 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilising Prior Knowledge for Visual Navigation: Distil and Adapt
Paper and Code
Apr 07, 2020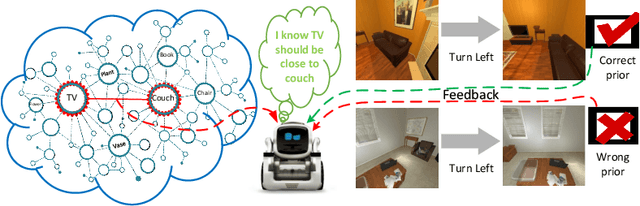
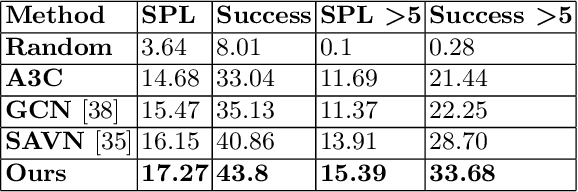
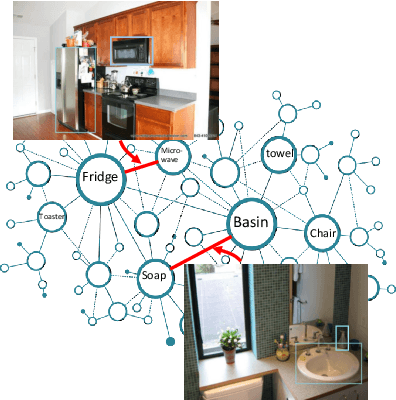
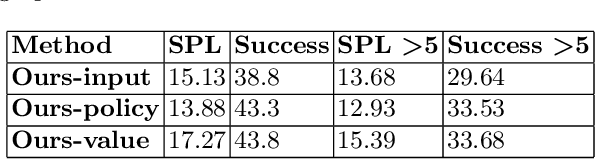
We, as humans, can impeccably navigate to localise a target object, even in an unseen environment. We argue that this impressive ability is largely due to incorporation of \emph{prior knowledge} (or experience) and \emph{visual cues}--that current visual navigation approaches lack. In this paper, we propose to use externally learned prior knowledge of object relations, which is integrated to our model via constructing a neural graph. To combine appropriate assessment of the states and the prior (knowledge), we propose to decompose the value function in the actor-critic reinforcement learning algorithm and incorporate the prior in the critic in a novel way that reduces the model complexity and improves model generalisation. Our approach outperforms the current state-of-the-art in AI2THOR visual navigation dataset.