 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiBoot: Image-bootstrapped Self-Supervised Video Representation Learning
Paper and Code
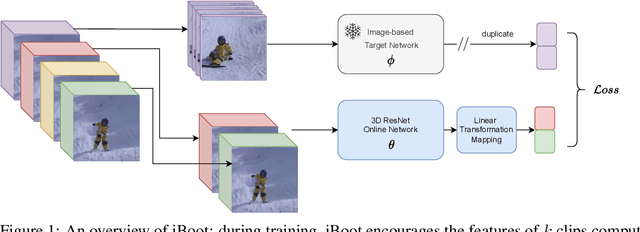



Learning visual representations through self-supervision is an extremely challenging task as the network needs to sieve relevant patterns from spurious distractors without the active guidance provided by supervision. This is achieved through heavy data augmentation, large-scale datasets and prohibitive amounts of compute. Video self-supervised learning (SSL) suffers from added challenges: video datasets are typically not as large as image datasets, compute is an order of magnitude larger, and the amount of spurious patterns the optimizer has to sieve through is multiplied several fold. Thus, directly learning self-supervised representations from video data might result in sub-optimal performance. To address this, we propose to utilize a strong image-based model, pre-trained with self- or language supervision, in a video representation learning framework, enabling the model to learn strong spatial and temporal information without relying on the video labeled data. To this end, we modify the typical video-based SSL design and objective to encourage the video encoder to \textit{subsume} the semantic content of an image-based model trained on a general domain. The proposed algorithm is shown to learn much more efficiently (i.e. in less epochs and with a smaller batch) and results in a new state-of-the-art performance on standard downstream tasks among single-modality SSL methods.