 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyelid Fold Consistency in Facial Modeling
Oct 17, 2024



Eyelid shape is integral to identity and likeness in human facial modeling. Human eyelids are diverse in appearance with varied skin fold and epicanthal fold morphology between individuals. Existing parametric face models express eyelid shape variation to an extent, but do not preserve sufficient likeness across a diverse range of individuals. We propose a new definition of eyelid fold consistency and implement geometric processing techniques to model diverse eyelid shapes in a unified topology. Using this method we reprocess data used to train a parametric face model and demonstrate significant improvements in face-related machine learning tasks.
Look Ma, no markers: holistic performance capture without the hassle
Oct 15, 2024



We tackle the problem of highly-accurate, holistic performance capture for the face, body and hands simultaneously. Motion-capture technologies used in film and game production typically focus only on face, body or hand capture independently, involve complex and expensive hardware and a high degree of manual intervention from skilled operators. While machine-learning-based approaches exist to overcome these problems, they usually only support a single camera, often operate on a single part of the body, do not produce precise world-space results, and rarely generalize outside specific contexts. In this work, we introduce the first technique for marker-free, high-quality reconstruction of the complete human body, including eyes and tongue, without requiring any calibration, manual intervention or custom hardware. Our approach produces stable world-space results from arbitrary camera rigs as well as supporting varied capture environments and clothing. We achieve this through a hybrid approach that leverages machine learning models trained exclusively on synthetic data and powerful parametric models of human shape and motion. We evaluate our method on a number of body, face and hand reconstruction benchmarks and demonstrate state-of-the-art results that generalize on diverse datasets.
HMD-NeMo: Online 3D Avatar Motion Generation From Sparse Observations
Aug 22, 2023



Generating both plausible and accurate full body avatar motion is the key to the quality of immersive experiences in mixed reality scenarios. Head-Mounted Devices (HMDs) typically only provide a few input signals, such as head and hands 6-DoF. Recently, different approaches achieved impressive performance in generating full body motion given only head and hands signal. However, to the best of our knowledge, all existing approaches rely on full hand visibility. While this is the case when, e.g., using motion controllers, a considerable proportion of mixed reality experiences do not involve motion controllers and instead rely on egocentric hand tracking. This introduces the challenge of partial hand visibility owing to the restricted field of view of the HMD. In this paper, we propose the first unified approach, HMD-NeMo, that addresses plausible and accurate full body motion generation even when the hands may be only partially visible. HMD-NeMo is a lightweight neural network that predicts the full body motion in an online and real-time fashion. At the heart of HMD-NeMo is the spatio-temporal encoder with novel temporally adaptable mask tokens that encourage plausible motion in the absence of hand observations. We perform extensive analysis of the impact of different components in HMD-NeMo and introduce a new state-of-the-art on AMASS dataset through our evaluation.
Effective Self-supervised Pre-training on Low-compute networks without Distillation
Oct 06, 2022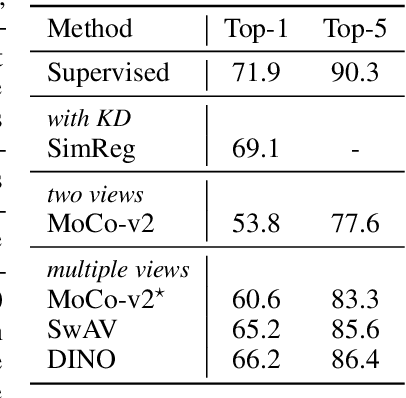
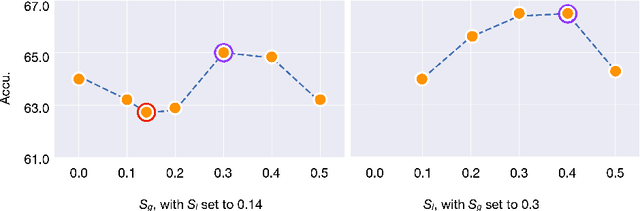

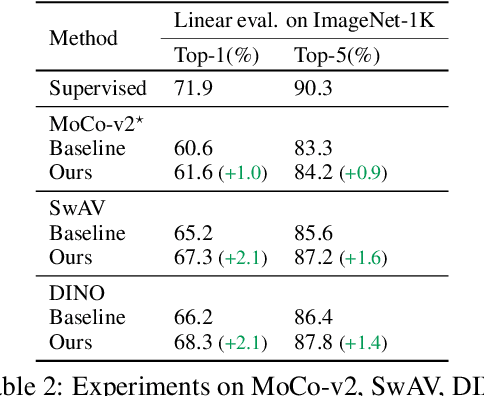
Despite the impressive progress of self-supervised learning (SSL), its applicability to low-compute networks has received limited attention. Reported performance has trailed behind standard supervised pre-training by a large margin, barring self-supervised learning from making an impact on models that are deployed on device. Most prior works attribute this poor performance to the capacity bottleneck of the low-compute networks and opt to bypass the problem through the use of knowledge distillation (KD). In this work, we revisit SSL for efficient neural networks, taking a closer at what are the detrimental factors causing the practical limitations, and whether they are intrinsic to the self-supervised low-compute setting. We find that, contrary to accepted knowledge, there is no intrinsic architectural bottleneck, we diagnose that the performance bottleneck is related to the model complexity vs regularization strength trade-off. In particular, we start by empirically observing that the use of local views can have a dramatic impact on the effectiveness of the SSL methods. This hints at view sampling being one of the performance bottlenecks for SSL on low-capacity networks. We hypothesize that the view sampling strategy for large neural networks, which requires matching views in very diverse spatial scales and contexts, is too demanding for low-capacity architectures. We systematize the design of the view sampling mechanism, leading to a new training methodology that consistently improves the performance across different SSL methods (e.g. MoCo-v2, SwAV, DINO), different low-size networks (e.g. MobileNetV2, ResNet18, ResNet34, ViT-Ti), and different tasks (linear probe, object detection, instance segmentation and semi-supervised learning). Our best models establish a new state-of-the-art for SSL methods on low-compute networks despite not using a KD loss term.
iBoot: Image-bootstrapped Self-Supervised Video Representation Learning
Jun 16, 2022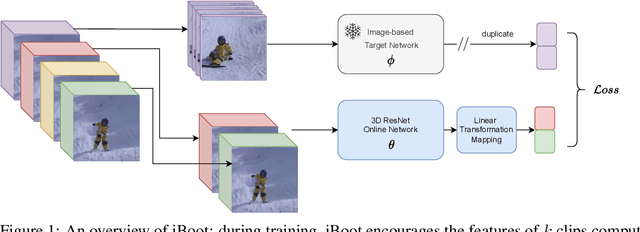



Learning visual representations through self-supervision is an extremely challenging task as the network needs to sieve relevant patterns from spurious distractors without the active guidance provided by supervision. This is achieved through heavy data augmentation, large-scale datasets and prohibitive amounts of compute. Video self-supervised learning (SSL) suffers from added challenges: video datasets are typically not as large as image datasets, compute is an order of magnitude larger, and the amount of spurious patterns the optimizer has to sieve through is multiplied several fold. Thus, directly learning self-supervised representations from video data might result in sub-optimal performance. To address this, we propose to utilize a strong image-based model, pre-trained with self- or language supervision, in a video representation learning framework, enabling the model to learn strong spatial and temporal information without relying on the video labeled data. To this end, we modify the typical video-based SSL design and objective to encourage the video encoder to \textit{subsume} the semantic content of an image-based model trained on a general domain. The proposed algorithm is shown to learn much more efficiently (i.e. in less epochs and with a smaller batch) and results in a new state-of-the-art performance on standard downstream tasks among single-modality SSL methods.
JRDB-Act: A Large-scale Multi-modal Dataset for Spatio-temporal Action, Social Group and Activity Detection
Jun 16, 2021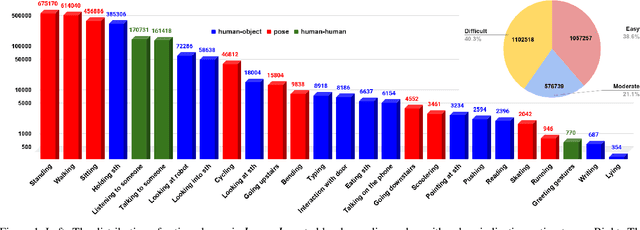
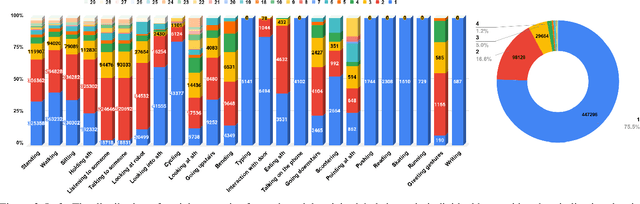
The availability of large-scale video action understanding datasets has facilitated advances in the interpretation of visual scenes containing people. However, learning to recognize human activities in an unconstrained real-world environment, with potentially highly unbalanced and long-tailed distributed data remains a significant challenge, not least owing to the lack of a reflective large-scale dataset. Most existing large-scale datasets are either collected from a specific or constrained environment, e.g. kitchens or rooms, or video sharing platforms such as YouTube. In this paper, we introduce JRDB-Act, a multi-modal dataset, as an extension of the existing JRDB, which is captured by asocial mobile manipulator and reflects a real distribution of human daily life actions in a university campus environment. JRDB-Act has been densely annotated with atomic actions, comprises over 2.8M action labels, constituting a large-scale spatio-temporal action detection dataset. Each human bounding box is labelled with one pose-based action label and multiple (optional) interaction-based action labels. Moreover JRDB-Act comes with social group identification annotations conducive to the task of grouping individuals based on their interactions in the scene to infer their social activities (common activities in each social group).
Probabilistic Tracklet Scoring and Inpainting for Multiple Object Tracking
Dec 10, 2020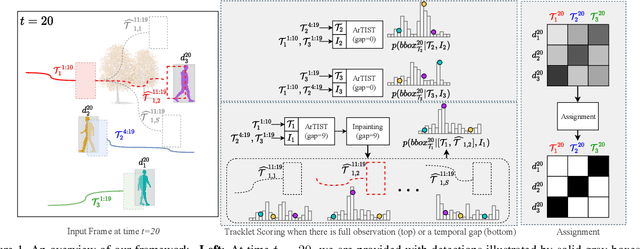
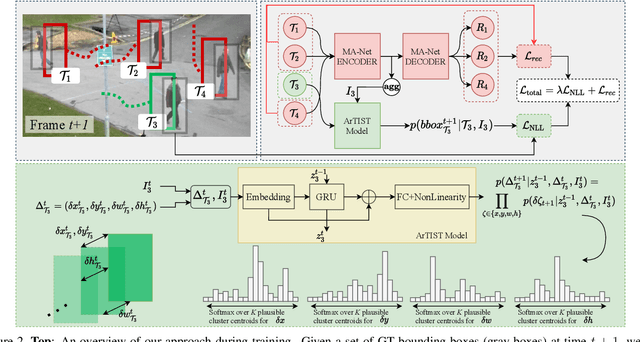
Despite the recent advances in multiple object tracking (MOT), achieved by joint detection and tracking, dealing with long occlusions remains a challenge. This is due to the fact that such techniques tend to ignore the long-term motion information. In this paper, we introduce a probabilistic autoregressive motion model to score tracklet proposals by directly measuring their likelihood. This is achieved by training our model to learn the underlying distribution of natural tracklets. As such, our model allows us not only to assign new detections to existing tracklets, but also to inpaint a tracklet when an object has been lost for a long time, e.g., due to occlusion, by sampling tracklets so as to fill the gap caused by misdetections. Our experiments demonstrate the superiority of our approach at tracking objects in challenging sequences; it outperforms the state of the art in most standard MOT metrics on multiple MOT benchmark datasets, including MOT16, MOT17, and MOT20.
Uncertainty Inspired RGB-D Saliency Detection
Sep 07, 2020
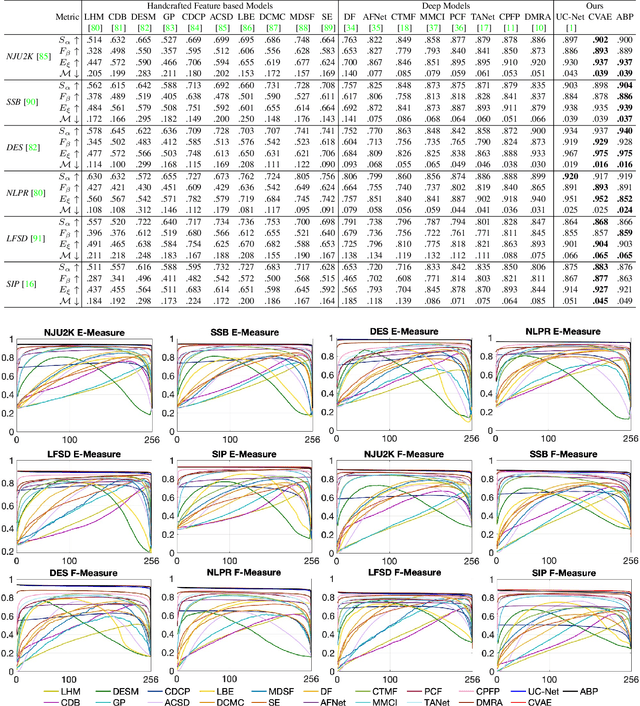
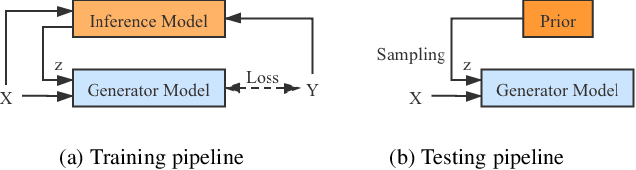

We propose the first stochastic framework to employ uncertainty for RGB-D saliency detection by learning from the data labeling process. Existing RGB-D saliency detection models treat this task as a point estimation problem by predicting a single saliency map following a deterministic learning pipeline. We argue that, however, the deterministic solution is relatively ill-posed. Inspired by the saliency data labeling process, we propose a generative architecture to achieve probabilistic RGB-D saliency detection which utilizes a latent variable to model the labeling variations. Our framework includes two main models: 1) a generator model, which maps the input image and latent variable to stochastic saliency prediction, and 2) an inference model, which gradually updates the latent variable by sampling it from the true or approximate posterior distribution. The generator model is an encoder-decoder saliency network. To infer the latent variable, we introduce two different solutions: i) a Conditional Variational Auto-encoder with an extra encoder to approximate the posterior distribution of the latent variable; and ii) an Alternating Back-Propagation technique, which directly samples the latent variable from the true posterior distribution. Qualitative and quantitative results on six challenging RGB-D benchmark datasets show our approach's superior performance in learning the distribution of saliency maps. The source code is publicly available via our project page: https://github.com/JingZhang617/UCNet.
Joint learning of Social Groups, Individuals Action and Sub-group Activities in Videos
Jul 06, 2020
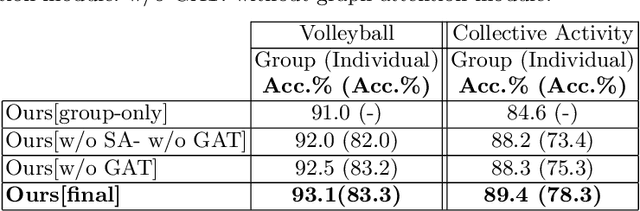
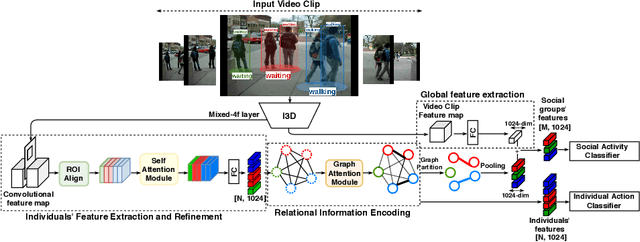
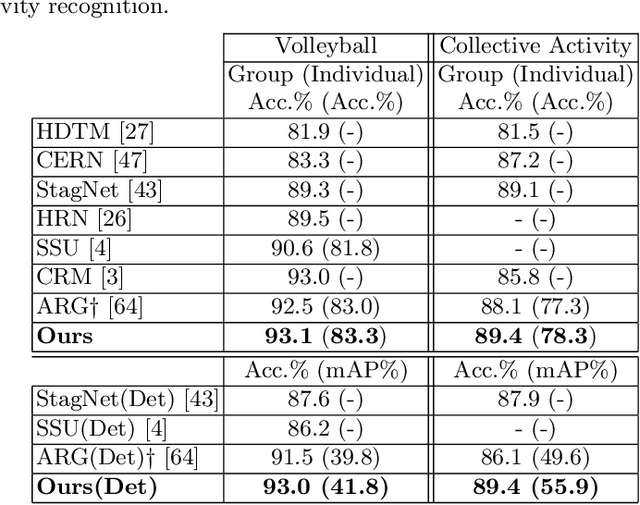
The state-of-the art solutions for human activity understanding from a video stream formulate the task as a spatio-temporal problem which requires joint localization of all individuals in the scene and classification of their actions or group activity over time. Who is interacting with whom, e.g. not everyone in a queue is interacting with each other, is often not predicted. There are scenarios where people are best to be split into sub-groups, which we call social groups, and each social group may be engaged in a different social activity. In this paper, we solve the problem of simultaneously grouping people by their social interactions, predicting their individual actions and the social activity of each social group, which we call the social task. Our main contributions are: i) we propose an end-to-end trainable framework for the social task; ii) our proposed method also sets the state-of-the-art results on two widely adopted benchmarks for the traditional group activity recognition task (assuming individuals of the scene form a single group and predicting a single group activity label for the scene); iii) we introduce new annotations on an existing group activity dataset, re-purposing it for the social task.
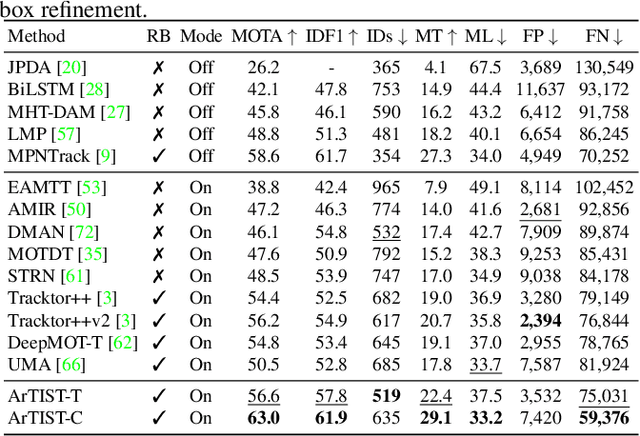
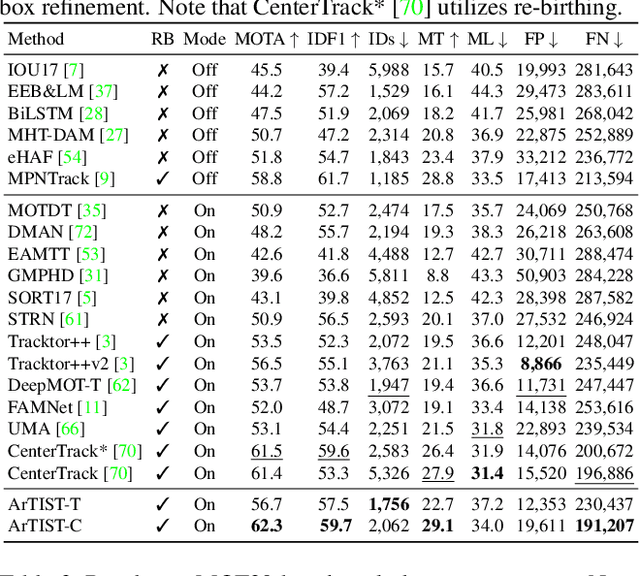
ArTIST: Autoregressive Trajectory Inpainting and Scoring for Tracking
Apr 16, 2020
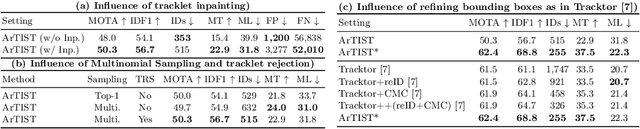
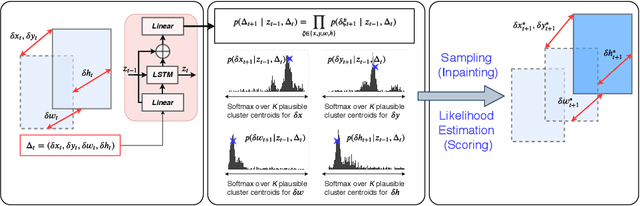
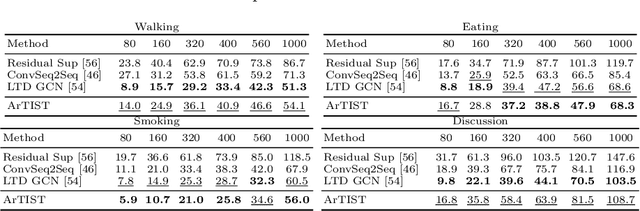
One of the core components in online multiple object tracking (MOT) frameworks is associating new detections with existing tracklets, typically done via a scoring function. Despite the great advances in MOT, designing a reliable scoring function remains a challenge. In this paper, we introduce a probabilistic autoregressive generative model to score tracklet proposals by directly measuring the likelihood that a tracklet represents natural motion. One key property of our model is its ability to generate multiple likely futures of a tracklet given partial observations. This allows us to not only score tracklets but also effectively maintain existing tracklets when the detector fails to detect some objects even for a long time, e.g., due to occlusion, by sampling trajectories so as to inpaint the gaps caused by misdetection. Our experiments demonstrate the effectiveness of our approach to scoring and inpainting tracklets on several MOT benchmark datasets. We additionally show the generality of our generative model by using it to produce future representations in the challenging task of human motion prediction.