relatedness between tokens and each learnable cluster centroid. The proposed method jointly learns word clustering centroids and clustering-token alignments, achieving the state of the art results on multiple benchmark datasets and proving that the proposed cluster-token alignment mechanism is indeed favorable to text classification. Notably, our qualitative analysis has conspicuously illustrated that text representations learned by the proposed model are in accord well with our intuition.
COVID-19 Chest CT Image Segmentation -- A Deep Convolutional Neural Network Solution
Apr 26, 2020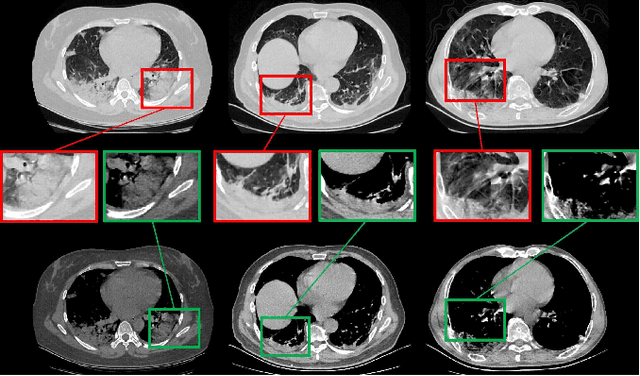
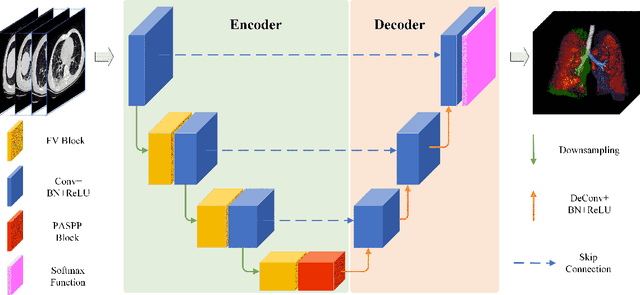
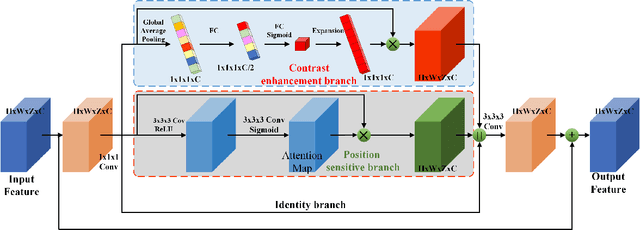
A novel coronavirus disease 2019 (COVID-19) was detected and has spread rapidly across various countries around the world since the end of the year 2019, Computed Tomography (CT) images have been used as a crucial alternative to the time-consuming RT-PCR test. However, pure manual segmentation of CT images faces a serious challenge with the increase of suspected cases, resulting in urgent requirements for accurate and automatic segmentation of COVID-19 infections. Unfortunately, since the imaging characteristics of the COVID-19 infection are diverse and similar to the backgrounds, existing medical image segmentation methods cannot achieve satisfactory performance. In this work, we try to establish a new deep convolutional neural network tailored for segmenting the chest CT images with COVID-19 infections. We firstly maintain a large and new chest CT image dataset consisting of 165,667 annotated chest CT images from 861 patients with confirmed COVID-19. Inspired by the observation that the boundary of the infected lung can be enhanced by adjusting the global intensity, in the proposed deep CNN, we introduce a feature variation block which adaptively adjusts the global properties of the features for segmenting COVID-19 infection. The proposed FV block can enhance the capability of feature representation effectively and adaptively for diverse cases. We fuse features at different scales by proposing Progressive Atrous Spatial Pyramid Pooling to handle the sophisticated infection areas with diverse appearance and shapes. We conducted experiments on the data collected in China and Germany and show that the proposed deep CNN can produce impressive performance effectively.
Motion Imitation Based on Sparsely Sampled Correspondence
Jul 25, 2016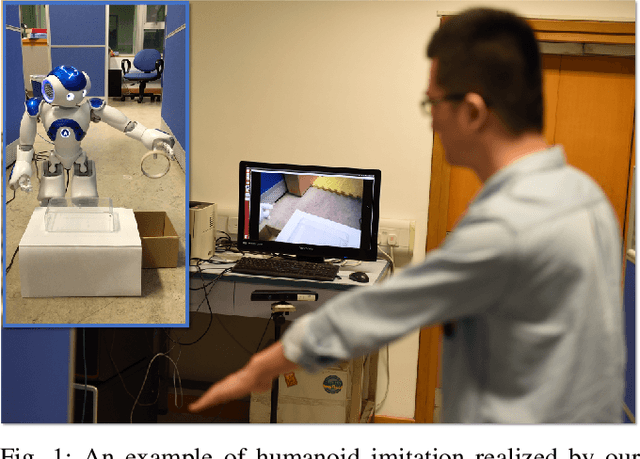
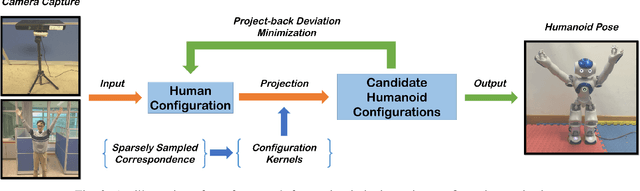
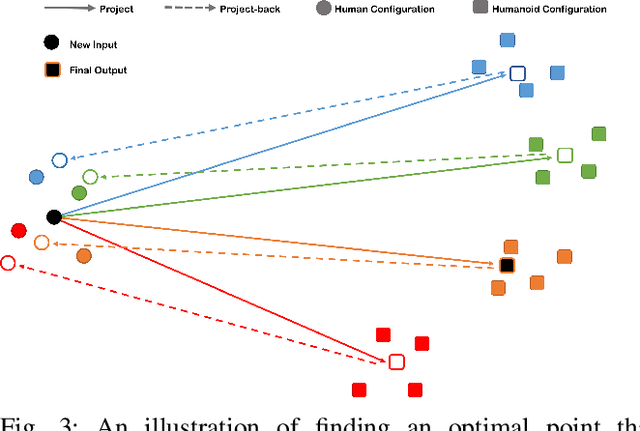
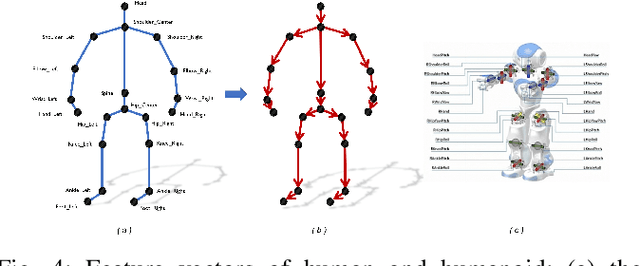
Existing techniques for motion imitation often suffer a certain level of latency due to their computational overhead or a large set of correspondence samples to search. To achieve real-time imitation with small latency, we present a framework in this paper to reconstruct motion on humanoids based on sparsely sampled correspondence. The imitation problem is formulated as finding the projection of a point from the configuration space of a human's poses into the configuration space of a humanoid. An optimal projection is defined as the one that minimizes a back-projected deviation among a group of candidates, which can be determined in a very efficient way. Benefited from this formulation, effective projections can be obtained by using sparse correspondence. Methods for generating these sparse correspondence samples have also been introduced. Our method is evaluated by applying the human's motion captured by a RGB-D sensor to a humanoid in real-time. Continuous motion can be realized and used in the example application of tele-operation.