 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning for Visual Navigation by Imagining the Success
Feb 28, 2021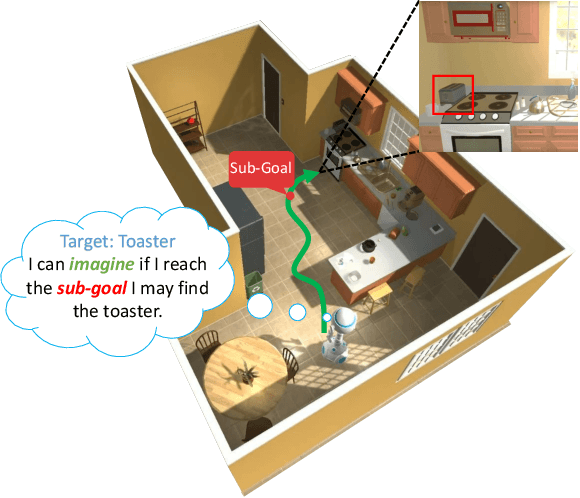
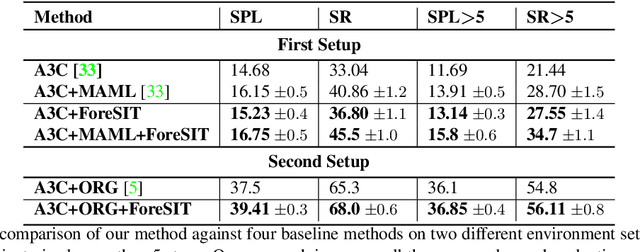
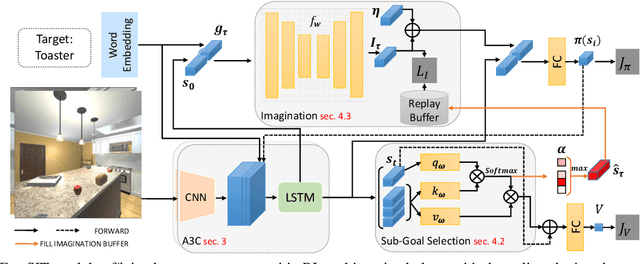
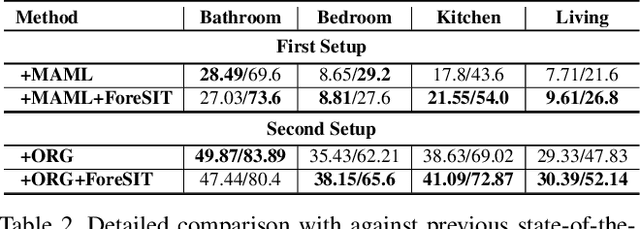
Visual navigation is often cast as a reinforcement learning (RL) problem. Current methods typically result in a suboptimal policy that learns general obstacle avoidance and search behaviours. For example, in the target-object navigation setting, the policies learnt by traditional methods often fail to complete the task, even when the target is clearly within reach from a human perspective. In order to address this issue, we propose to learn to imagine a latent representation of the successful (sub-)goal state. To do so, we have developed a module which we call Foresight Imagination (ForeSIT). ForeSIT is trained to imagine the recurrent latent representation of a future state that leads to success, e.g. either a sub-goal state that is important to reach before the target, or the goal state itself. By conditioning the policy on the generated imagination during training, our agent learns how to use this imagination to achieve its goal robustly. Our agent is able to imagine what the (sub-)goal state may look like (in the latent space) and can learn to navigate towards that state. We develop an efficient learning algorithm to train ForeSIT in an on-policy manner and integrate it into our RL objective. The integration is not trivial due to the constantly evolving state representation shared between both the imagination and the policy. We, empirically, observe that our method outperforms the state-of-the-art methods by a large margin in the commonly accepted benchmark AI2THOR environment. Our method can be readily integrated or added to other model-free RL navigation frameworks.