 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEBMs vs. CL: Exploring Self-Supervised Visual Pretraining for Visual Question Answering
Paper and Code
Jun 29, 2022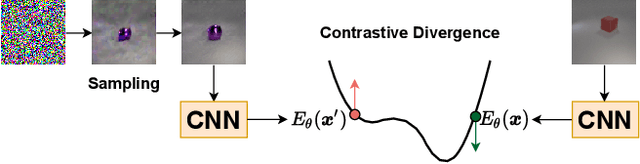
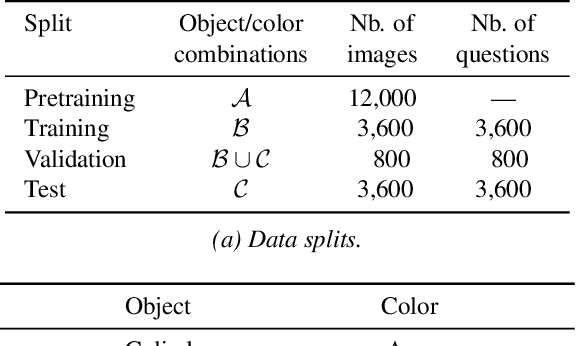
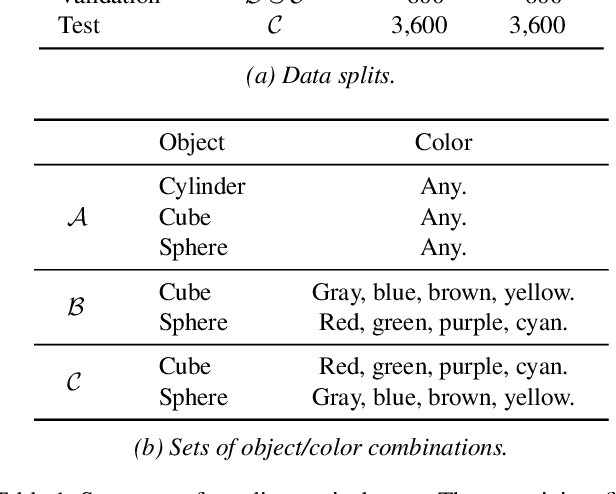
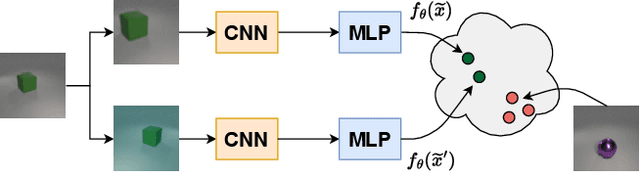
The availability of clean and diverse labeled data is a major roadblock for training models on complex tasks such as visual question answering (VQA). The extensive work on large vision-and-language models has shown that self-supervised learning is effective for pretraining multimodal interactions. In this technical report, we focus on visual representations. We review and evaluate self-supervised methods to leverage unlabeled images and pretrain a model, which we then fine-tune on a custom VQA task that allows controlled evaluation and diagnosis. We compare energy-based models (EBMs) with contrastive learning (CL). While EBMs are growing in popularity, they lack an evaluation on downstream tasks. We find that both EBMs and CL can learn representations from unlabeled images that enable training a VQA model on very little annotated data. In a simple setting similar to CLEVR, we find that CL representations also improve systematic generalization, and even match the performance of representations from a larger, supervised, ImageNet-pretrained model. However, we find EBMs to be difficult to train because of instabilities and high variability in their results. Although EBMs prove useful for OOD detection, other results on supervised energy-based training and uncertainty calibration are largely negative. Overall, CL currently seems a preferable option over EBMs.