 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning by Feature Mixing
Mar 14, 2022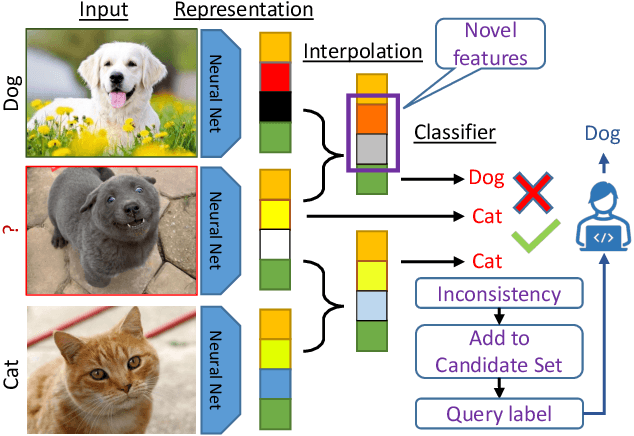
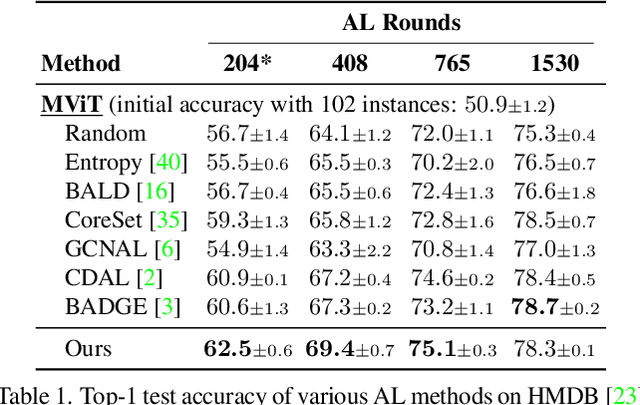
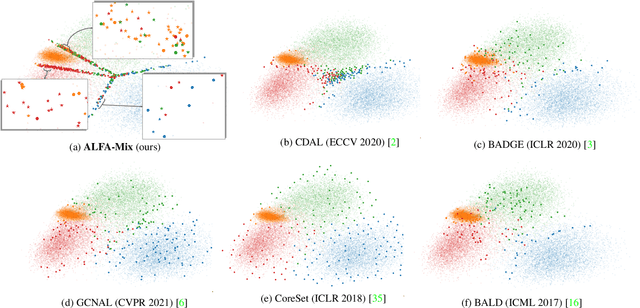
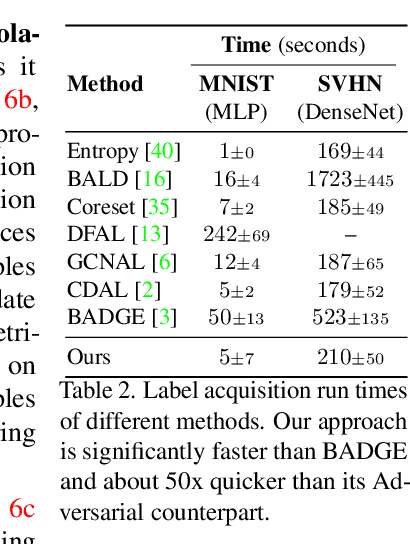
The promise of active learning (AL) is to reduce labelling costs by selecting the most valuable examples to annotate from a pool of unlabelled data. Identifying these examples is especially challenging with high-dimensional data (e.g. images, videos) and in low-data regimes. In this paper, we propose a novel method for batch AL called ALFA-Mix. We identify unlabelled instances with sufficiently-distinct features by seeking inconsistencies in predictions resulting from interventions on their representations. We construct interpolations between representations of labelled and unlabelled instances then examine the predicted labels. We show that inconsistencies in these predictions help discovering features that the model is unable to recognise in the unlabelled instances. We derive an efficient implementation based on a closed-form solution to the optimal interpolation causing changes in predictions. Our method outperforms all recent AL approaches in 30 different settings on 12 benchmarks of images, videos, and non-visual data. The improvements are especially significant in low-data regimes and on self-trained vision transformers, where ALFA-Mix outperforms the state-of-the-art in 59% and 43% of the experiments respectively.
Show, Price and Negotiate: A Hierarchical Attention Recurrent Visual Negotiator
May 07, 2019
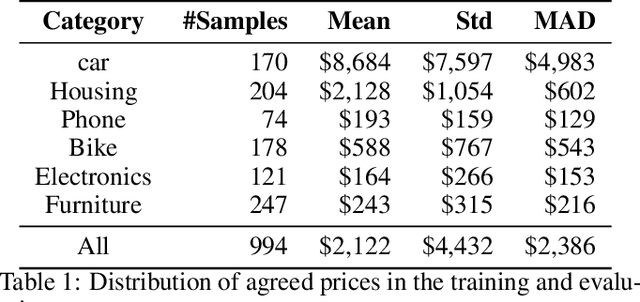
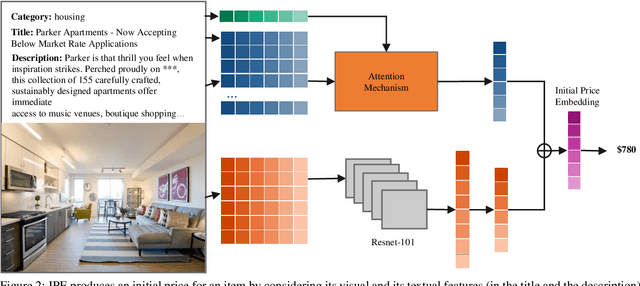
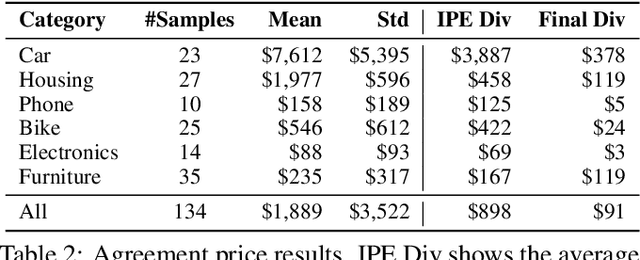
Negotiation, as a seller or buyer, is an essential and complicated aspect of online shopping. It is challenging for an intelligent agent because it requires (1) extracting and utilising information from multiple sources (e.g. photos, texts, and numerals), (2) predicting a suitable price for the products to reach the best possible agreement, (3) expressing the intention conditioned on the price in a natural language and (4) consistent pricing. Conventional dialog systems do not address these problems well. For example, we believe that the price should be the driving factor for the negotiation and understood by the agent. But conventionally, the price was simply treated as a word token i.e. being part of a sentence and sharing the same word embedding space with other words. To that end, we propose our Visual Negotiator that comprises of an end-to-end deep learning model that anticipates an initial agreement price and updates it while generating compelling supporting dialog. For (1), our visual negotiator utilises attention mechanism to extract relevant information from the images and textual description, and feeds the price (and later refined price) as separate important input to several stages of the system, instead of simply being part of a sentence; For (2), we use the attention to learn a price embedding to estimate an initial value; Subsequently, for (3) we generate the supporting dialog in an encoder-decoder fashion that utilises the price embedding. Further, we use a hierarchical recurrent model that learns to refine the price at one level while generating the supporting dialog in another; For (4), this hierarchical model provides consistent pricing. Empirically, we show that our model significantly improves negotiation on the CraigslistBargain dataset, in terms of the agreement price, price consistency, and the language quality.