 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLevel-Set Parameters: Novel Representation for 3D Shape Analysis
Dec 18, 2024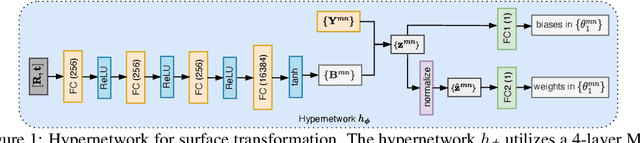

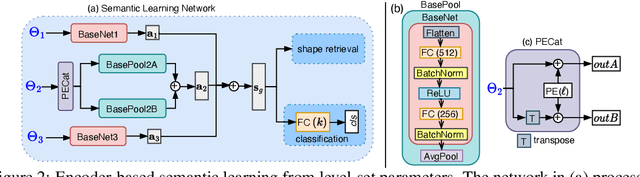
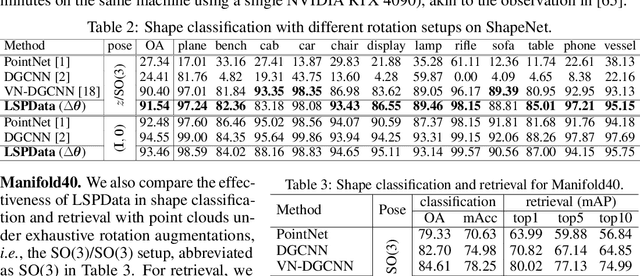
3D shape analysis has been largely focused on traditional 3D representations of point clouds and meshes, but the discrete nature of these data makes the analysis susceptible to variations in input resolutions. Recent development of neural fields brings in level-set parameters from signed distance functions as a novel, continuous, and numerical representation of 3D shapes, where the shape surfaces are defined as zero-level-sets of those functions. This motivates us to extend shape analysis from the traditional 3D data to these novel parameter data. Since the level-set parameters are not Euclidean like point clouds, we establish correlations across different shapes by formulating them as a pseudo-normal distribution, and learn the distribution prior from the respective dataset. To further explore the level-set parameters with shape transformations, we propose to condition a subset of these parameters on rotations and translations, and generate them with a hypernetwork. This simplifies the pose-related shape analysis compared to using traditional data. We demonstrate the promise of the novel representations through applications in shape classification (arbitrary poses), retrieval, and 6D object pose estimation. Code and data in this research are provided at https://github.com/EnyaHermite/LevelSetParamData.
EBMs vs. CL: Exploring Self-Supervised Visual Pretraining for Visual Question Answering
Jun 29, 2022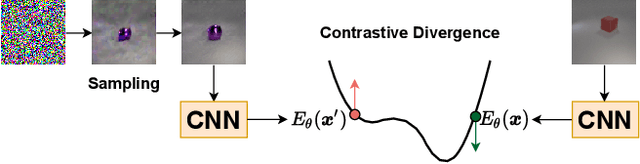
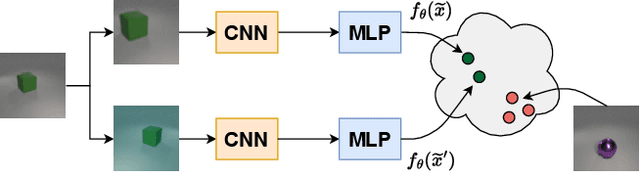
The availability of clean and diverse labeled data is a major roadblock for training models on complex tasks such as visual question answering (VQA). The extensive work on large vision-and-language models has shown that self-supervised learning is effective for pretraining multimodal interactions. In this technical report, we focus on visual representations. We review and evaluate self-supervised methods to leverage unlabeled images and pretrain a model, which we then fine-tune on a custom VQA task that allows controlled evaluation and diagnosis. We compare energy-based models (EBMs) with contrastive learning (CL). While EBMs are growing in popularity, they lack an evaluation on downstream tasks. We find that both EBMs and CL can learn representations from unlabeled images that enable training a VQA model on very little annotated data. In a simple setting similar to CLEVR, we find that CL representations also improve systematic generalization, and even match the performance of representations from a larger, supervised, ImageNet-pretrained model. However, we find EBMs to be difficult to train because of instabilities and high variability in their results. Although EBMs prove useful for OOD detection, other results on supervised energy-based training and uncertainty calibration are largely negative. Overall, CL currently seems a preferable option over EBMs.
Reasoning over Vision and Language: Exploring the Benefits of Supplemental Knowledge
Jan 15, 2021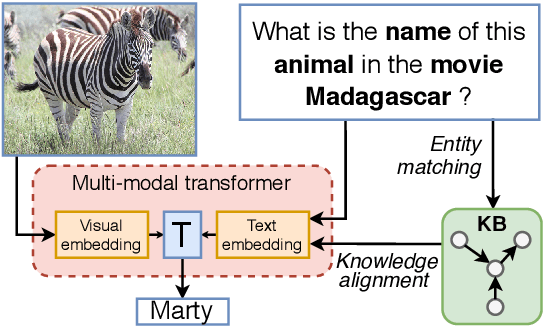
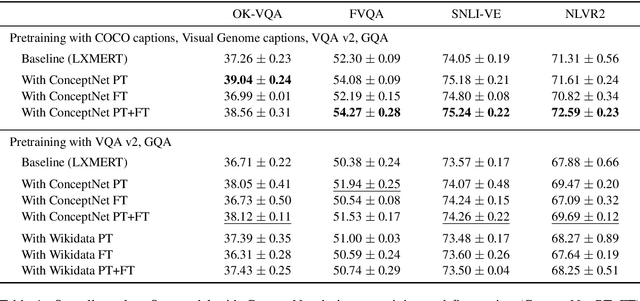
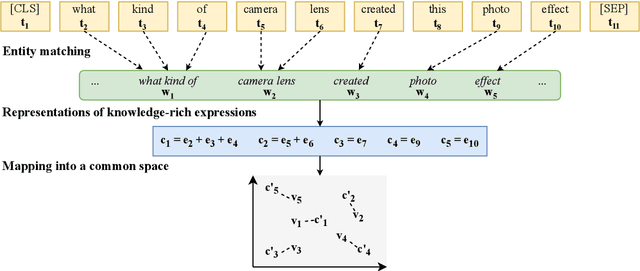
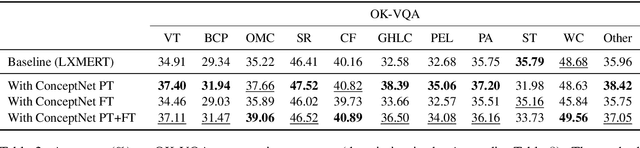
The limits of applicability of vision-and-language models are defined by the coverage of their training data. Tasks like vision question answering (VQA) often require commonsense and factual information beyond what can be learned from task-specific datasets. This paper investigates the injection of knowledge from general-purpose knowledge bases (KBs) into vision-and-language transformers. We use an auxiliary training objective that encourages the learned representations to align with graph embeddings of matching entities in a KB. We empirically study the relevance of various KBs to multiple tasks and benchmarks. The technique brings clear benefits to knowledge-demanding question answering tasks (OK-VQA, FVQA) by capturing semantic and relational knowledge absent from existing models. More surprisingly, the technique also benefits visual reasoning tasks (NLVR2, SNLI-VE). We perform probing experiments and show that the injection of additional knowledge regularizes the space of embeddings, which improves the representation of lexical and semantic similarities. The technique is model-agnostic and can expand the applicability of any vision-and-language transformer with minimal computational overhead.
Visual Question Answering with Prior Class Semantics
May 04, 2020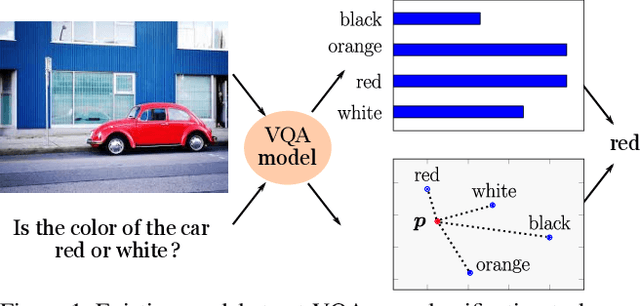
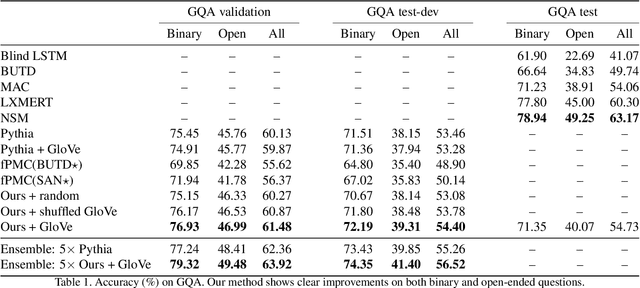
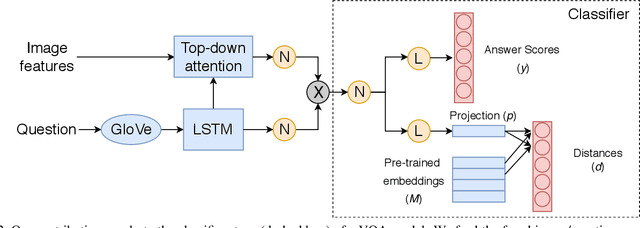
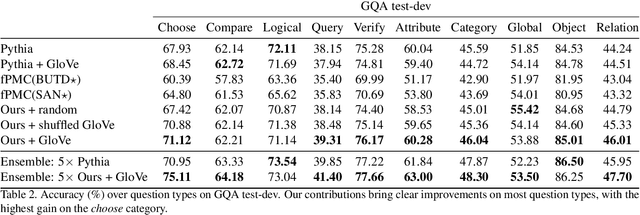
We present a novel mechanism to embed prior knowledge in a model for visual question answering. The open-set nature of the task is at odds with the ubiquitous approach of training of a fixed classifier. We show how to exploit additional information pertaining to the semantics of candidate answers. We extend the answer prediction process with a regression objective in a semantic space, in which we project candidate answers using prior knowledge derived from word embeddings. We perform an extensive study of learned representations with the GQA dataset, revealing that important semantic information is captured in the relations between embeddings in the answer space. Our method brings improvements in consistency and accuracy over a range of question types. Experiments with novel answers, unseen during training, indicate the method's potential for open-set prediction.
Visual Question Answering with Memory-Augmented Networks
Mar 25, 2018
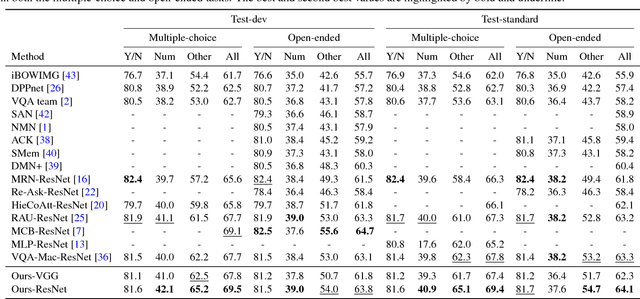
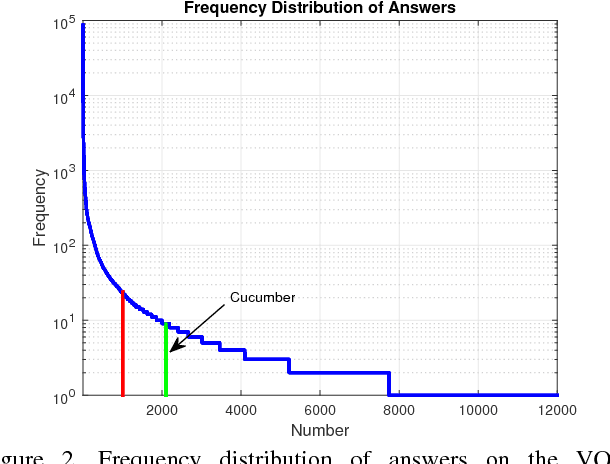
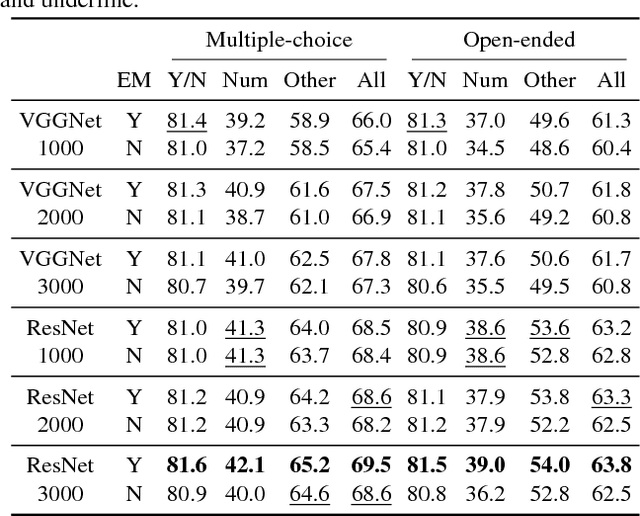
In this paper, we exploit a memory-augmented neural network to predict accurate answers to visual questions, even when those answers occur rarely in the training set. The memory network incorporates both internal and external memory blocks and selectively pays attention to each training exemplar. We show that memory-augmented neural networks are able to maintain a relatively long-term memory of scarce training exemplars, which is important for visual question answering due to the heavy-tailed distribution of answers in a general VQA setting. Experimental results on two large-scale benchmark datasets show the favorable performance of the proposed algorithm with a comparison to state of the art.
Joint Learning of Set Cardinality and State Distribution
Nov 21, 2017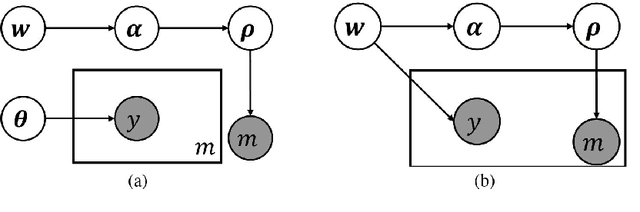
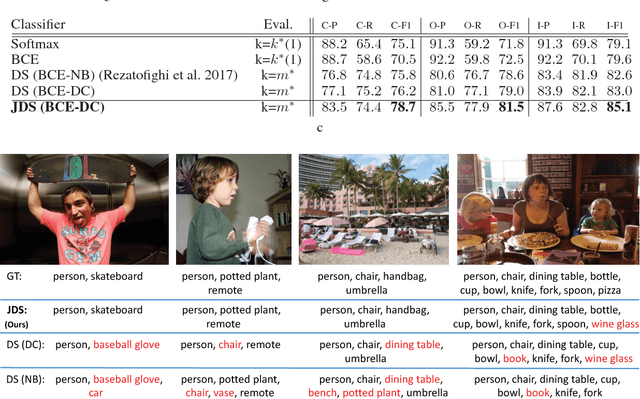
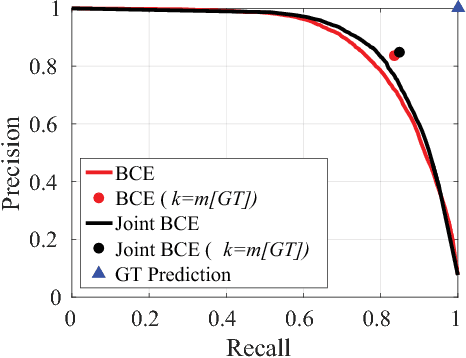
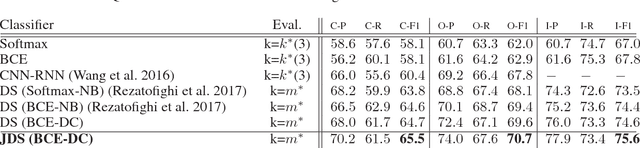
We present a novel approach for learning to predict sets using deep learning. In recent years, deep neural networks have shown remarkable results in computer vision, natural language processing and other related problems. Despite their success, traditional architectures suffer from a serious limitation in that they are built to deal with structured input and output data, i.e. vectors or matrices. Many real-world problems, however, are naturally described as sets, rather than vectors. Existing techniques that allow for sequential data, such as recurrent neural networks, typically heavily depend on the input and output order and do not guarantee a valid solution. Here, we derive in a principled way, a mathematical formulation for set prediction where the output is permutation invariant. In particular, our approach jointly learns both the cardinality and the state distribution of the target set. We demonstrate the validity of our method on the task of multi-label image classification and achieve a new state of the art on the PASCAL VOC and MS COCO datasets.
DeepSetNet: Predicting Sets with Deep Neural Networks
Aug 11, 2017
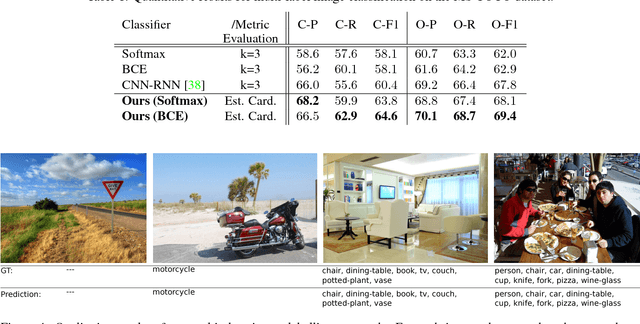
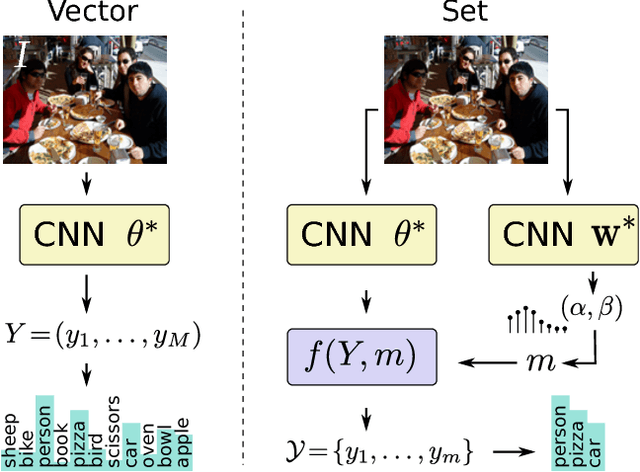

This paper addresses the task of set prediction using deep learning. This is important because the output of many computer vision tasks, including image tagging and object detection, are naturally expressed as sets of entities rather than vectors. As opposed to a vector, the size of a set is not fixed in advance, and it is invariant to the ordering of entities within it. We define a likelihood for a set distribution and learn its parameters using a deep neural network. We also derive a loss for predicting a discrete distribution corresponding to set cardinality. Set prediction is demonstrated on the problem of multi-class image classification. Moreover, we show that the proposed cardinality loss can also trivially be applied to the tasks of object counting and pedestrian detection. Our approach outperforms existing methods in all three cases on standard datasets.
FVQA: Fact-based Visual Question Answering
Aug 08, 2017
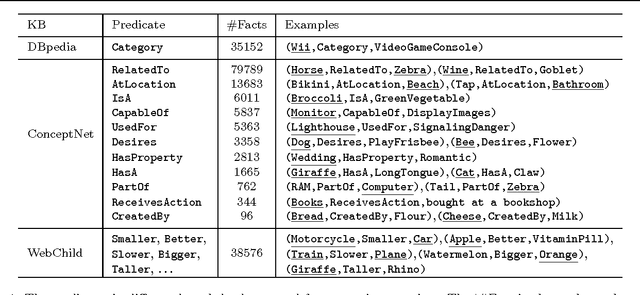
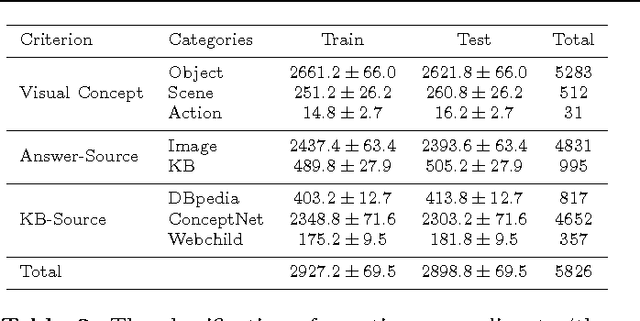
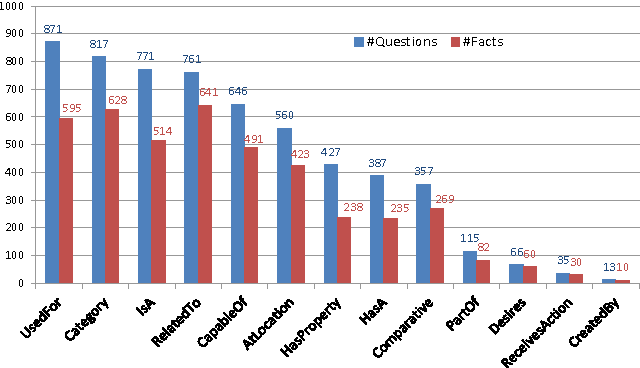
Visual Question Answering (VQA) has attracted a lot of attention in both Computer Vision and Natural Language Processing communities, not least because it offers insight into the relationships between two important sources of information. Current datasets, and the models built upon them, have focused on questions which are answerable by direct analysis of the question and image alone. The set of such questions that require no external information to answer is interesting, but very limited. It excludes questions which require common sense, or basic factual knowledge to answer, for example. Here we introduce FVQA, a VQA dataset which requires, and supports, much deeper reasoning. FVQA only contains questions which require external information to answer. We thus extend a conventional visual question answering dataset, which contains image-question-answerg triplets, through additional image-question-answer-supporting fact tuples. The supporting fact is represented as a structural triplet, such as <Cat,CapableOf,ClimbingTrees>. We evaluate several baseline models on the FVQA dataset, and describe a novel model which is capable of reasoning about an image on the basis of supporting facts.
Bayesian Conditional Generative Adverserial Networks
Jun 17, 2017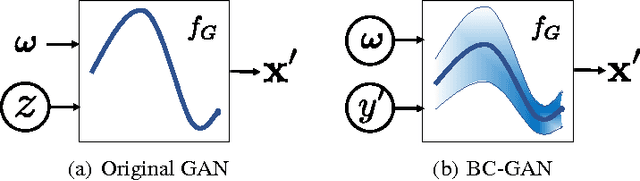
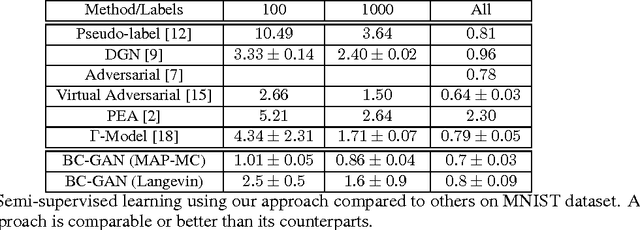
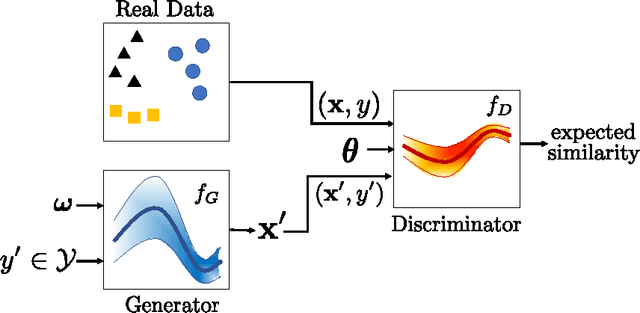
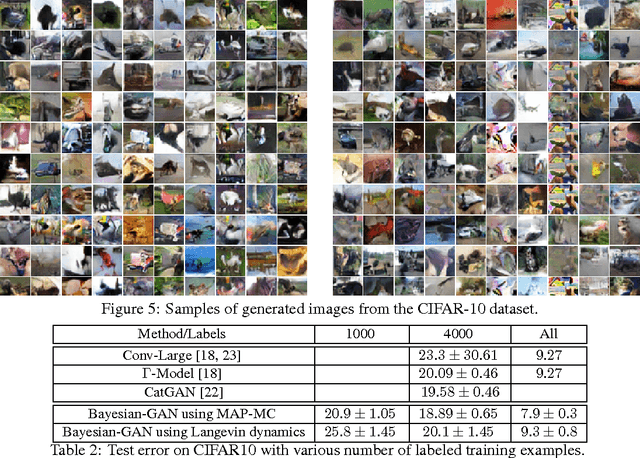
Traditional GANs use a deterministic generator function (typically a neural network) to transform a random noise input $z$ to a sample $\mathbf{x}$ that the discriminator seeks to distinguish. We propose a new GAN called Bayesian Conditional Generative Adversarial Networks (BC-GANs) that use a random generator function to transform a deterministic input $y'$ to a sample $\mathbf{x}$. Our BC-GANs extend traditional GANs to a Bayesian framework, and naturally handle unsupervised learning, supervised learning, and semi-supervised learning problems. Experiments show that the proposed BC-GANs outperforms the state-of-the-arts.
Image Captioning and Visual Question Answering Based on Attributes and External Knowledge
Dec 16, 2016
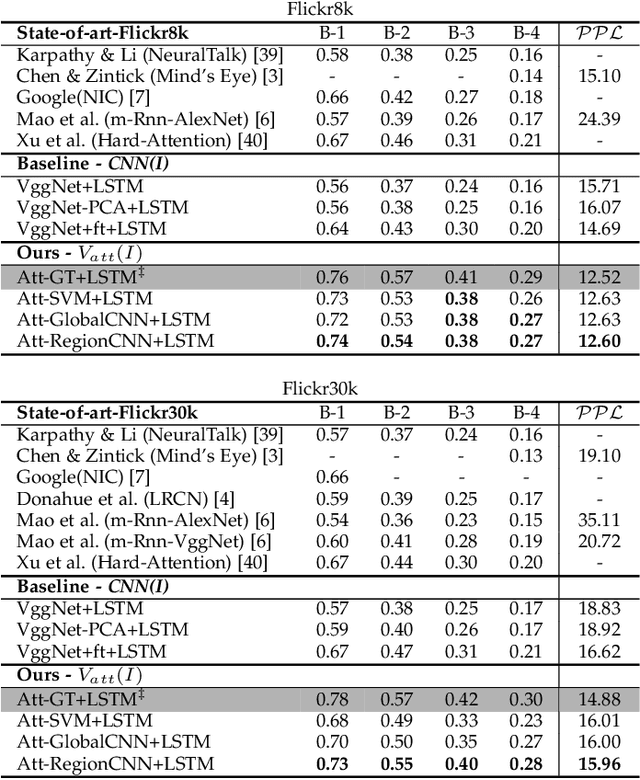
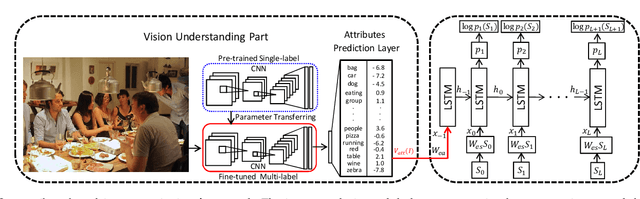
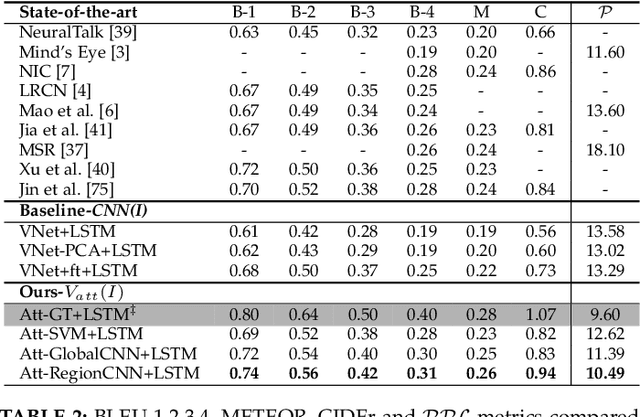
Much recent progress in Vision-to-Language problems has been achieved through a combination of Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). This approach does not explicitly represent high-level semantic concepts, but rather seeks to progress directly from image features to text. In this paper we first propose a method of incorporating high-level concepts into the successful CNN-RNN approach, and show that it achieves a significant improvement on the state-of-the-art in both image captioning and visual question answering. We further show that the same mechanism can be used to incorporate external knowledge, which is critically important for answering high level visual questions. Specifically, we design a visual question answering model that combines an internal representation of the content of an image with information extracted from a general knowledge base to answer a broad range of image-based questions. It particularly allows questions to be asked about the contents of an image, even when the image itself does not contain a complete answer. Our final model achieves the best reported results on both image captioning and visual question answering on several benchmark datasets.