 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruth as a Trajectory: What Internal Representations Reveal About Large Language Model Reasoning
Mar 01, 2026Existing explainability methods for Large Language Models (LLMs) typically treat hidden states as static points in activation space, assuming that correct and incorrect inferences can be separated using representations from an individual layer. However, these activations are saturated with polysemantic features, leading to linear probes learning surface-level lexical patterns rather than underlying reasoning structures. We introduce Truth as a Trajectory (TaT), which models the transformer inference as an unfolded trajectory of iterative refinements, shifting analysis from static activations to layer-wise geometric displacement. By analyzing displacement of representations across layers, TaT uncovers geometric invariants that distinguish valid reasoning from spurious behavior. We evaluate TaT across dense and Mixture-of-Experts (MoE) architectures on benchmarks spanning commonsense reasoning, question answering, and toxicity detection. Without access to the activations themselves and using only changes in activations across layers, we show that TaT effectively mitigates reliance on static lexical confounds, outperforming conventional probing, and establishes trajectory analysis as a complementary perspective on LLM explainability.
Decomposing Task Vectors for Refined Model Editing
Dec 27, 2025Large pre-trained models have transformed machine learning, yet adapting these models effectively to exhibit precise, concept-specific behaviors remains a significant challenge. Task vectors, defined as the difference between fine-tuned and pre-trained model parameters, provide a mechanism for steering neural networks toward desired behaviors. This has given rise to large repositories dedicated to task vectors tailored for specific behaviors. The arithmetic operation of these task vectors allows for the seamless combination of desired behaviors without the need for large datasets. However, these vectors often contain overlapping concepts that can interfere with each other during arithmetic operations, leading to unpredictable outcomes. We propose a principled decomposition method that separates each task vector into two components: one capturing shared knowledge across multiple task vectors, and another isolating information unique to each specific task. By identifying invariant subspaces across projections, our approach enables more precise control over concept manipulation without unintended amplification or diminution of other behaviors. We demonstrate the effectiveness of our decomposition method across three domains: improving multi-task merging in image classification by 5% using shared components as additional task vectors, enabling clean style mixing in diffusion models without generation degradation by mixing only the unique components, and achieving 47% toxicity reduction in language models while preserving performance on general knowledge tasks by negating the toxic information isolated to the unique component. Our approach provides a new framework for understanding and controlling task vector arithmetic, addressing fundamental limitations in model editing operations.
The Quest for Winning Tickets in Low-Rank Adapters
Dec 27, 2025The Lottery Ticket Hypothesis (LTH) suggests that over-parameterized neural networks contain sparse subnetworks ("winning tickets") capable of matching full model performance when trained from scratch. With the growing reliance on fine-tuning large pretrained models, we investigate whether LTH extends to parameter-efficient fine-tuning (PEFT), specifically focusing on Low-Rank Adaptation (LoRA) methods. Our key finding is that LTH holds within LoRAs, revealing sparse subnetworks that can match the performance of dense adapters. In particular, we find that the effectiveness of sparse subnetworks depends more on how much sparsity is applied in each layer than on the exact weights included in the subnetwork. Building on this insight, we propose Partial-LoRA, a method that systematically identifies said subnetworks and trains sparse low-rank adapters aligned with task-relevant subspaces of the pre-trained model. Experiments across 8 vision and 12 language tasks in both single-task and multi-task settings show that Partial-LoRA reduces the number of trainable parameters by up to 87\%, while maintaining or improving accuracy. Our results not only deepen our theoretical understanding of transfer learning and the interplay between pretraining and fine-tuning but also open new avenues for developing more efficient adaptation strategies.
Categorical Keypoint Positional Embedding for Robust Animal Re-Identification
Dec 01, 2024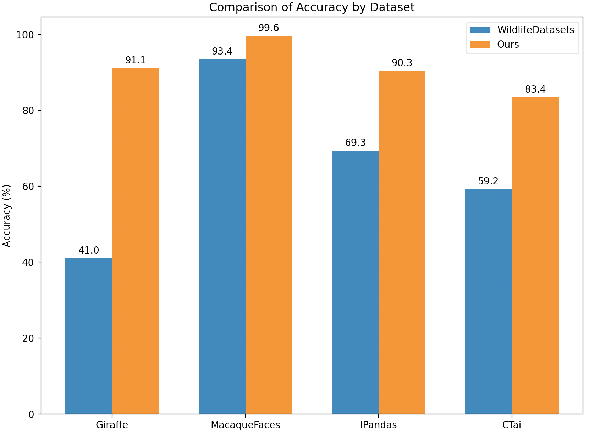
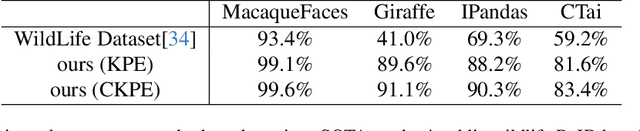

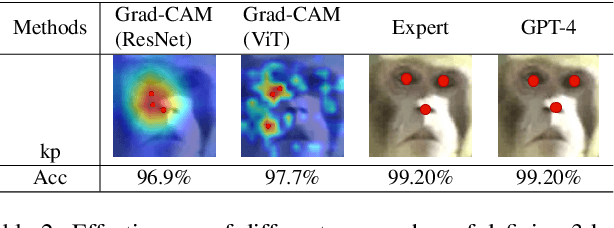
Animal re-identification (ReID) has become an indispensable tool in ecological research, playing a critical role in tracking population dynamics, analyzing behavioral patterns, and assessing ecological impacts, all of which are vital for informed conservation strategies. Unlike human ReID, animal ReID faces significant challenges due to the high variability in animal poses, diverse environmental conditions, and the inability to directly apply pre-trained models to animal data, making the identification process across species more complex. This work introduces an innovative keypoint propagation mechanism, which utilizes a single annotated image and a pre-trained diffusion model to propagate keypoints across an entire dataset, significantly reducing the cost of manual annotation. Additionally, we enhance the Vision Transformer (ViT) by implementing Keypoint Positional Encoding (KPE) and Categorical Keypoint Positional Embedding (CKPE), enabling the ViT to learn more robust and semantically-aware representations. This provides more comprehensive and detailed keypoint representations, leading to more accurate and efficient re-identification. Our extensive experimental evaluations demonstrate that this approach significantly outperforms existing state-of-the-art methods across four wildlife datasets. The code will be publicly released.
Learning for Visual Navigation by Imagining the Success
Feb 28, 2021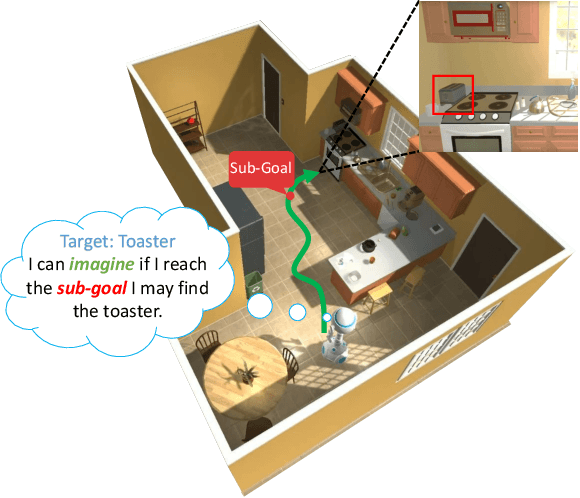
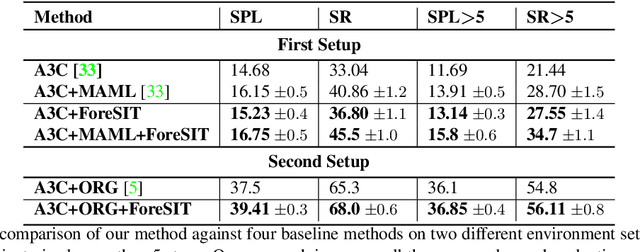
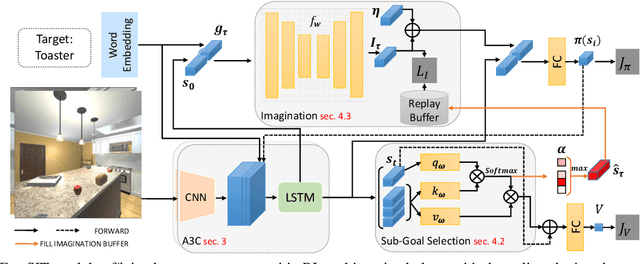
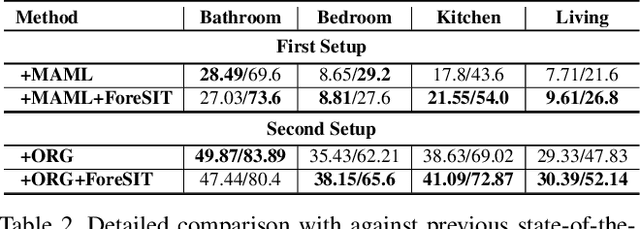
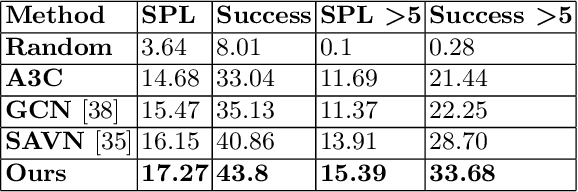
Visual navigation is often cast as a reinforcement learning (RL) problem. Current methods typically result in a suboptimal policy that learns general obstacle avoidance and search behaviours. For example, in the target-object navigation setting, the policies learnt by traditional methods often fail to complete the task, even when the target is clearly within reach from a human perspective. In order to address this issue, we propose to learn to imagine a latent representation of the successful (sub-)goal state. To do so, we have developed a module which we call Foresight Imagination (ForeSIT). ForeSIT is trained to imagine the recurrent latent representation of a future state that leads to success, e.g. either a sub-goal state that is important to reach before the target, or the goal state itself. By conditioning the policy on the generated imagination during training, our agent learns how to use this imagination to achieve its goal robustly. Our agent is able to imagine what the (sub-)goal state may look like (in the latent space) and can learn to navigate towards that state. We develop an efficient learning algorithm to train ForeSIT in an on-policy manner and integrate it into our RL objective. The integration is not trivial due to the constantly evolving state representation shared between both the imagination and the policy. We, empirically, observe that our method outperforms the state-of-the-art methods by a large margin in the commonly accepted benchmark AI2THOR environment. Our method can be readily integrated or added to other model-free RL navigation frameworks.
Joint learning of Social Groups, Individuals Action and Sub-group Activities in Videos
Jul 06, 2020
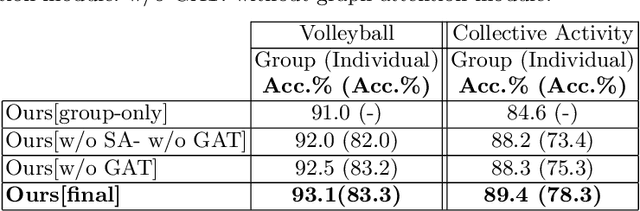
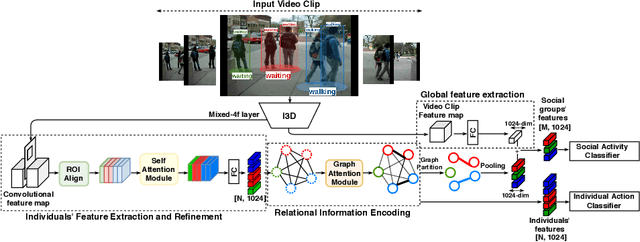
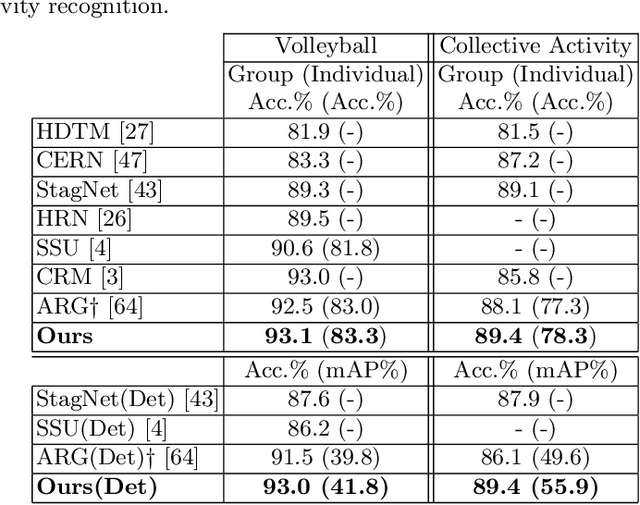
The state-of-the art solutions for human activity understanding from a video stream formulate the task as a spatio-temporal problem which requires joint localization of all individuals in the scene and classification of their actions or group activity over time. Who is interacting with whom, e.g. not everyone in a queue is interacting with each other, is often not predicted. There are scenarios where people are best to be split into sub-groups, which we call social groups, and each social group may be engaged in a different social activity. In this paper, we solve the problem of simultaneously grouping people by their social interactions, predicting their individual actions and the social activity of each social group, which we call the social task. Our main contributions are: i) we propose an end-to-end trainable framework for the social task; ii) our proposed method also sets the state-of-the-art results on two widely adopted benchmarks for the traditional group activity recognition task (assuming individuals of the scene form a single group and predicting a single group activity label for the scene); iii) we introduce new annotations on an existing group activity dataset, re-purposing it for the social task.
Utilising Prior Knowledge for Visual Navigation: Distil and Adapt
Apr 07, 2020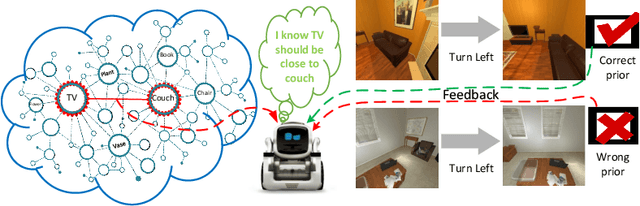
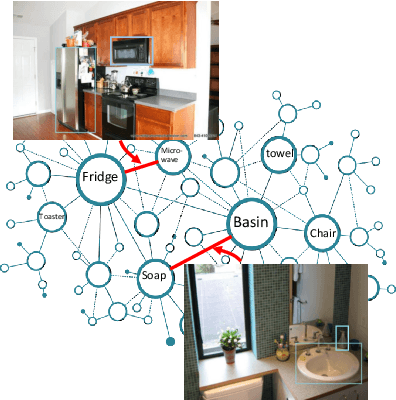
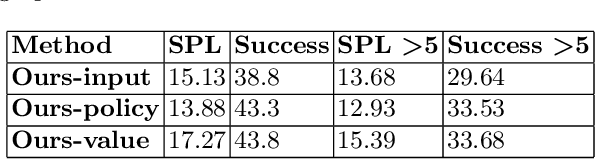
We, as humans, can impeccably navigate to localise a target object, even in an unseen environment. We argue that this impressive ability is largely due to incorporation of \emph{prior knowledge} (or experience) and \emph{visual cues}--that current visual navigation approaches lack. In this paper, we propose to use externally learned prior knowledge of object relations, which is integrated to our model via constructing a neural graph. To combine appropriate assessment of the states and the prior (knowledge), we propose to decompose the value function in the actor-critic reinforcement learning algorithm and incorporate the prior in the critic in a novel way that reduces the model complexity and improves model generalisation. Our approach outperforms the current state-of-the-art in AI2THOR visual navigation dataset.
MOT20: A benchmark for multi object tracking in crowded scenes
Mar 19, 2020
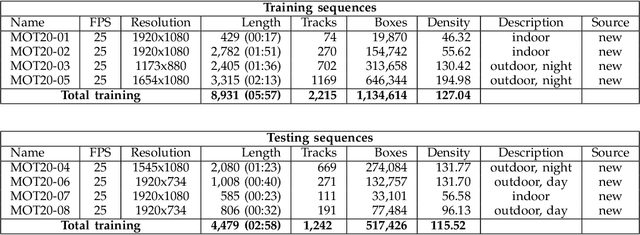

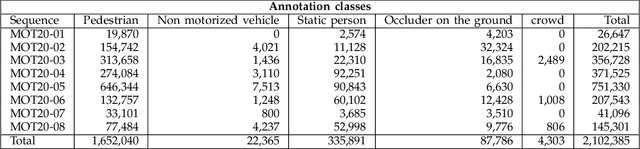
Standardized benchmarks are crucial for the majority of computer vision applications. Although leaderboards and ranking tables should not be over-claimed, benchmarks often provide the most objective measure of performance and are therefore important guides for research. The benchmark for Multiple Object Tracking, MOTChallenge, was launched with the goal to establish a standardized evaluation of multiple object tracking methods. The challenge focuses on multiple people tracking, since pedestrians are well studied in the tracking community, and precise tracking and detection has high practical relevance. Since the first release, MOT15, MOT16, and MOT17 have tremendously contributed to the community by introducing a clean dataset and precise framework to benchmark multi-object trackers. In this paper, we present our MOT20benchmark, consisting of 8 new sequences depicting very crowded challenging scenes. The benchmark was presented first at the 4thBMTT MOT Challenge Workshop at the Computer Vision and Pattern Recognition Conference (CVPR) 2019, and gives to chance to evaluate state-of-the-art methods for multiple object tracking when handling extremely crowded scenarios.
CVPR19 Tracking and Detection Challenge: How crowded can it get?
Jun 10, 2019
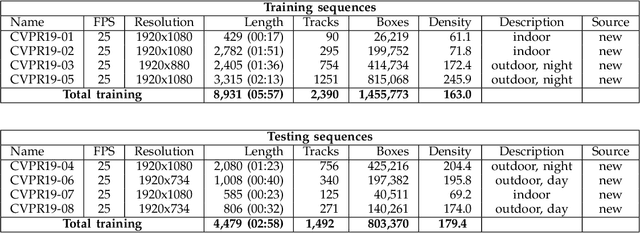

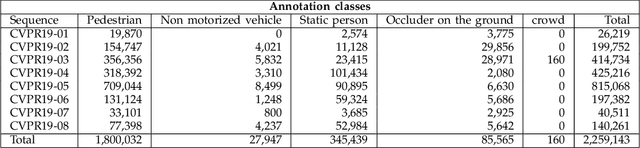
Standardized benchmarks are crucial for the majority of computer vision applications. Although leaderboards and ranking tables should not be over-claimed, benchmarks often provide the most objective measure of performance and are therefore important guides for research. The benchmark for Multiple Object Tracking, MOTChallenge, was launched with the goal to establish a standardized evaluation of multiple object tracking methods. The challenge focuses on multiple people tracking, since pedestrians are well studied in the tracking community, and precise tracking and detection has high practical relevance. Since the first release, MOT15, MOT16 and MOT17 have tremendously contributed to the community by introducing a clean dataset and precise framework to benchmark multi-object trackers. In this paper, we present our CVPR19 benchmark, consisting of 8 new sequences depicting very crowded challenging scenes. The benchmark will be presented at the 4th BMTT MOT Challenge Workshop at the Computer Vision and Pattern Recognition Conference (CVPR) 2019, and will evaluate the state-of-the-art in multiple object tracking whend handling extremely crowded scenarios.
Follow the Attention: Combining Partial Pose and Object Motion for Fine-Grained Action Detection
May 11, 2019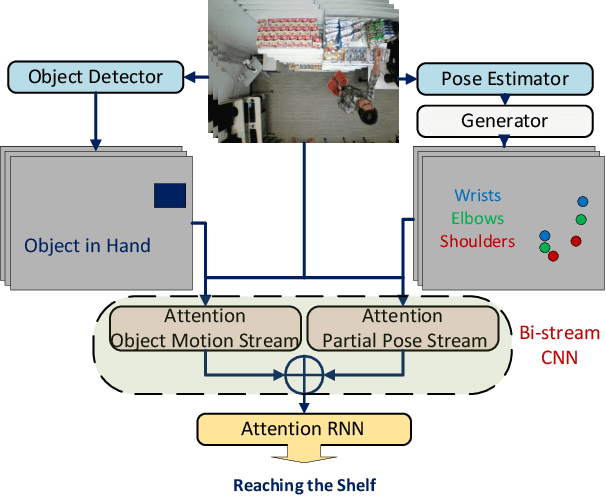
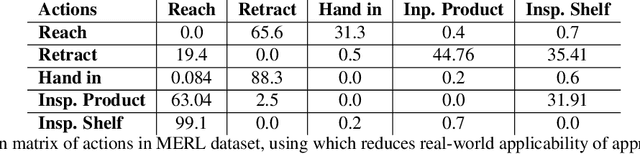


Activity recognition in shopping environments is an important and challenging computer vision task. We introduce a framework for integrating human body pose and object motion to both temporally detect and classify the activities in a fine-grained manner (very short and similar activities). We achieve this by proposing a multi-stream recurrent convolutional neural network architecture guided by the spatiotemporal \emph{attention} mechanism for both activity recognition and detection. To this end, in the absence of accurate pose supervision, we incorporate generative adversarial networks (GANs) to generate candidate body joints. Additionally, based on the intuition that complex actions demand more than one source of information to be precisely identified even by humans, we integrate the second stream of the object motion to our network that acts as a prior knowledge which we quantitatively show improves the results. Furthermore, we empirically show the capabilities of our approach by achieving state-of-the-art results on MERL shopping dataset. Finally, we further investigate the effectiveness of this approach on a new shopping dataset that we have collected to address existing shortcomings in this area including but not limited to lack of training data.