 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Active Information Seeking Model for Goal-oriented Vision-and-Language Tasks
Paper and Code
Dec 16, 2018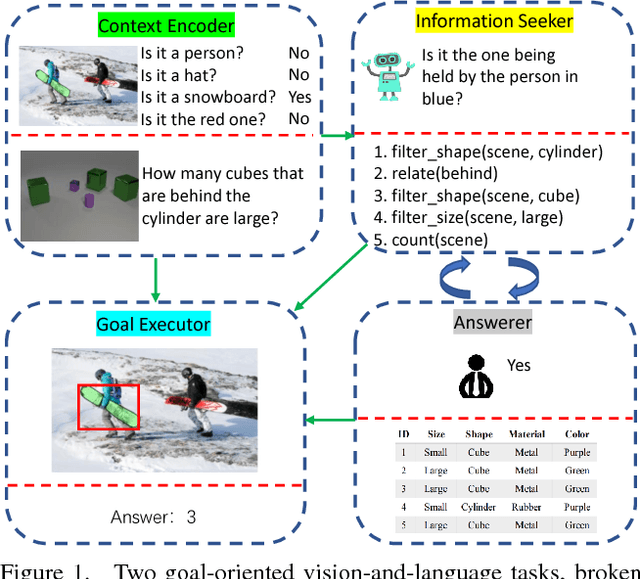
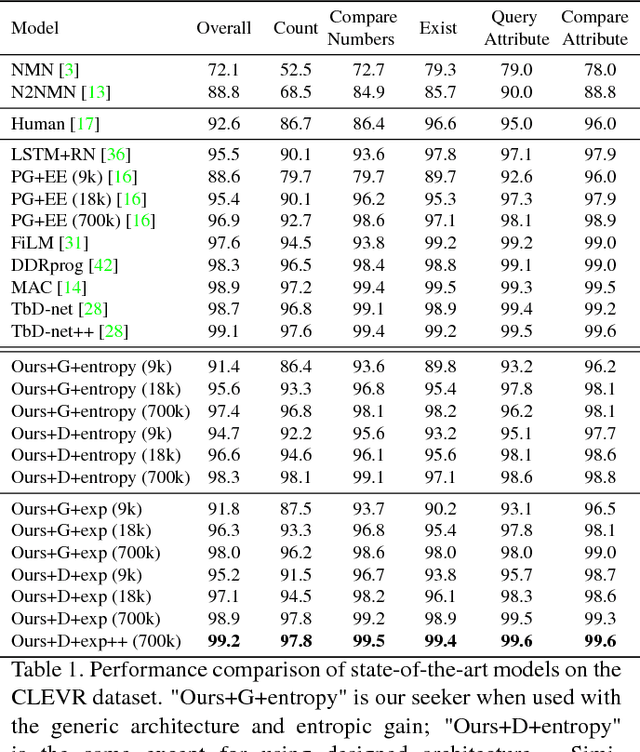
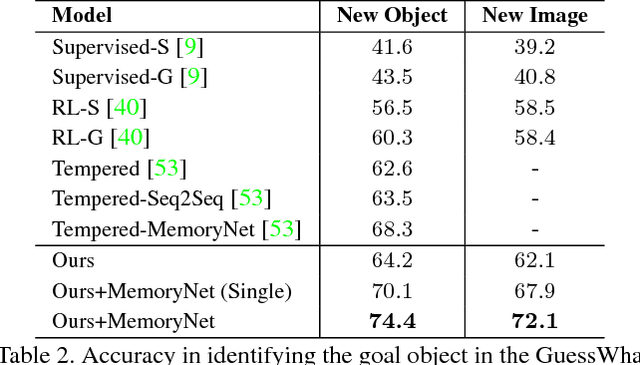
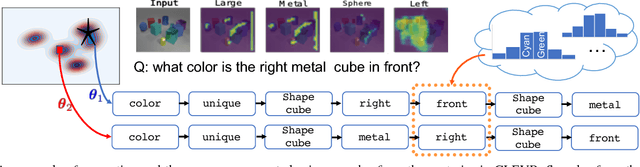
As Computer Vision algorithms move from passive analysis of pixels to active reasoning over semantics, the breadth of information algorithms need to reason over has expanded significantly. One of the key challenges in this vein is the ability to identify the information required to make a decision, and select an action that will recover this information. We propose an reinforcement-learning approach that maintains an distribution over its internal information, thus explicitly representing the ambiguity in what it knows, and needs to know, towards achieving its goal. Potential actions are then generated according to particles sampled from this distribution. For each potential action a distribution of the expected answers is calculated, and the value of the information gained is obtained, as compared to the existing internal information. We demonstrate this approach applied to two vision-language problems that have attracted significant recent interest, visual dialogue and visual query generation. In both cases the method actively selects actions that will best reduce its internal uncertainty, and outperforms its competitors in achieving the goal of the challenge.