 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOTChallenge: A Benchmark for Single-camera Multiple Target Tracking
Oct 15, 2020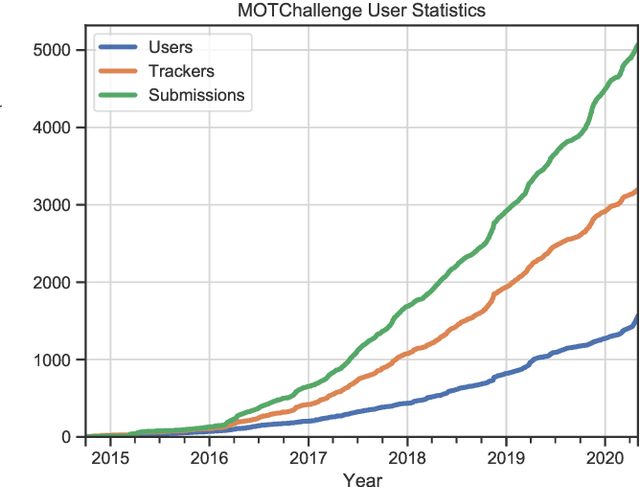
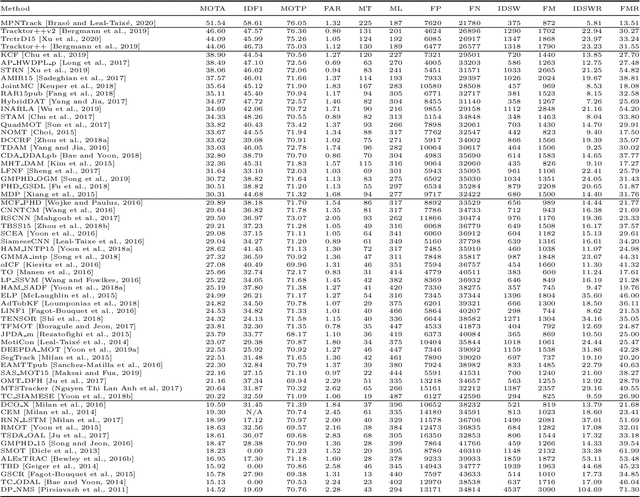

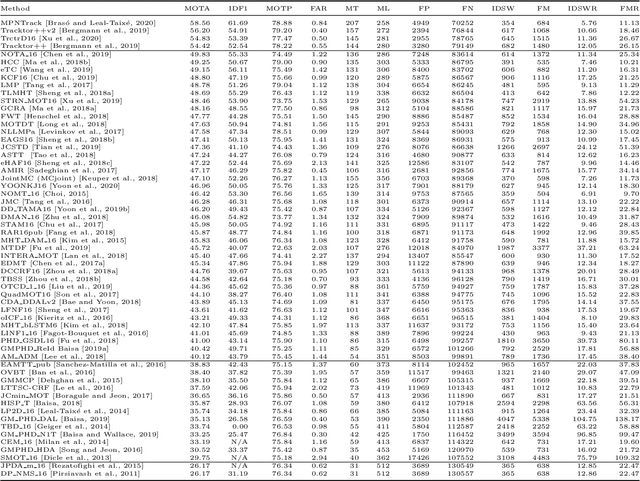
Standardized benchmarks have been crucial in pushing the performance of computer vision algorithms, especially since the advent of deep learning. Although leaderboards should not be over-claimed, they often provide the most objective measure of performance and are therefore important guides for research. We present MOTChallenge, a benchmark for single-camera Multiple Object Tracking (MOT) launched in late 2014, to collect existing and new data, and create a framework for the standardized evaluation of multiple object tracking methods. The benchmark is focused on multiple people tracking, since pedestrians are by far the most studied object in the tracking community, with applications ranging from robot navigation to self-driving cars. This paper collects the first three releases of the benchmark: (i) MOT15, along with numerous state-of-the-art results that were submitted in the last years, (ii) MOT16, which contains new challenging videos, and (iii) MOT17, that extends MOT16 sequences with more precise labels and evaluates tracking performance on three different object detectors. The second and third release not only offers a significant increase in the number of labeled boxes but also provide labels for multiple object classes beside pedestrians, as well as the level of visibility for every single object of interest. We finally provide a categorization of state-of-the-art trackers and a broad error analysis. This will help newcomers understand the related work and research trends in the MOT community, and hopefully shred some light into potential future research directions.
MOT20: A benchmark for multi object tracking in crowded scenes
Mar 19, 2020
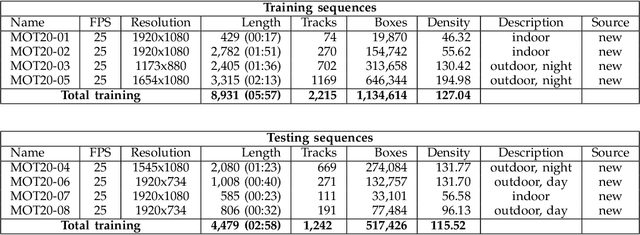

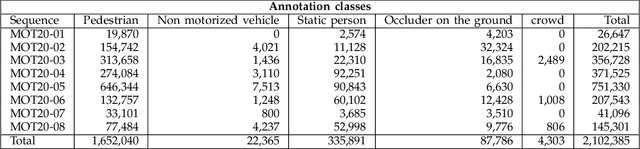
Standardized benchmarks are crucial for the majority of computer vision applications. Although leaderboards and ranking tables should not be over-claimed, benchmarks often provide the most objective measure of performance and are therefore important guides for research. The benchmark for Multiple Object Tracking, MOTChallenge, was launched with the goal to establish a standardized evaluation of multiple object tracking methods. The challenge focuses on multiple people tracking, since pedestrians are well studied in the tracking community, and precise tracking and detection has high practical relevance. Since the first release, MOT15, MOT16, and MOT17 have tremendously contributed to the community by introducing a clean dataset and precise framework to benchmark multi-object trackers. In this paper, we present our MOT20benchmark, consisting of 8 new sequences depicting very crowded challenging scenes. The benchmark was presented first at the 4thBMTT MOT Challenge Workshop at the Computer Vision and Pattern Recognition Conference (CVPR) 2019, and gives to chance to evaluate state-of-the-art methods for multiple object tracking when handling extremely crowded scenarios.
Learn to Predict Sets Using Feed-Forward Neural Networks
Jan 30, 2020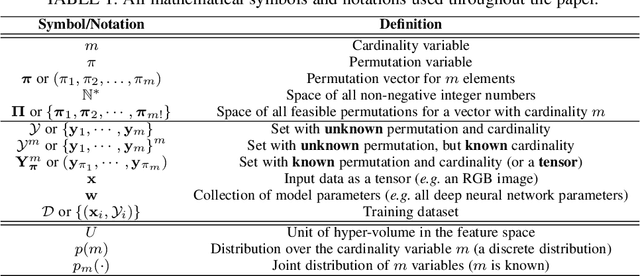
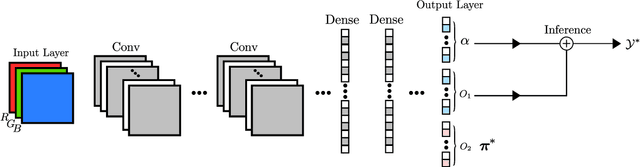
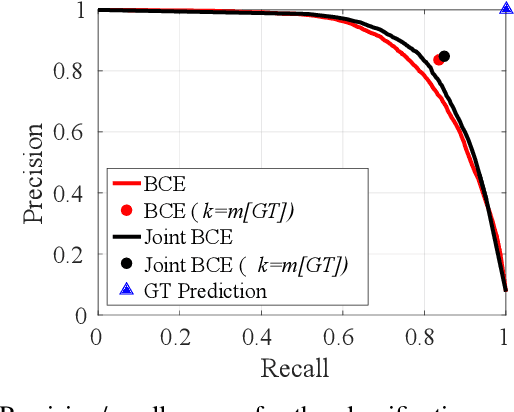

This paper addresses the task of set prediction using deep feed-forward neural networks. A set is a collection of elements which is invariant under permutation and the size of a set is not fixed in advance. Many real-world problems, such as image tagging and object detection, have outputs that are naturally expressed as sets of entities. This creates a challenge for traditional deep neural networks which naturally deal with structured outputs such as vectors, matrices or tensors. We present a novel approach for learning to predict sets with unknown permutation and cardinality using deep neural networks. In our formulation we define a likelihood for a set distribution represented by a) two discrete distributions defining the set cardinally and permutation variables, and b) a joint distribution over set elements with a fixed cardinality. Depending on the problem under consideration, we define different training models for set prediction using deep neural networks. We demonstrate the validity of our set formulations on relevant vision problems such as: 1)multi-label image classification where we achieve state-of-the-art performance on the PASCAL VOC and MS COCO datasets, 2) object detection, for which our formulation outperforms state-of-the-art detectors such as Faster R-CNN and YOLO v3, and 3) a complex CAPTCHA test, where we observe that, surprisingly, our set-based network acquired the ability of mimicking arithmetics without any rules being coded.
CVPR19 Tracking and Detection Challenge: How crowded can it get?
Jun 10, 2019
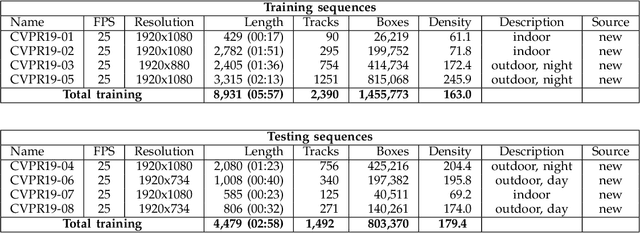

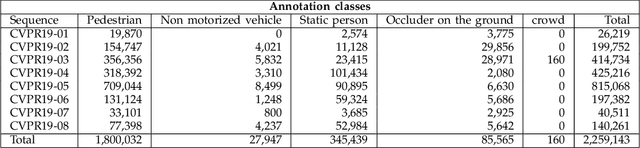
Standardized benchmarks are crucial for the majority of computer vision applications. Although leaderboards and ranking tables should not be over-claimed, benchmarks often provide the most objective measure of performance and are therefore important guides for research. The benchmark for Multiple Object Tracking, MOTChallenge, was launched with the goal to establish a standardized evaluation of multiple object tracking methods. The challenge focuses on multiple people tracking, since pedestrians are well studied in the tracking community, and precise tracking and detection has high practical relevance. Since the first release, MOT15, MOT16 and MOT17 have tremendously contributed to the community by introducing a clean dataset and precise framework to benchmark multi-object trackers. In this paper, we present our CVPR19 benchmark, consisting of 8 new sequences depicting very crowded challenging scenes. The benchmark will be presented at the 4th BMTT MOT Challenge Workshop at the Computer Vision and Pattern Recognition Conference (CVPR) 2019, and will evaluate the state-of-the-art in multiple object tracking whend handling extremely crowded scenarios.
RGB-D Object Detection and Semantic Segmentation for Autonomous Manipulation in Clutter
Oct 01, 2018
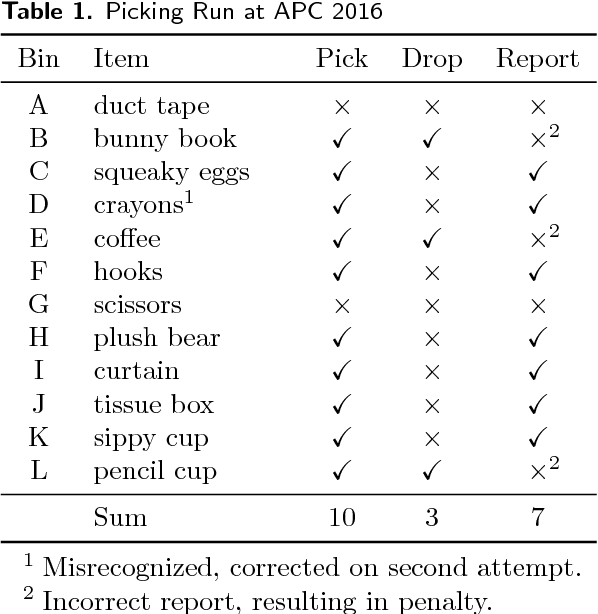
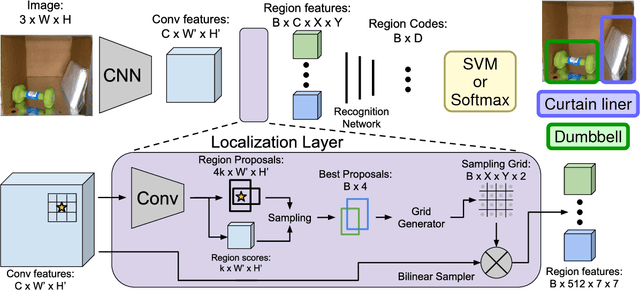
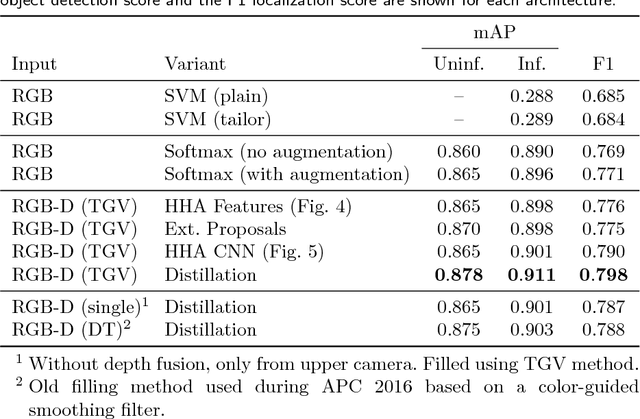
Autonomous robotic manipulation in clutter is challenging. A large variety of objects must be perceived in complex scenes, where they are partially occluded and embedded among many distractors, often in restricted spaces. To tackle these challenges, we developed a deep-learning approach that combines object detection and semantic segmentation. The manipulation scenes are captured with RGB-D cameras, for which we developed a depth fusion method. Employing pretrained features makes learning from small annotated robotic data sets possible. We evaluate our approach on two challenging data sets: one captured for the Amazon Picking Challenge 2016, where our team NimbRo came in second in the Stowing and third in the Picking task, and one captured in disaster-response scenarios. The experiments show that object detection and semantic segmentation complement each other and can be combined to yield reliable object perception.
Mechanical Design of a Cartesian Manipulator for Warehouse Pick and Place
Jun 18, 2018
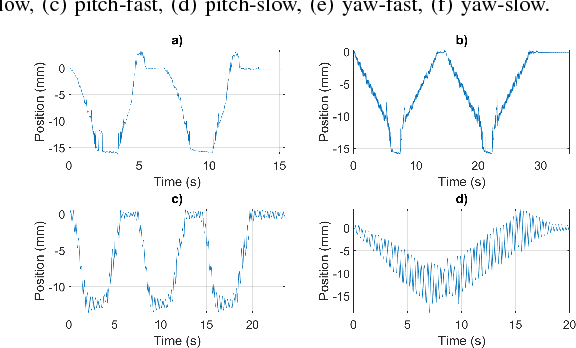
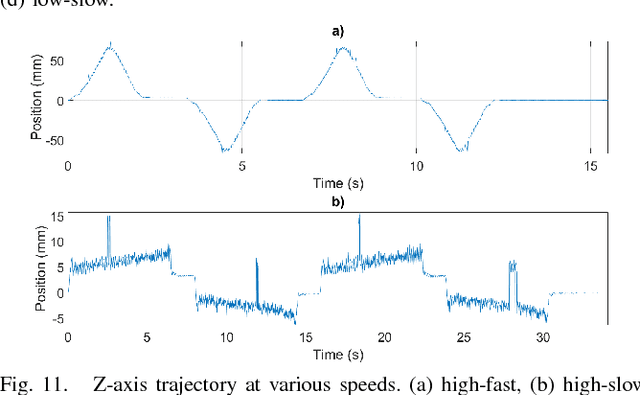
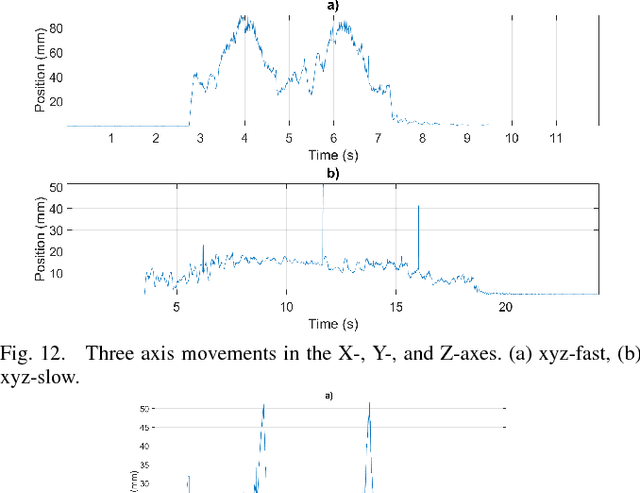
Robotic manipulation and grasping in cluttered and unstructured environments is a current challenge for robotics. Enabling robots to operate in these challenging environments have direct applications from automating warehouses to harvesting fruit in agriculture. One of the main challenges associated with these difficult robotic manipulation tasks is the motion planning and control problem for multi-DoF (Degree of Freedom) manipulators. This paper presents the design and performance evaluation of a low-cost Cartesian manipulator, Cartman who took first place in the Amazon Robotics Challenge 2017. It can perform pick and place tasks of household items in a cluttered environment. The robot is capable of linear speeds of 1 m/s and angular speeds of 1.5 rad/s, capable of sub-millimetre static accuracy and safe payload capacity of 2kg. Cartman can be produced for under 10 000 AUD. The complete design is open sourced and can be found at http://juxi.net/projects/AmazonRoboticsChallenge.
PoseTrack: A Benchmark for Human Pose Estimation and Tracking
Apr 10, 2018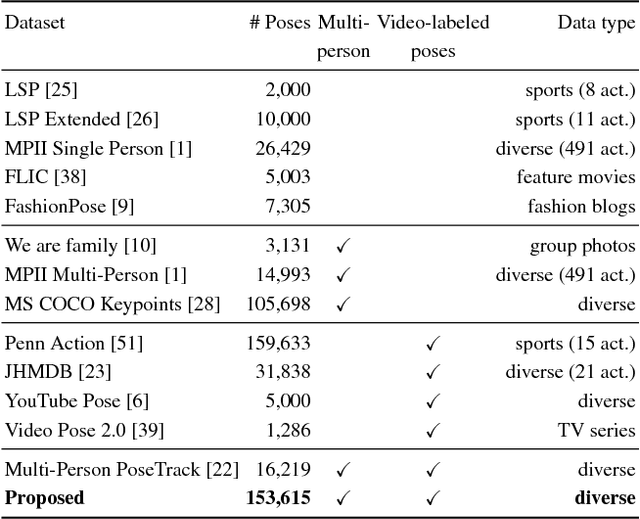


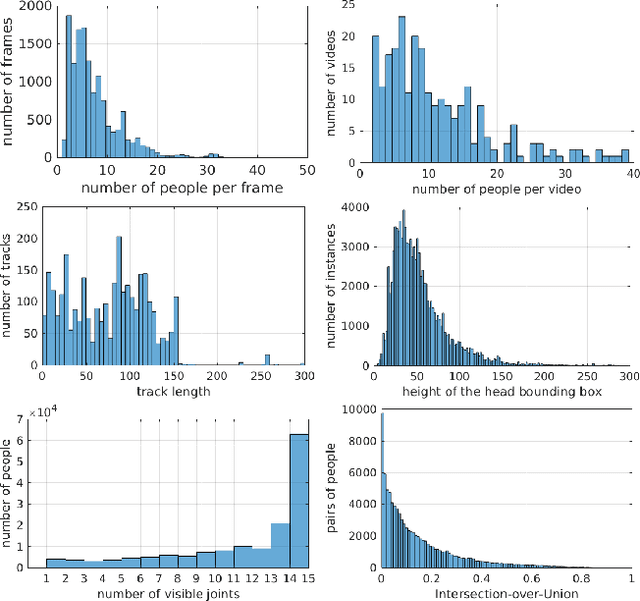
Human poses and motions are important cues for analysis of videos with people and there is strong evidence that representations based on body pose are highly effective for a variety of tasks such as activity recognition, content retrieval and social signal processing. In this work, we aim to further advance the state of the art by establishing "PoseTrack", a new large-scale benchmark for video-based human pose estimation and articulated tracking, and bringing together the community of researchers working on visual human analysis. The benchmark encompasses three competition tracks focusing on i) single-frame multi-person pose estimation, ii) multi-person pose estimation in videos, and iii) multi-person articulated tracking. To facilitate the benchmark and challenge we collect, annotate and release a new %large-scale benchmark dataset that features videos with multiple people labeled with person tracks and articulated pose. A centralized evaluation server is provided to allow participants to evaluate on a held-out test set. We envision that the proposed benchmark will stimulate productive research both by providing a large and representative training dataset as well as providing a platform to objectively evaluate and compare the proposed methods. The benchmark is freely accessible at https://posetrack.net.
Joint Learning of Set Cardinality and State Distribution
Nov 21, 2017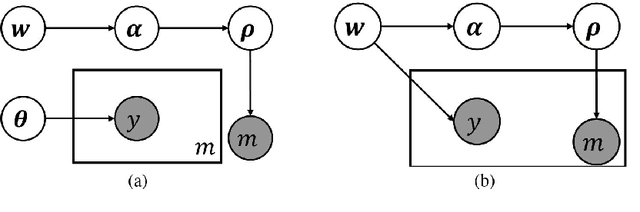
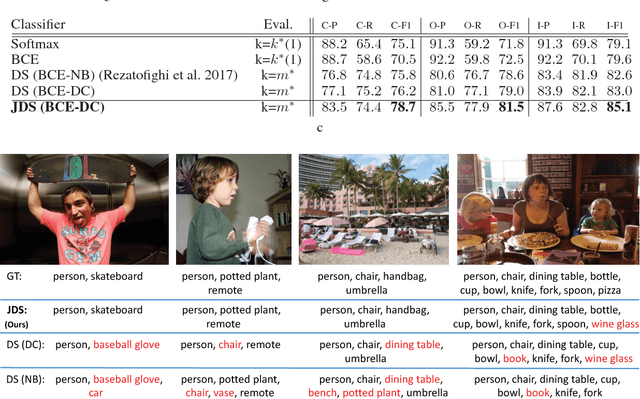
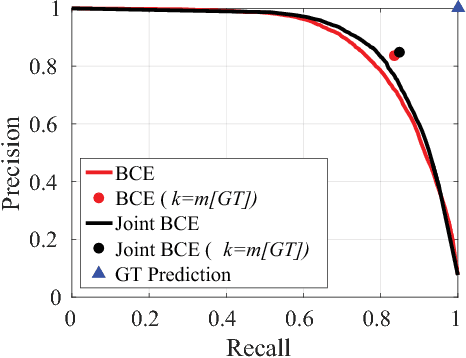
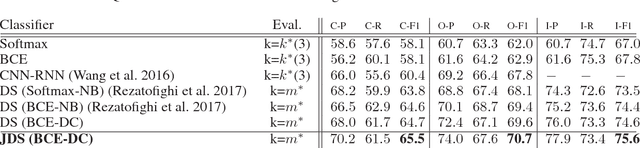
We present a novel approach for learning to predict sets using deep learning. In recent years, deep neural networks have shown remarkable results in computer vision, natural language processing and other related problems. Despite their success, traditional architectures suffer from a serious limitation in that they are built to deal with structured input and output data, i.e. vectors or matrices. Many real-world problems, however, are naturally described as sets, rather than vectors. Existing techniques that allow for sequential data, such as recurrent neural networks, typically heavily depend on the input and output order and do not guarantee a valid solution. Here, we derive in a principled way, a mathematical formulation for set prediction where the output is permutation invariant. In particular, our approach jointly learns both the cardinality and the state distribution of the target set. We demonstrate the validity of our method on the task of multi-label image classification and achieve a new state of the art on the PASCAL VOC and MS COCO datasets.
DeepSetNet: Predicting Sets with Deep Neural Networks
Aug 11, 2017
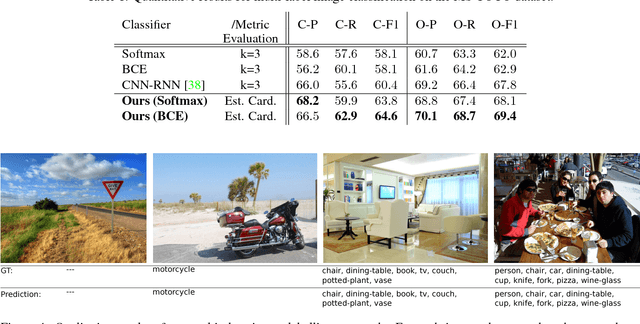
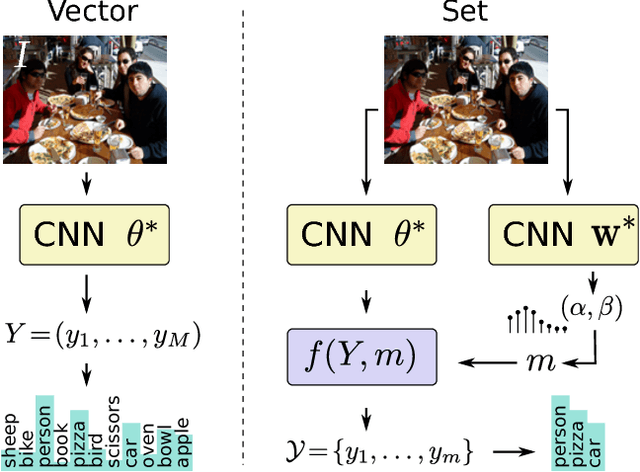

This paper addresses the task of set prediction using deep learning. This is important because the output of many computer vision tasks, including image tagging and object detection, are naturally expressed as sets of entities rather than vectors. As opposed to a vector, the size of a set is not fixed in advance, and it is invariant to the ordering of entities within it. We define a likelihood for a set distribution and learn its parameters using a deep neural network. We also derive a loss for predicting a discrete distribution corresponding to set cardinality. Set prediction is demonstrated on the problem of multi-class image classification. Moreover, we show that the proposed cardinality loss can also trivially be applied to the tasks of object counting and pedestrian detection. Our approach outperforms existing methods in all three cases on standard datasets.
Multiple Object Tracking: A Literature Review
May 22, 2017
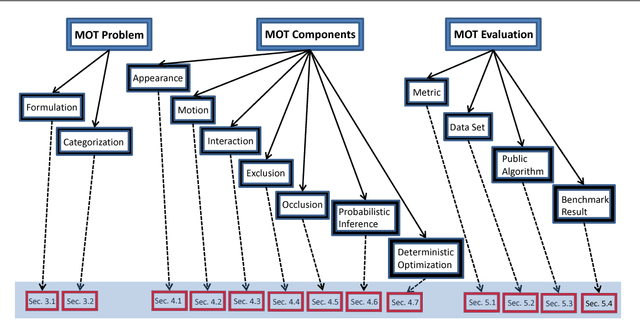
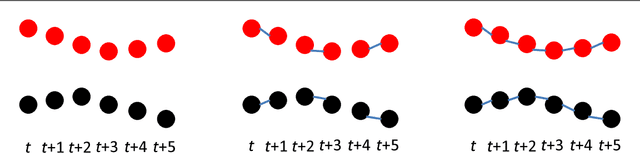
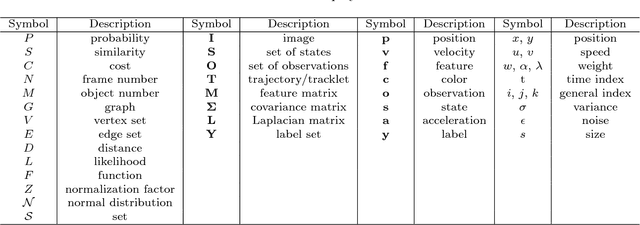
Multiple Object Tracking (MOT) is an important computer vision problem which has gained increasing attention due to its academic and commercial potential. Although different kinds of approaches have been proposed to tackle this problem, it still remains challenging due to factors like abrupt appearance changes and severe object occlusions. In this work, we contribute the first comprehensive and most recent review on this problem. We inspect the recent advances in various aspects and propose some interesting directions for future research. To the best of our knowledge, there has not been any extensive review on this topic in the community. We endeavor to provide a thorough review on the development of this problem in recent decades. The main contributions of this review are fourfold: 1) Key aspects in a multiple object tracking system, including formulation, categorization, key principles, evaluation of an MOT are discussed. 2) Instead of enumerating individual works, we discuss existing approaches according to various aspects, in each of which methods are divided into different groups and each group is discussed in detail for the principles, advances and drawbacks. 3) We examine experiments of existing publications and summarize results on popular datasets to provide quantitative comparisons. We also point to some interesting discoveries by analyzing these results. 4) We provide a discussion about issues of MOT research, as well as some interesting directions which could possibly become potential research effort in the future.