 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deep Clustering of Human Activities from Wearables
Aug 19, 2020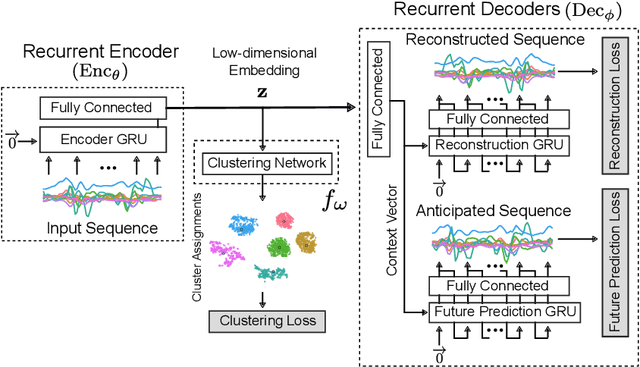
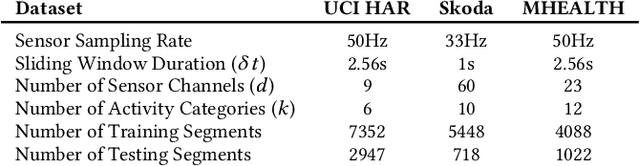
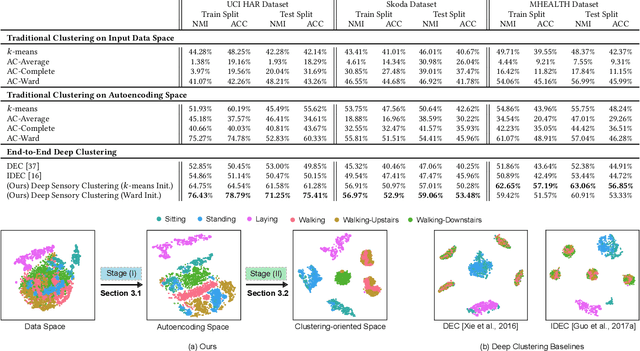
Our ability to exploit low-cost wearable sensing modalities for critical human behaviour and activity monitoring applications in health and wellness is reliant on supervised learning regimes; here, deep learning paradigms have proven extremely successful in learning activity representations from annotated data. However, the costly work of gathering and annotating sensory activity datasets is labor-intensive, time consuming and not scalable to large volumes of data. While existing unsupervised remedies of deep clustering leverage network architectures and optimization objectives that are tailored for static image datasets, deep architectures to uncover cluster structures from raw sequence data captured by on-body sensors remains largely unexplored. In this paper, we develop an unsupervised end-to-end learning strategy for the fundamental problem of human activity recognition (HAR) from wearables. Through extensive experiments, including comparisons with existing methods, we show the effectiveness of our approach to jointly learn unsupervised representations for sensory data and generate cluster assignments with strong semantic correspondence to distinct human activities.
Attend And Discriminate: Beyond the State-of-the-Art for Human Activity Recognition using Wearable Sensors
Jul 14, 2020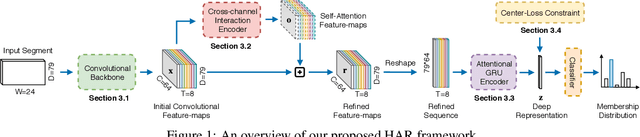

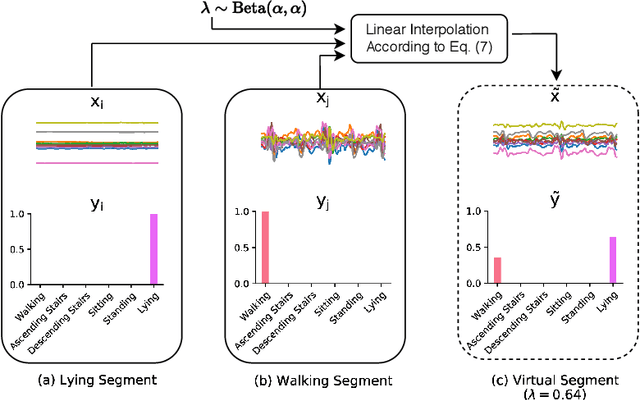
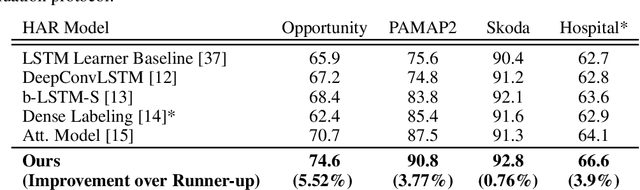
Wearables are fundamental to improving our understanding of human activities, especially for an increasing number of healthcare applications from rehabilitation to fine-grained gait analysis. Although our collective know-how to solve Human Activity Recognition (HAR) problems with wearables has progressed immensely with end-to-end deep learning paradigms, several fundamental opportunities remain overlooked. We rigorously explore these new opportunities to learn enriched and highly discriminating activity representations. We propose: i) learning to exploit the latent relationships between multi-channel sensor modalities and specific activities; ii) investigating the effectiveness of data-agnostic augmentation for multi-modal sensor data streams to regularize deep HAR models; and iii) incorporating a classification loss criterion to encourage minimal intra-class representation differences whilst maximising inter-class differences to achieve more discriminative features. Our contributions achieves new state-of-the-art performance on four diverse activity recognition problem benchmarks with large margins -- with up to 6% relative margin improvement. We extensively validate the contributions from our design concepts through extensive experiments, including activity misalignment measures, ablation studies and insights shared through both quantitative and qualitative studies.
COVID-19 Chest CT Image Segmentation -- A Deep Convolutional Neural Network Solution
Apr 26, 2020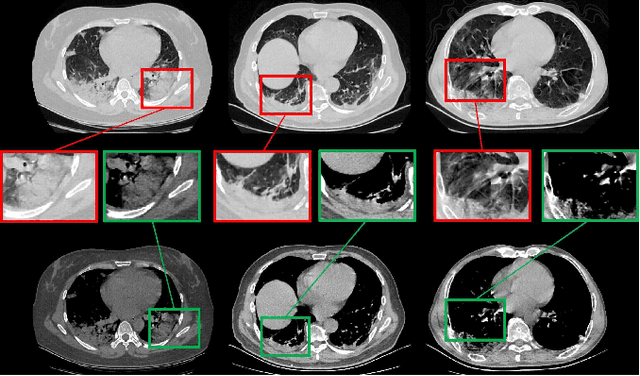
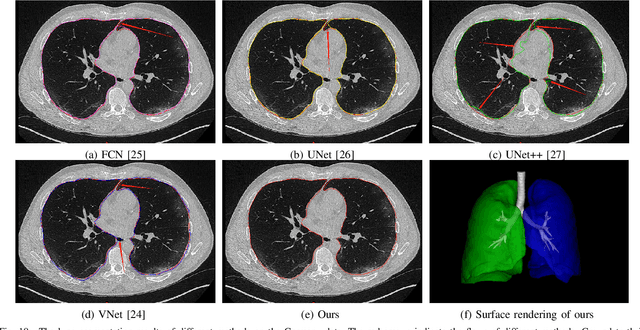
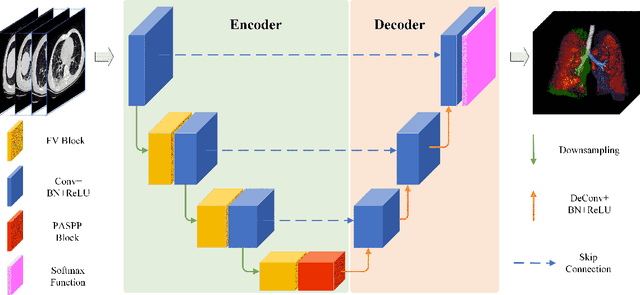
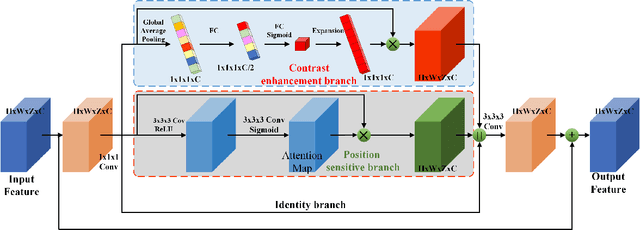
A novel coronavirus disease 2019 (COVID-19) was detected and has spread rapidly across various countries around the world since the end of the year 2019, Computed Tomography (CT) images have been used as a crucial alternative to the time-consuming RT-PCR test. However, pure manual segmentation of CT images faces a serious challenge with the increase of suspected cases, resulting in urgent requirements for accurate and automatic segmentation of COVID-19 infections. Unfortunately, since the imaging characteristics of the COVID-19 infection are diverse and similar to the backgrounds, existing medical image segmentation methods cannot achieve satisfactory performance. In this work, we try to establish a new deep convolutional neural network tailored for segmenting the chest CT images with COVID-19 infections. We firstly maintain a large and new chest CT image dataset consisting of 165,667 annotated chest CT images from 861 patients with confirmed COVID-19. Inspired by the observation that the boundary of the infected lung can be enhanced by adjusting the global intensity, in the proposed deep CNN, we introduce a feature variation block which adaptively adjusts the global properties of the features for segmenting COVID-19 infection. The proposed FV block can enhance the capability of feature representation effectively and adaptively for diverse cases. We fuse features at different scales by proposing Progressive Atrous Spatial Pyramid Pooling to handle the sophisticated infection areas with diverse appearance and shapes. We conducted experiments on the data collected in China and Germany and show that the proposed deep CNN can produce impressive performance effectively.
Learn to Predict Sets Using Feed-Forward Neural Networks
Jan 30, 2020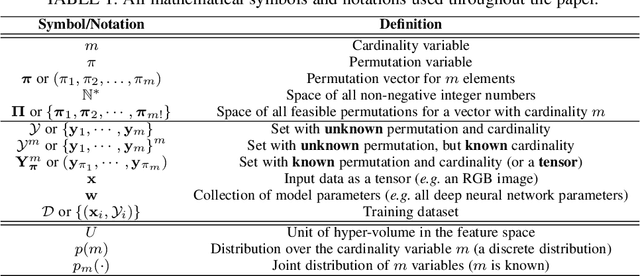
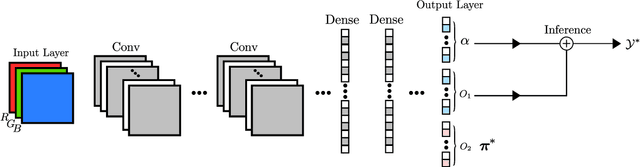
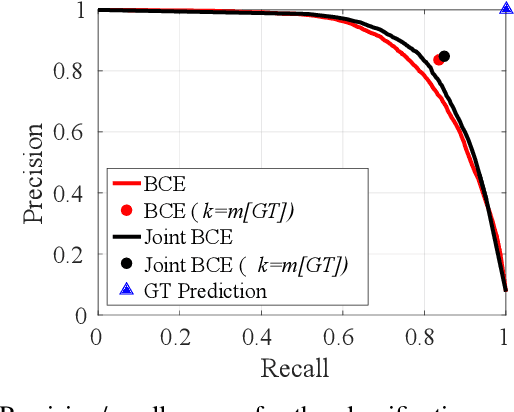

This paper addresses the task of set prediction using deep feed-forward neural networks. A set is a collection of elements which is invariant under permutation and the size of a set is not fixed in advance. Many real-world problems, such as image tagging and object detection, have outputs that are naturally expressed as sets of entities. This creates a challenge for traditional deep neural networks which naturally deal with structured outputs such as vectors, matrices or tensors. We present a novel approach for learning to predict sets with unknown permutation and cardinality using deep neural networks. In our formulation we define a likelihood for a set distribution represented by a) two discrete distributions defining the set cardinally and permutation variables, and b) a joint distribution over set elements with a fixed cardinality. Depending on the problem under consideration, we define different training models for set prediction using deep neural networks. We demonstrate the validity of our set formulations on relevant vision problems such as: 1)multi-label image classification where we achieve state-of-the-art performance on the PASCAL VOC and MS COCO datasets, 2) object detection, for which our formulation outperforms state-of-the-art detectors such as Faster R-CNN and YOLO v3, and 3) a complex CAPTCHA test, where we observe that, surprisingly, our set-based network acquired the ability of mimicking arithmetics without any rules being coded.
Learning to Zoom-in via Learning to Zoom-out: Real-world Super-resolution by Generating and Adapting Degradation
Jan 08, 2020


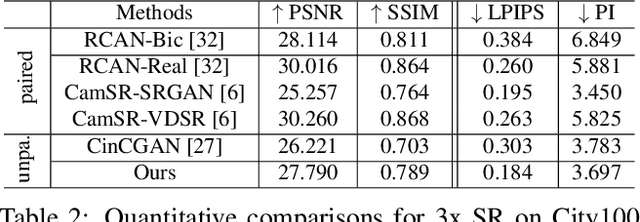
Most learning-based super-resolution (SR) methods aim to recover high-resolution (HR) image from a given low-resolution (LR) image via learning on LR-HR image pairs. The SR methods learned on synthetic data do not perform well in real-world, due to the domain gap between the artificially synthesized and real LR images. Some efforts are thus taken to capture real-world image pairs. The captured LR-HR image pairs usually suffer from unavoidable misalignment, which hampers the performance of end-to-end learning, however. Here, focusing on the real-world SR, we ask a different question: since misalignment is unavoidable, can we propose a method that does not need LR-HR image pairing and alignment at all and utilize real images as they are? Hence we propose a framework to learn SR from an arbitrary set of unpaired LR and HR images and see how far a step can go in such a realistic and "unsupervised" setting. To do so, we firstly train a degradation generation network to generate realistic LR images and, more importantly, to capture their distribution (i.e., learning to zoom out). Instead of assuming the domain gap has been eliminated, we minimize the discrepancy between the generated data and real data while learning a degradation adaptive SR network (i.e., learning to zoom in). The proposed unpaired method achieves state-of-the-art SR results on real-world images, even in the datasets that favor the paired-learning methods more.
Creating Auxiliary Representations from Charge Definitions for Criminal Charge Prediction
Nov 12, 2019
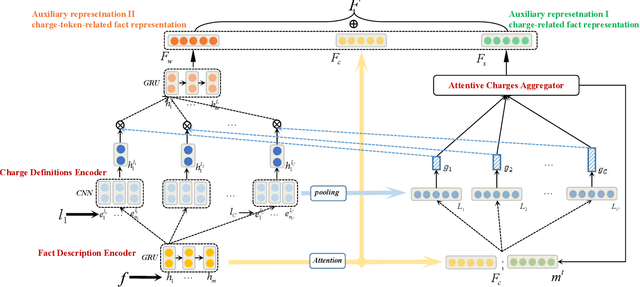
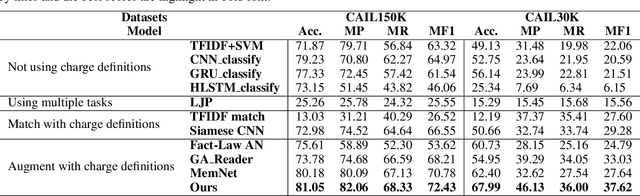
Charge prediction, determining charges for criminal cases by analyzing the textual fact descriptions, is a promising technology in legal assistant systems. In practice, the fact descriptions could exhibit a significant intra-class variation due to factors like non-normative use of language, which makes the prediction task very challenging, especially for charge classes with too few samples to cover the expression variation. In this work, we explore to use the charge definitions from criminal law to alleviate this issue. The key idea is that the expressions in a fact description should have corresponding formal terms in charge definitions, and those terms are shared across classes and could account for the diversity in the fact descriptions. Thus, we propose to create auxiliary fact representations from charge definitions to augment fact descriptions representation. The generated auxiliary representations are created through the interaction of fact description with the relevant charge definitions and terms in those definitions by integrated sentence- and word-level attention scheme. Experimental results on two datasets show that our model achieves significant improvement than baselines, especially for classes with few samples.
Gradient Information Guided Deraining with A Novel Network and Adversarial Training
Oct 09, 2019



In recent years, deep learning based methods have made significant progress in rain-removing. However, the existing methods usually do not have good generalization ability, which leads to the fact that almost all of existing methods have a satisfied performance on removing a specific type of rain streaks, but may have a relatively poor performance on other types of rain streaks. In this paper, aiming at removing multiple types of rain streaks from single images, we propose a novel deraining framework (GRASPP-GAN), which has better generalization capacity. Specifically, a modified ResNet-18 which extracts the deep features of rainy images and a revised ASPP structure which adapts to the various shapes and sizes of rain streaks are composed together to form the backbone of our deraining network. Taking the more prominent characteristics of rain streaks in the gradient domain into consideration, a gradient loss is introduced to help to supervise our deraining training process, for which, a Sobel convolution layer is built to extract the gradient information flexibly. To further boost the performance, an adversarial learning scheme is employed for the first time to train the proposed network. Extensive experiments on both real-world and synthetic datasets demonstrate that our method outperforms the state-of-the-art deraining methods quantitatively and qualitatively. In addition, without any modifications, our proposed framework also achieves good visual performance on dehazing.
Adaptive Neuro-Surrogate-Based Optimisation Method for Wave Energy Converters Placement Optimisation
Jul 09, 2019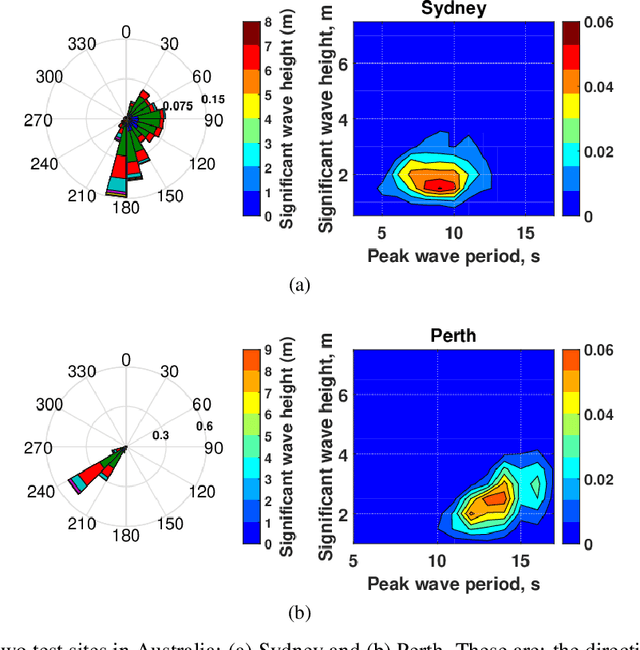
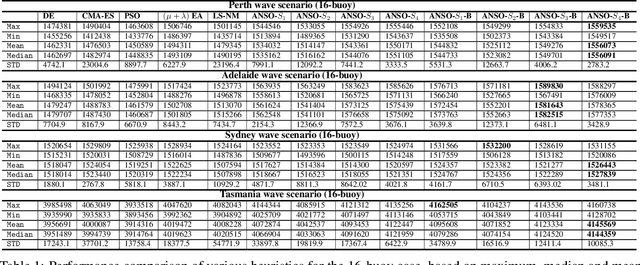
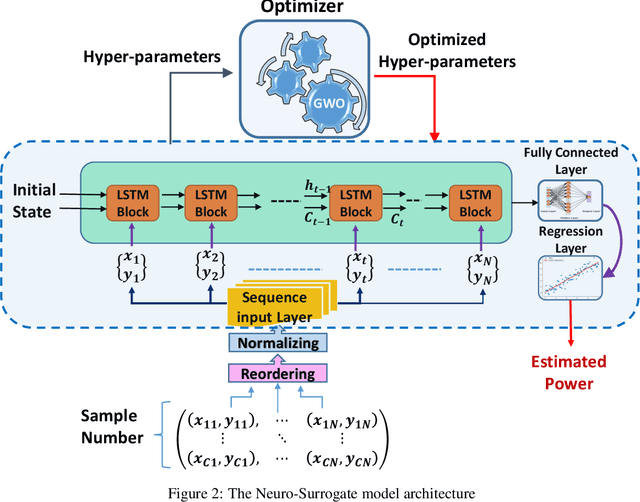
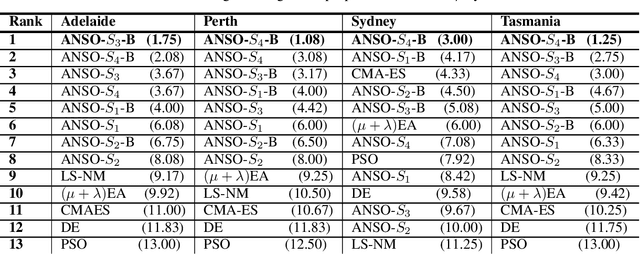
The installed amount of renewable energy has expanded massively in recent years. Wave energy, with its high capacity factors has great potential to complement established sources of solar and wind energy. This study explores the problem of optimising the layout of advanced, three-tether wave energy converters in a size-constrained farm in a numerically modelled ocean environment. Simulating and computing the complicated hydrodynamic interactions in wave farms can be computationally costly, which limits optimisation methods to have just a few thousand evaluations. For dealing with this expensive optimisation problem, an adaptive neuro-surrogate optimisation (ANSO) method is proposed that consists of a surrogate Recurrent Neural Network (RNN) model trained with a very limited number of observations. This model is coupled with a fast meta-heuristic optimiser for adjusting the model's hyper-parameters. The trained model is applied using a greedy local search with a backtracking optimisation strategy. For evaluating the performance of the proposed approach, some of the more popular and successful Evolutionary Algorithms (EAs) are compared in four real wave scenarios (Sydney, Perth, Adelaide and Tasmania). Experimental results show that the adaptive neuro model is competitive with other optimisation methods in terms of total harnessed power output and faster in terms of total computational costs.
Deep Single Image Deraining Via Estimating Transmission and Atmospheric Light in rainy Scenes
Jun 22, 2019
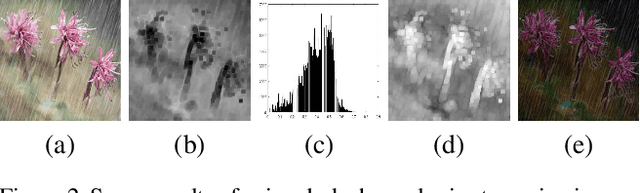

Rain removal in images/videos is still an important task in computer vision field and attracting attentions of more and more people. Traditional methods always utilize some incomplete priors or filters (e.g. guided filter) to remove rain effect. Deep learning gives more probabilities to better solve this task. However, they remove rain either by evaluating background from rainy image directly or learning a rain residual first then subtracting the residual to obtain a clear background. No other models are used in deep learning based de-raining methods to remove rain and obtain other information about rainy scenes. In this paper, we utilize an extensively-used image degradation model which is derived from atmospheric scattering principles to model the formation of rainy images and try to learn the transmission, atmospheric light in rainy scenes and remove rain further. To reach this goal, we propose a robust evaluation method of global atmospheric light in a rainy scene. Instead of using the estimated atmospheric light directly to learn a network to calculate transmission, we utilize it as ground truth and design a simple but novel triangle-shaped network structure to learn atmospheric light for every rainy image, then fine-tune the network to obtain a better estimation of atmospheric light during the training of transmission network. Furthermore, more efficient ShuffleNet Units are utilized in transmission network to learn transmission map and the de-raining image is then obtained by the image degradation model. By subjective and objective comparisons, our method outperforms the selected state-of-the-art works.
SparseSense: Human Activity Recognition from Highly Sparse Sensor Data-streams Using Set-based Neural Networks
Jun 06, 2019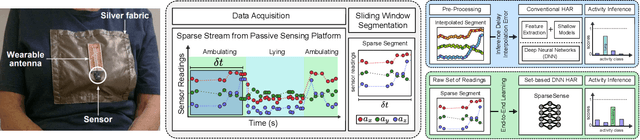
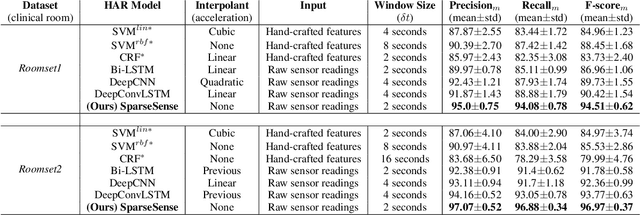
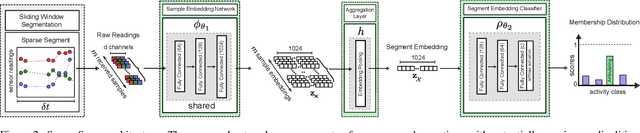
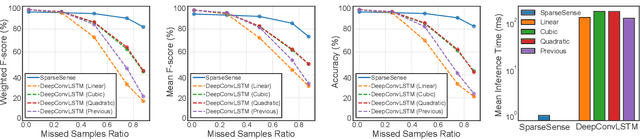
Batteryless or so called passive wearables are providing new and innovative methods for human activity recognition (HAR), especially in healthcare applications for older people. Passive sensors are low cost, lightweight, unobtrusive and desirably disposable; attractive attributes for healthcare applications in hospitals and nursing homes. Despite the compelling propositions for sensing applications, the data streams from these sensors are characterised by high sparsity---the time intervals between sensor readings are irregular while the number of readings per unit time are often limited. In this paper, we rigorously explore the problem of learning activity recognition models from temporally sparse data. We describe how to learn directly from sparse data using a deep learning paradigm in an end-to-end manner. We demonstrate significant classification performance improvements on real-world passive sensor datasets from older people over the state-of-the-art deep learning human activity recognition models. Further, we provide insights into the model's behaviour through complementary experiments on a benchmark dataset and visualisation of the learned activity feature spaces.