 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuMuon: Nuclear-Norm-Constrained Muon for Compressible LLM Training
Mar 04, 2026The rapid progress of large language models (LLMs) is increasingly constrained by memory and deployment costs, motivating compression methods for practical deployment. Many state-of-the-art compression pipelines leverage the low-rank structure of trained weight matrices, a phenomenon often associated with the properties of popular optimizers such as Adam. In this context, Muon is a recently proposed optimizer that improves LLM pretraining via full-rank update steps, but its induced weight-space structure has not been characterized yet. In this work, we report a surprising empirical finding: despite imposing full-rank updates, Muon-trained models exhibit pronounced low-rank structure in their weight matrices and are readily compressible under standard pipelines. Motivated by this insight, we propose NuMuon, which augments Muon with a nuclear-norm constraint on the update direction, further constraining the learned weights toward low-rank structure. Across billion-parameter-scale models, we show that NuMuon increases weight compressibility and improves post-compression model quality under state-of-the-art LLM compression pipelines while retaining Muon's favorable convergence behavior.
SENTINEL: Stagewise Integrity Verification for Pipeline Parallel Decentralized Training
Mar 03, 2026Decentralized training introduces critical security risks when executed across untrusted, geographically distributed nodes. While existing Byzantine-tolerant literature addresses data parallel (DP) training through robust aggregation methods, pipeline parallelism (PP) presents fundamentally distinct challenges. In PP, model layers are distributed across workers where the activations and their gradients flow between stages rather than being aggregated, making traditional DP approaches inapplicable. We propose SENTINEL, a verification mechanism for PP training without computation duplication. SENTINEL employs lightweight momentum-based monitoring using exponential moving averages (EMAs) to detect corrupted inter-stage communication. Unlike existing Byzantine-tolerant approaches for DP that aggregate parameter gradients across replicas, our approach verifies sequential activation/gradient transmission between layers. We provide theoretical convergence guarantees for this new setting that recovers classical convergence rates when relaxed to standard training. Experiments demonstrate successful training of up to 4B-parameter LLMs across untrusted distributed environments with up to 176 workers while maintaining model convergence and performance.
AsyncMesh: Fully Asynchronous Optimization for Data and Pipeline Parallelism
Jan 30, 2026Data and pipeline parallelism are key strategies for scaling neural network training across distributed devices, but their high communication cost necessitates co-located computing clusters with fast interconnects, limiting their scalability. We address this communication bottleneck by introducing asynchronous updates across both parallelism axes, relaxing the co-location requirement at the expense of introducing staleness between pipeline stages and data parallel replicas. To mitigate staleness, for pipeline parallelism, we adopt a weight look-ahead approach, and for data parallelism, we introduce an asynchronous sparse averaging method equipped with an exponential moving average based correction mechanism. We provide convergence guarantees for both sparse averaging and asynchronous updates. Experiments on large-scale language models (up to \em 1B parameters) demonstrate that our approach matches the performance of the fully synchronous baseline, while significantly reducing communication overhead.
SRSR: Enhancing Semantic Accuracy in Real-World Image Super-Resolution with Spatially Re-Focused Text-Conditioning
Oct 26, 2025Existing diffusion-based super-resolution approaches often exhibit semantic ambiguities due to inaccuracies and incompleteness in their text conditioning, coupled with the inherent tendency for cross-attention to divert towards irrelevant pixels. These limitations can lead to semantic misalignment and hallucinated details in the generated high-resolution outputs. To address these, we propose a novel, plug-and-play spatially re-focused super-resolution (SRSR) framework that consists of two core components: first, we introduce Spatially Re-focused Cross-Attention (SRCA), which refines text conditioning at inference time by applying visually-grounded segmentation masks to guide cross-attention. Second, we introduce a Spatially Targeted Classifier-Free Guidance (STCFG) mechanism that selectively bypasses text influences on ungrounded pixels to prevent hallucinations. Extensive experiments on both synthetic and real-world datasets demonstrate that SRSR consistently outperforms seven state-of-the-art baselines in standard fidelity metrics (PSNR and SSIM) across all datasets, and in perceptual quality measures (LPIPS and DISTS) on two real-world benchmarks, underscoring its effectiveness in achieving both high semantic fidelity and perceptual quality in super-resolution.
Scalable and Realistic Virtual Try-on Application for Foundation Makeup with Kubelka-Munk Theory
Jul 09, 2025Augmented reality is revolutionizing beauty industry with virtual try-on (VTO) applications, which empowers users to try a wide variety of products using their phones without the hassle of physically putting on real products. A critical technical challenge in foundation VTO applications is the accurate synthesis of foundation-skin tone color blending while maintaining the scalability of the method across diverse product ranges. In this work, we propose a novel method to approximate well-established Kubelka-Munk (KM) theory for faster image synthesis while preserving foundation-skin tone color blending realism. Additionally, we build a scalable end-to-end framework for realistic foundation makeup VTO solely depending on the product information available on e-commerce sites. We validate our method using real-world makeup images, demonstrating that our framework outperforms other techniques.
A Sampling Theory Perspective on Activations for Implicit Neural Representations
Feb 08, 2024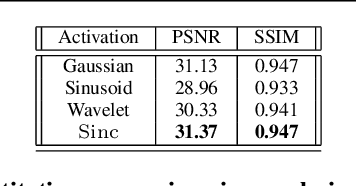
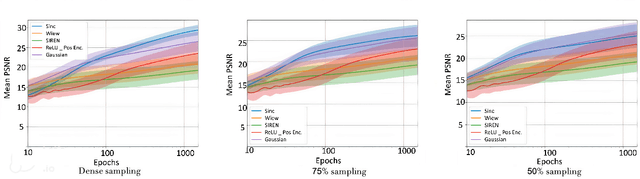

Implicit Neural Representations (INRs) have gained popularity for encoding signals as compact, differentiable entities. While commonly using techniques like Fourier positional encodings or non-traditional activation functions (e.g., Gaussian, sinusoid, or wavelets) to capture high-frequency content, their properties lack exploration within a unified theoretical framework. Addressing this gap, we conduct a comprehensive analysis of these activations from a sampling theory perspective. Our investigation reveals that sinc activations, previously unused in conjunction with INRs, are theoretically optimal for signal encoding. Additionally, we establish a connection between dynamical systems and INRs, leveraging sampling theory to bridge these two paradigms.
BLiRF-RF: Bandlimited Radiance Fields for Dynamic Scene Modeling
Mar 18, 2023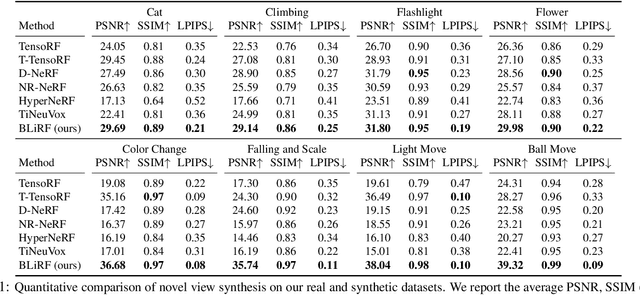
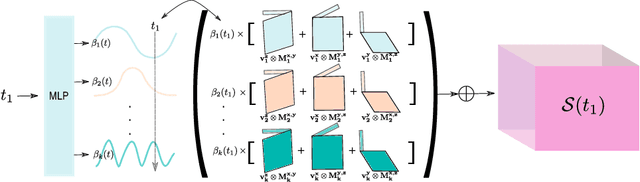

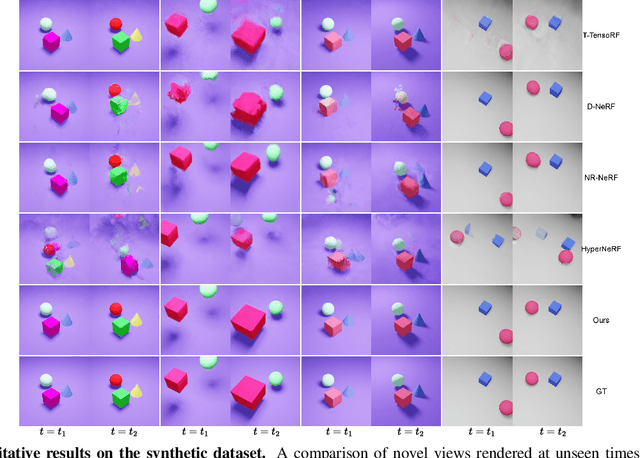
Reasoning the 3D structure of a non-rigid dynamic scene from a single moving camera is an under-constrained problem. Inspired by the remarkable progress of neural radiance fields (NeRFs) in photo-realistic novel view synthesis of static scenes, extensions have been proposed for dynamic settings. These methods heavily rely on neural priors in order to regularize the problem. In this work, we take a step back and reinvestigate how current implementations may entail deleterious effects, including limited expressiveness, entanglement of light and density fields, and sub-optimal motion localization. As a remedy, we advocate for a bridge between classic non-rigid-structure-from-motion (\nrsfm) and NeRF, enabling the well-studied priors of the former to constrain the latter. To this end, we propose a framework that factorizes time and space by formulating a scene as a composition of bandlimited, high-dimensional signals. We demonstrate compelling results across complex dynamic scenes that involve changes in lighting, texture and long-range dynamics.
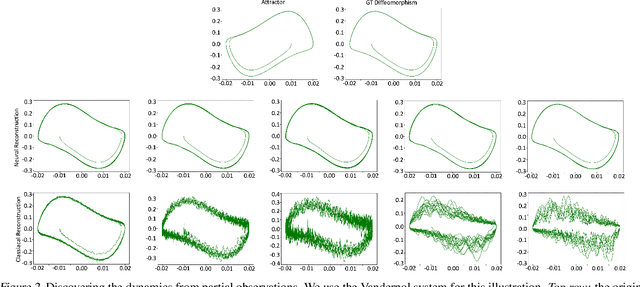
On the effectiveness of neural priors in modeling dynamical systems
Mar 10, 2023Modelling dynamical systems is an integral component for understanding the natural world. To this end, neural networks are becoming an increasingly popular candidate owing to their ability to learn complex functions from large amounts of data. Despite this recent progress, there has not been an adequate discussion on the architectural regularization that neural networks offer when learning such systems, hindering their efficient usage. In this paper, we initiate a discussion in this direction using coordinate networks as a test bed. We interpret dynamical systems and coordinate networks from a signal processing lens, and show that simple coordinate networks with few layers can be used to solve multiple problems in modelling dynamical systems, without any explicit regularizers.
EBMs vs. CL: Exploring Self-Supervised Visual Pretraining for Visual Question Answering
Jun 29, 2022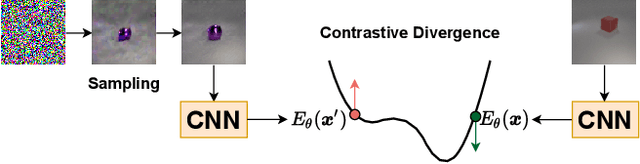
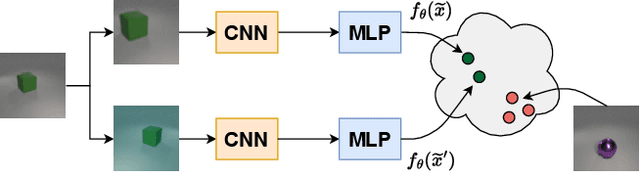
The availability of clean and diverse labeled data is a major roadblock for training models on complex tasks such as visual question answering (VQA). The extensive work on large vision-and-language models has shown that self-supervised learning is effective for pretraining multimodal interactions. In this technical report, we focus on visual representations. We review and evaluate self-supervised methods to leverage unlabeled images and pretrain a model, which we then fine-tune on a custom VQA task that allows controlled evaluation and diagnosis. We compare energy-based models (EBMs) with contrastive learning (CL). While EBMs are growing in popularity, they lack an evaluation on downstream tasks. We find that both EBMs and CL can learn representations from unlabeled images that enable training a VQA model on very little annotated data. In a simple setting similar to CLEVR, we find that CL representations also improve systematic generalization, and even match the performance of representations from a larger, supervised, ImageNet-pretrained model. However, we find EBMs to be difficult to train because of instabilities and high variability in their results. Although EBMs prove useful for OOD detection, other results on supervised energy-based training and uncertainty calibration are largely negative. Overall, CL currently seems a preferable option over EBMs.
Reasoning over Vision and Language: Exploring the Benefits of Supplemental Knowledge
Jan 15, 2021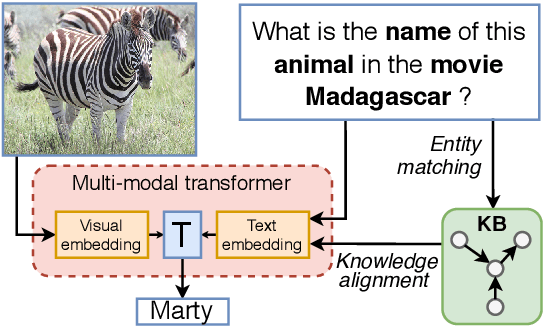
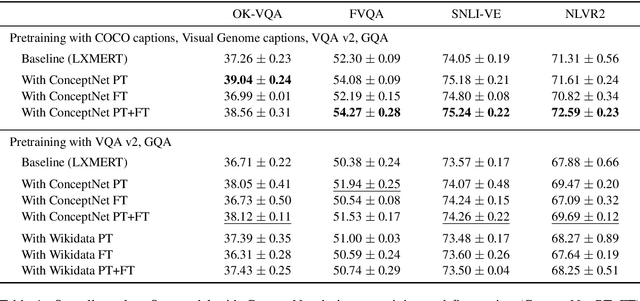
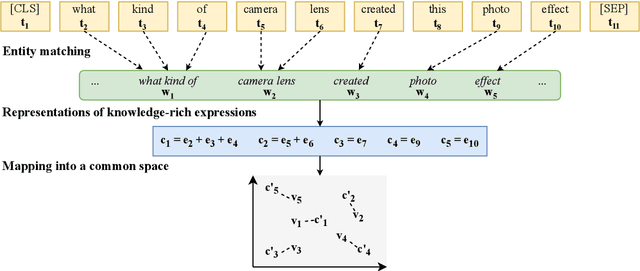
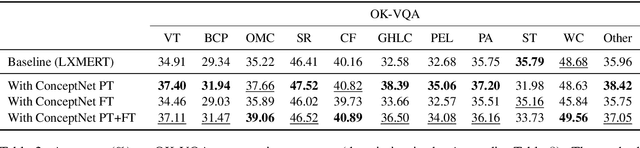
The limits of applicability of vision-and-language models are defined by the coverage of their training data. Tasks like vision question answering (VQA) often require commonsense and factual information beyond what can be learned from task-specific datasets. This paper investigates the injection of knowledge from general-purpose knowledge bases (KBs) into vision-and-language transformers. We use an auxiliary training objective that encourages the learned representations to align with graph embeddings of matching entities in a KB. We empirically study the relevance of various KBs to multiple tasks and benchmarks. The technique brings clear benefits to knowledge-demanding question answering tasks (OK-VQA, FVQA) by capturing semantic and relational knowledge absent from existing models. More surprisingly, the technique also benefits visual reasoning tasks (NLVR2, SNLI-VE). We perform probing experiments and show that the injection of additional knowledge regularizes the space of embeddings, which improves the representation of lexical and semantic similarities. The technique is model-agnostic and can expand the applicability of any vision-and-language transformer with minimal computational overhead.