 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason and Navigate: Parameter Efficient Action Planning with Large Language Models
May 12, 2025The remote embodied referring expression (REVERIE) task requires an agent to navigate through complex indoor environments and localize a remote object specified by high-level instructions, such as "bring me a spoon", without pre-exploration. Hence, an efficient navigation plan is essential for the final success. This paper proposes a novel parameter-efficient action planner using large language models (PEAP-LLM) to generate a single-step instruction at each location. The proposed model consists of two modules, LLM goal planner (LGP) and LoRA action planner (LAP). Initially, LGP extracts the goal-oriented plan from REVERIE instructions, including the target object and room. Then, LAP generates a single-step instruction with the goal-oriented plan, high-level instruction, and current visual observation as input. PEAP-LLM enables the embodied agent to interact with LAP as the path planner on the fly. A simple direct application of LLMs hardly achieves good performance. Also, existing hard-prompt-based methods are error-prone in complicated scenarios and need human intervention. To address these issues and prevent the LLM from generating hallucinations and biased information, we propose a novel two-stage method for fine-tuning the LLM, consisting of supervised fine-tuning (STF) and direct preference optimization (DPO). SFT improves the quality of generated instructions, while DPO utilizes environmental feedback. Experimental results show the superiority of our proposed model on REVERIE compared to the previous state-of-the-art.
BLiRF-RF: Bandlimited Radiance Fields for Dynamic Scene Modeling
Mar 18, 2023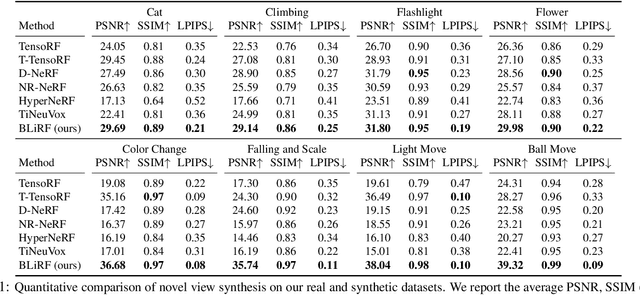
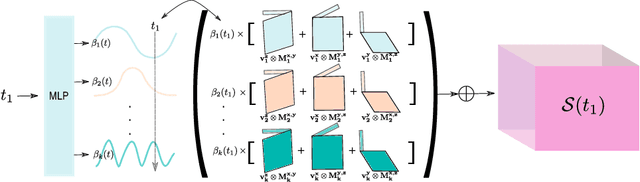

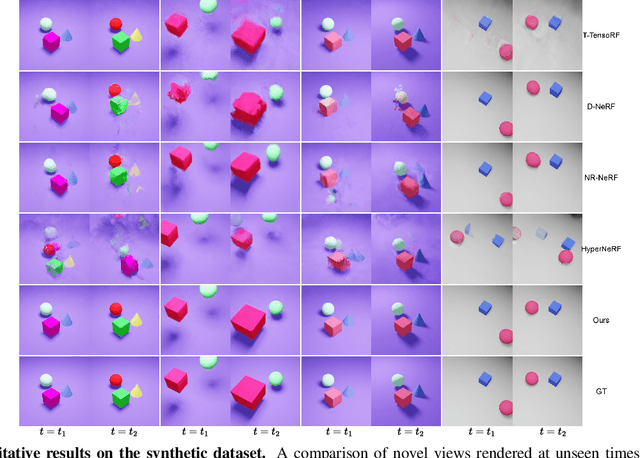
Reasoning the 3D structure of a non-rigid dynamic scene from a single moving camera is an under-constrained problem. Inspired by the remarkable progress of neural radiance fields (NeRFs) in photo-realistic novel view synthesis of static scenes, extensions have been proposed for dynamic settings. These methods heavily rely on neural priors in order to regularize the problem. In this work, we take a step back and reinvestigate how current implementations may entail deleterious effects, including limited expressiveness, entanglement of light and density fields, and sub-optimal motion localization. As a remedy, we advocate for a bridge between classic non-rigid-structure-from-motion (\nrsfm) and NeRF, enabling the well-studied priors of the former to constrain the latter. To this end, we propose a framework that factorizes time and space by formulating a scene as a composition of bandlimited, high-dimensional signals. We demonstrate compelling results across complex dynamic scenes that involve changes in lighting, texture and long-range dynamics.
Learning for Visual Navigation by Imagining the Success
Feb 28, 2021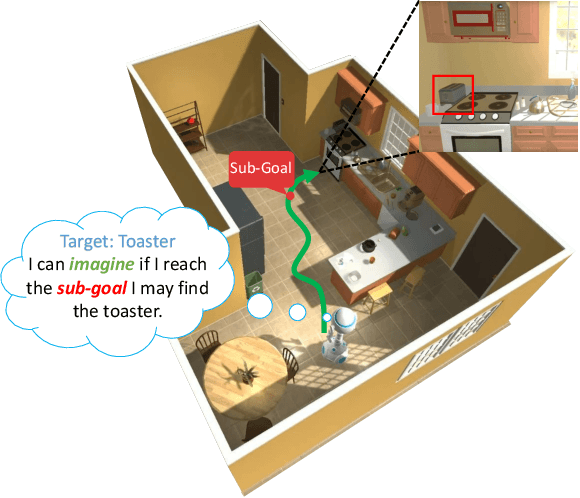
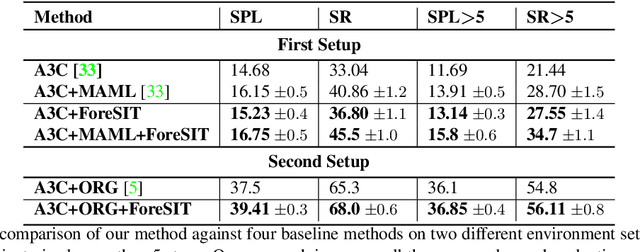
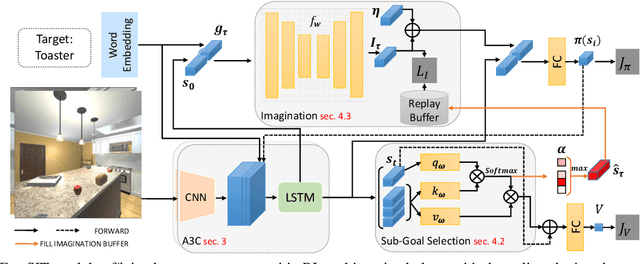
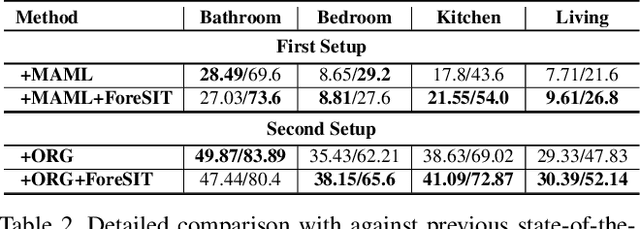
Visual navigation is often cast as a reinforcement learning (RL) problem. Current methods typically result in a suboptimal policy that learns general obstacle avoidance and search behaviours. For example, in the target-object navigation setting, the policies learnt by traditional methods often fail to complete the task, even when the target is clearly within reach from a human perspective. In order to address this issue, we propose to learn to imagine a latent representation of the successful (sub-)goal state. To do so, we have developed a module which we call Foresight Imagination (ForeSIT). ForeSIT is trained to imagine the recurrent latent representation of a future state that leads to success, e.g. either a sub-goal state that is important to reach before the target, or the goal state itself. By conditioning the policy on the generated imagination during training, our agent learns how to use this imagination to achieve its goal robustly. Our agent is able to imagine what the (sub-)goal state may look like (in the latent space) and can learn to navigate towards that state. We develop an efficient learning algorithm to train ForeSIT in an on-policy manner and integrate it into our RL objective. The integration is not trivial due to the constantly evolving state representation shared between both the imagination and the policy. We, empirically, observe that our method outperforms the state-of-the-art methods by a large margin in the commonly accepted benchmark AI2THOR environment. Our method can be readily integrated or added to other model-free RL navigation frameworks.
Towards Effective Deep Embedding for Zero-Shot Learning
Aug 30, 2018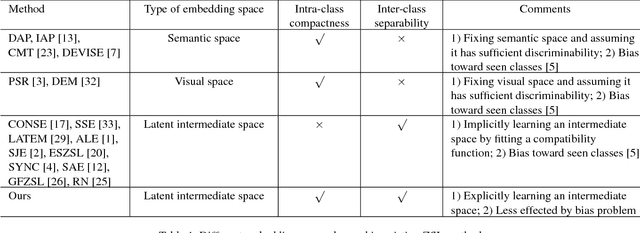
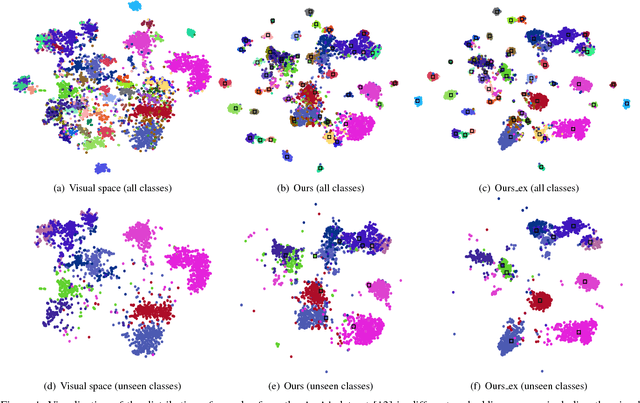

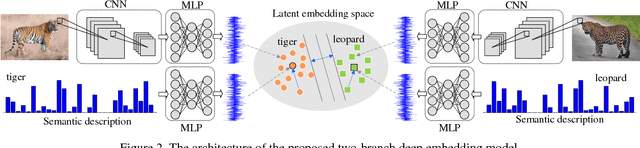
Zero-shot learning (ZSL) attempts to recognize visual samples of unseen classes by virtue of the semantic descriptions of those classes. We posit that the key to ZSL is to exploit an effective embedding space where 1) visual samples can be tightly centred around the semantic descriptions of classes that they belong to; 2) visual samples of different classes are separated from each other with a large enough margin. Towards this goal, we present a simple but surprisingly effective deep embedding model. In our model, we separately embed visual samples and semantic descriptions into a latent intermediate space such that visual samples not only coincide with associated semantic descriptions, but also can be correctly discriminated by a trainable linear classifier. By doing this, visual samples can be tightly centred around associated semantic descriptions and more importantly, they can be separated from other semantic descriptions with a large margin, thus leading to a new state-of-the-art for ZSL. Furthermore, due to lacking training samples, the generalization capacity of the learned embedding space to unseen classes can be further improved. To this end, we propose to upgrade our model with a refining strategy which progressively calibrates the embedding space based upon some test samples chosen from unseen classes with high-confidence pseudo labels, and ultimately improves the generalization capacity greatly. Experimental results on five benchmarks demonstrate the great advantage of our model over current state-of-the-art competitors. For example, on AwA1 dataset, our model improves the recognition accuracy on unseen classes by 16.9% in conventional ZSL setting and even by 38.6% in the generalized ZSL setting.
The Shallow End: Empowering Shallower Deep-Convolutional Networks through Auxiliary Outputs
Apr 23, 2017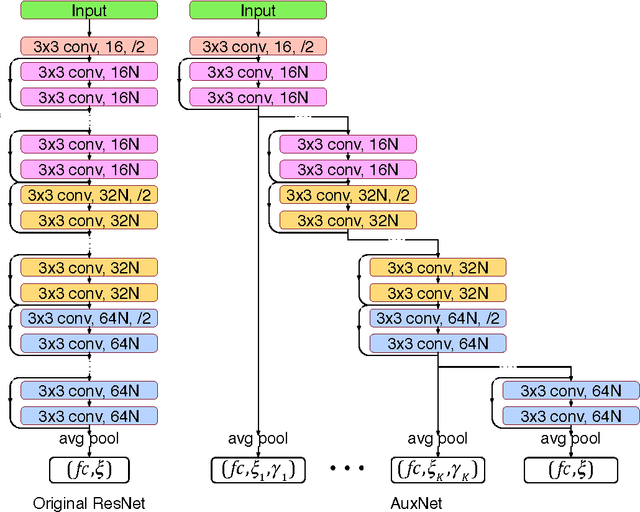
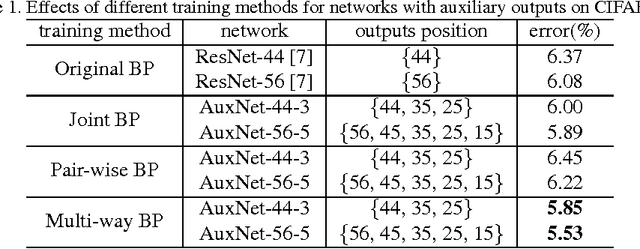
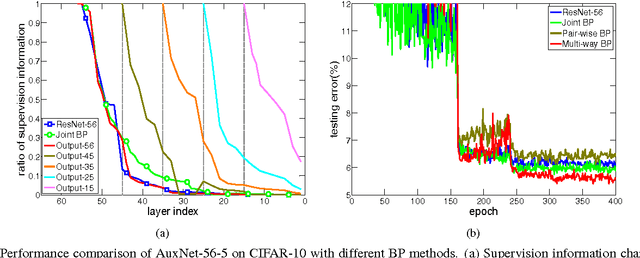
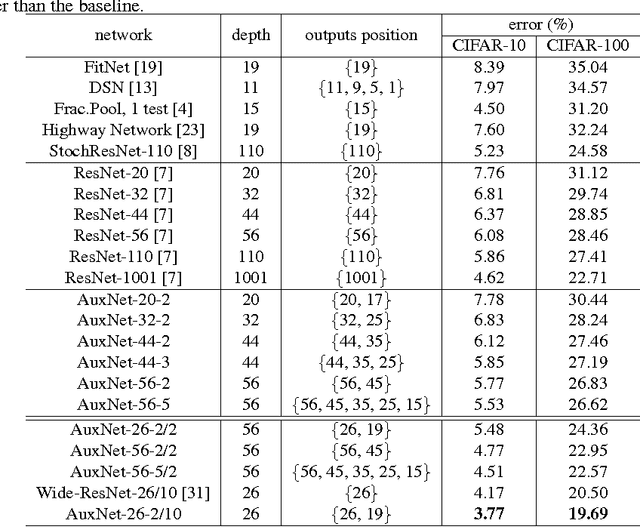
The depth is one of the key factors behind the great success of convolutional neural networks (CNNs), with the gradient vanishing issue having been largely addressed by various nets, e.g. ResNet. However, when the depth goes very deep, the supervision information from the loss function will vanish due to the long backpropagation path, especially for those shallow layers. This means that intermediate layers receive less supervision information and will lead to redundancy in models. As a result, the model becomes very redundant and the over-fitting issue may happen. To address this, we propose a model, called AuxNet, by introducing auxiliary outputs at intermediate layers. Different from existing approaches, we propose a Multi-path training method to propagate not only gradients but also sufficient supervision informationfrommultipleauxiliaryoutputs. TheproposedAuxNetwithmulti-pathtrainingmethodgivesrisetomorecompact networks which outperform their very deep equivalent (i.e. ResNet). For example, AuxNet with 44 layers performs better than the ResNet equivalent with 110 layers on several benchmark data sets, i.e. CIFAR-10, CIFAR-100 and SVHN.
Scalable Nuclear-norm Minimization by Subspace Pursuit Proximal Riemannian Gradient
Mar 18, 2015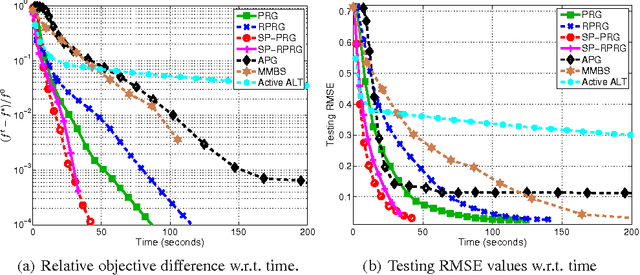
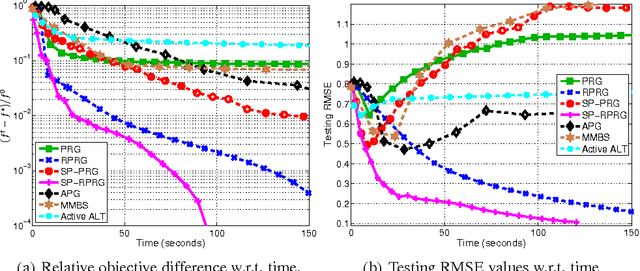
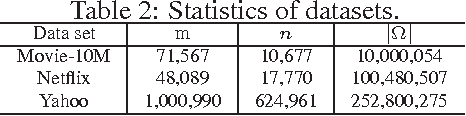
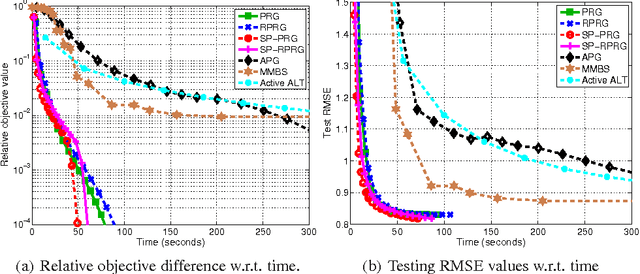
Nuclear-norm regularization plays a vital role in many learning tasks, such as low-rank matrix recovery (MR), and low-rank representation (LRR). Solving this problem directly can be computationally expensive due to the unknown rank of variables or large-rank singular value decompositions (SVDs). To address this, we propose a proximal Riemannian gradient (PRG) scheme which can efficiently solve trace-norm regularized problems defined on real-algebraic variety $\mMLr$ of real matrices of rank at most $r$. Based on PRG, we further present a simple and novel subspace pursuit (SP) paradigm for general trace-norm regularized problems without the explicit rank constraint $\mMLr$. The proposed paradigm is very scalable by avoiding large-rank SVDs. Empirical studies on several tasks, such as matrix completion and LRR based subspace clustering, demonstrate the superiority of the proposed paradigms over existing methods.