 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSAT: Graph Structure Attention Networks
May 27, 2025Graph Neural Networks (GNNs) have emerged as a powerful tool for processing data represented in graph structures, achieving remarkable success across a wide range of applications. However, to further improve the performance on graph classification benchmarks, structural representation of each node that encodes rich local topological information in the neighbourhood of nodes is an important type of feature that is often overlooked in the modeling. The consequence of neglecting the structural information has resulted high number of layers to connect messages from distant nodes which by itself produces other problems such as oversmoothing. In the present paper, we leverage these structural information that are modeled by anonymous random walks (ARWs) and introduce graph structure attention network (GSAT) which is a generalization of graph attention network(GAT) to integrate the original attribute and the structural representation to enforce the model to automatically find patterns for attending to different edges in the node neighbourhood to enrich graph representation. Our experiments show GSAT slightly improves SOTA on some graph classification benchmarks.
LGRPool: Hierarchical Graph Pooling Via Local-Global Regularisation
Apr 11, 2025Hierarchical graph pooling(HGP) are designed to consider the fact that conventional graph neural networks(GNN) are inherently flat and are also not multiscale. However, most HGP methods suffer not only from lack of considering global topology of the graph and focusing on the feature learning aspect, but also they do not align local and global features since graphs should inherently be analyzed in a multiscale way. LGRPool is proposed in the present paper as a HGP in the framework of expectation maximization in machine learning that aligns local and global aspects of message passing with each other using a regularizer to force the global topological information to be inline with the local message passing at different scales through the representations at different layers of HGP. Experimental results on some graph classification benchmarks show that it slightly outperforms some baselines.
Leveraging Full Dependency Parsing Graph Information For Biomedical Event Extraction
Jan 02, 2025



Many models are proposed in the literature on biomedical event extraction(BEE). Some of them use the shortest dependency path(SDP) information to represent the argument classification task. There is an issue with this representation since even missing one word from the dependency parsing graph may totally change the final prediction. To this end, the full adjacency matrix of the dependency graph is used to embed individual tokens using a graph convolutional network(GCN). An ablation study is also done to show the effect of the dependency graph on the overall performance. The results show a significant improvement when dependency graph information is used. The proposed model slightly outperforms state-of-the-art models on BEE over different datasets.
Toward the Automated Construction of Probabilistic Knowledge Graphs for the Maritime Domain
May 04, 2023



International maritime crime is becoming increasingly sophisticated, often associated with wider criminal networks. Detecting maritime threats by means of fusing data purely related to physical movement (i.e., those generated by physical sensors, or hard data) is not sufficient. This has led to research and development efforts aimed at combining hard data with other types of data (especially human-generated or soft data). Existing work often assumes that input soft data is available in a structured format, or is focused on extracting certain relevant entities or concepts to accompany or annotate hard data. Much less attention has been given to extracting the rich knowledge about the situations of interest implicitly embedded in the large amount of soft data existing in unstructured formats (such as intelligence reports and news articles). In order to exploit the potentially useful and rich information from such sources, it is necessary to extract not only the relevant entities and concepts but also their semantic relations, together with the uncertainty associated with the extracted knowledge (i.e., in the form of probabilistic knowledge graphs). This will increase the accuracy of and confidence in, the extracted knowledge and facilitate subsequent reasoning and learning. To this end, we propose Maritime DeepDive, an initial prototype for the automated construction of probabilistic knowledge graphs from natural language data for the maritime domain. In this paper, we report on the current implementation of Maritime DeepDive, together with preliminary results on extracting probabilistic events from maritime piracy incidents. This pipeline was evaluated on a manually crafted gold standard, yielding promising results.
Few-shot Domain-Adaptive Visually-fused Event Detection from Text
May 04, 2023



Incorporating auxiliary modalities such as images into event detection models has attracted increasing interest over the last few years. The complexity of natural language in describing situations has motivated researchers to leverage the related visual context to improve event detection performance. However, current approaches in this area suffer from data scarcity, where a large amount of labelled text-image pairs are required for model training. Furthermore, limited access to the visual context at inference time negatively impacts the performance of such models, which makes them practically ineffective in real-world scenarios. In this paper, we present a novel domain-adaptive visually-fused event detection approach that can be trained on a few labelled image-text paired data points. Specifically, we introduce a visual imaginator method that synthesises images from text in the absence of visual context. Moreover, the imaginator can be customised to a specific domain. In doing so, our model can leverage the capabilities of pre-trained vision-language models and can be trained in a few-shot setting. This also allows for effective inference where only single-modality data (i.e. text) is available. The experimental evaluation on the benchmark M2E2 dataset shows that our model outperforms existing state-of-the-art models, by up to 11 points.
Graph Sequential Neural ODE Process for Link Prediction on Dynamic and Sparse Graphs
Nov 15, 2022Link prediction on dynamic graphs is an important task in graph mining. Existing approaches based on dynamic graph neural networks (DGNNs) typically require a significant amount of historical data (interactions over time), which is not always available in practice. The missing links over time, which is a common phenomenon in graph data, further aggravates the issue and thus creates extremely sparse and dynamic graphs. To address this problem, we propose a novel method based on the neural process, called Graph Sequential Neural ODE Process (GSNOP). Specifically, GSNOP combines the advantage of the neural process and neural ordinary differential equation that models the link prediction on dynamic graphs as a dynamic-changing stochastic process. By defining a distribution over functions, GSNOP introduces the uncertainty into the predictions, making it generalize to more situations instead of overfitting to the sparse data. GSNOP is also agnostic to model structures that can be integrated with any DGNN to consider the chronological and geometrical information for link prediction. Extensive experiments on three dynamic graph datasets show that GSNOP can significantly improve the performance of existing DGNNs and outperform other neural process variants.
MARLIN: Masked Autoencoder for facial video Representation LearnINg
Nov 12, 2022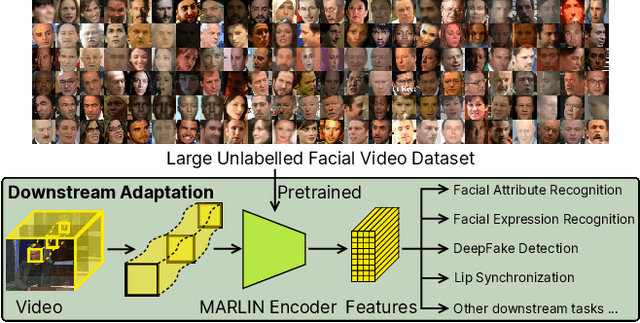
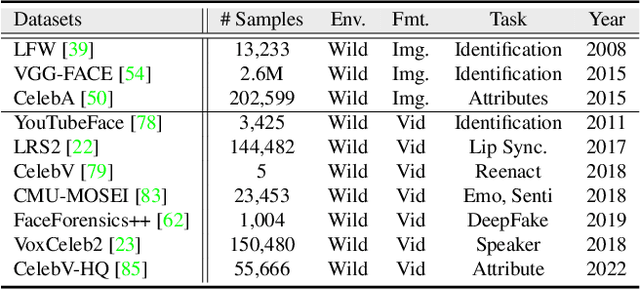
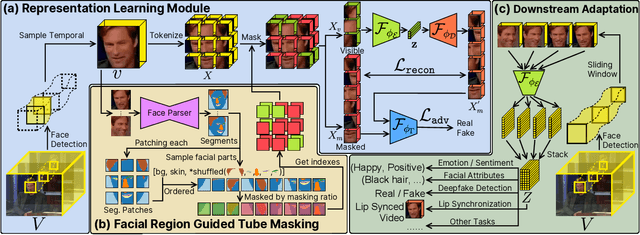
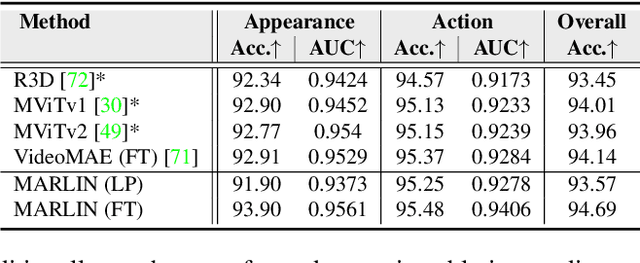
This paper proposes a self-supervised approach to learn universal facial representations from videos, that can transfer across a variety of facial analysis tasks such as Facial Attribute Recognition (FAR), Facial Expression Recognition (FER), DeepFake Detection (DFD), and Lip Synchronization (LS). Our proposed framework, named MARLIN, is a facial video masked autoencoder, that learns highly robust and generic facial embeddings from abundantly available non-annotated web crawled facial videos. As a challenging auxiliary task, MARLIN reconstructs the spatio-temporal details of the face from the densely masked facial regions which mainly include eyes, nose, mouth, lips, and skin to capture local and global aspects that in turn help in encoding generic and transferable features. Through a variety of experiments on diverse downstream tasks, we demonstrate MARLIN to be an excellent facial video encoder as well as feature extractor, that performs consistently well across a variety of downstream tasks including FAR (1.13% gain over supervised benchmark), FER (2.64% gain over unsupervised benchmark), DFD (1.86% gain over unsupervised benchmark), LS (29.36% gain for Frechet Inception Distance), and even in low data regime. Our codes and pre-trained models will be made public.
Paraphrasing Techniques for Maritime QA system
Mar 21, 2022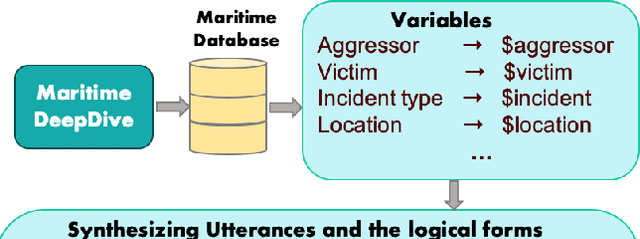
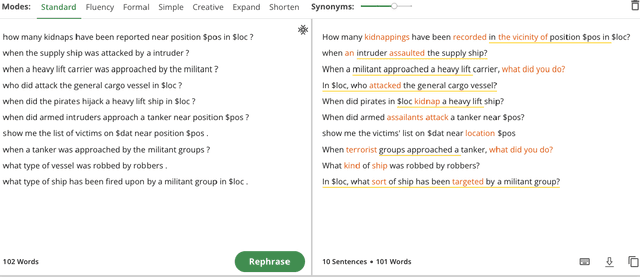

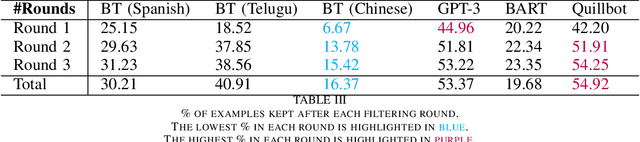
There has been an increasing interest in incorporating Artificial Intelligence (AI) into Defence and military systems to complement and augment human intelligence and capabilities. However, much work still needs to be done toward achieving an effective human-machine partnership. This work is aimed at enhancing human-machine communications by developing a capability for automatically translating human natural language into a machine-understandable language (e.g., SQL queries). Techniques toward achieving this goal typically involve building a semantic parser trained on a very large amount of high-quality manually-annotated data. However, in many real-world Defence scenarios, it is not feasible to obtain such a large amount of training data. To the best of our knowledge, there are few works trying to explore the possibility of training a semantic parser with limited manually-paraphrased data, in other words, zero-shot. In this paper, we investigate how to exploit paraphrasing methods for the automated generation of large-scale training datasets (in the form of paraphrased utterances and their corresponding logical forms in SQL format) and present our experimental results using real-world data in the maritime domain.
Active Learning by Feature Mixing
Mar 14, 2022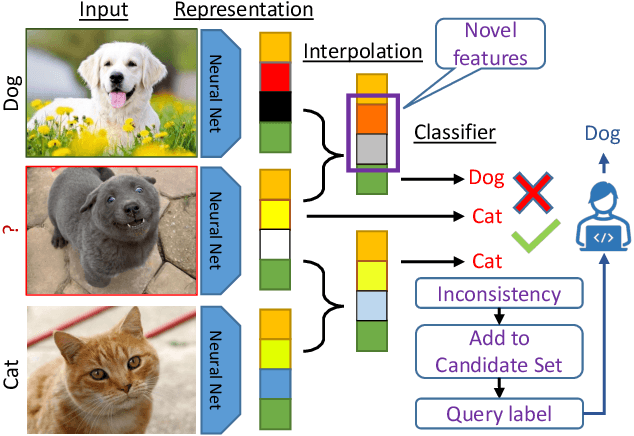
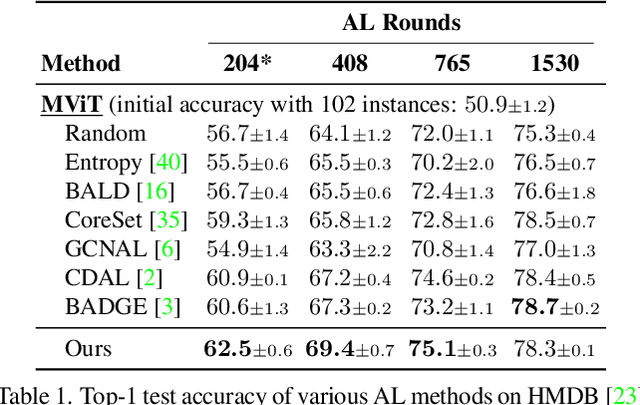
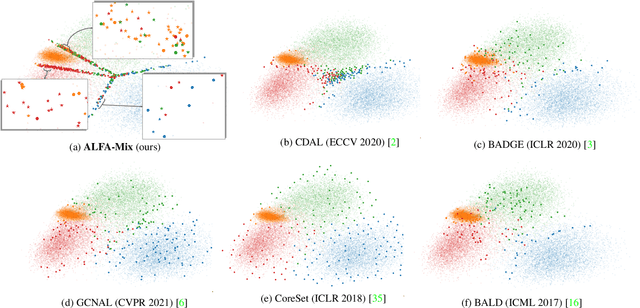
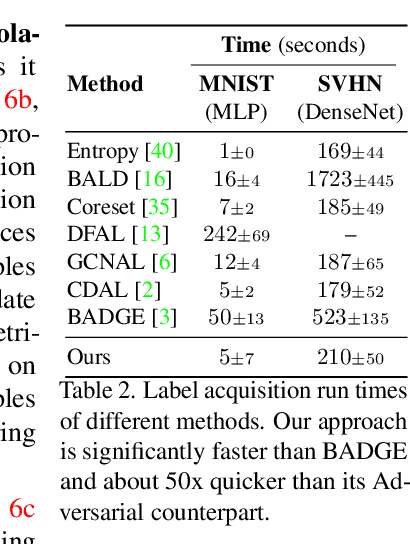
The promise of active learning (AL) is to reduce labelling costs by selecting the most valuable examples to annotate from a pool of unlabelled data. Identifying these examples is especially challenging with high-dimensional data (e.g. images, videos) and in low-data regimes. In this paper, we propose a novel method for batch AL called ALFA-Mix. We identify unlabelled instances with sufficiently-distinct features by seeking inconsistencies in predictions resulting from interventions on their representations. We construct interpolations between representations of labelled and unlabelled instances then examine the predicted labels. We show that inconsistencies in these predictions help discovering features that the model is unable to recognise in the unlabelled instances. We derive an efficient implementation based on a closed-form solution to the optimal interpolation causing changes in predictions. Our method outperforms all recent AL approaches in 30 different settings on 12 benchmarks of images, videos, and non-visual data. The improvements are especially significant in low-data regimes and on self-trained vision transformers, where ALFA-Mix outperforms the state-of-the-art in 59% and 43% of the experiments respectively.
iDARTS: Differentiable Architecture Search with Stochastic Implicit Gradients
Jun 21, 2021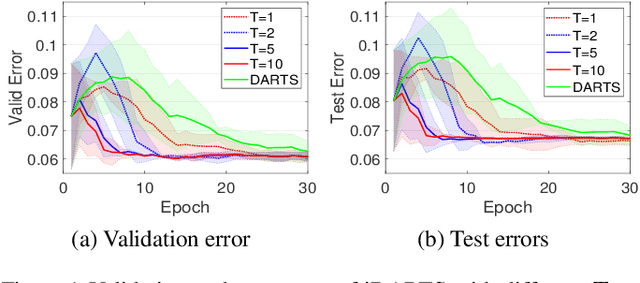
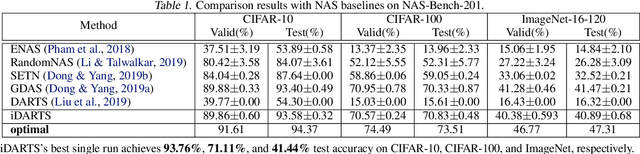
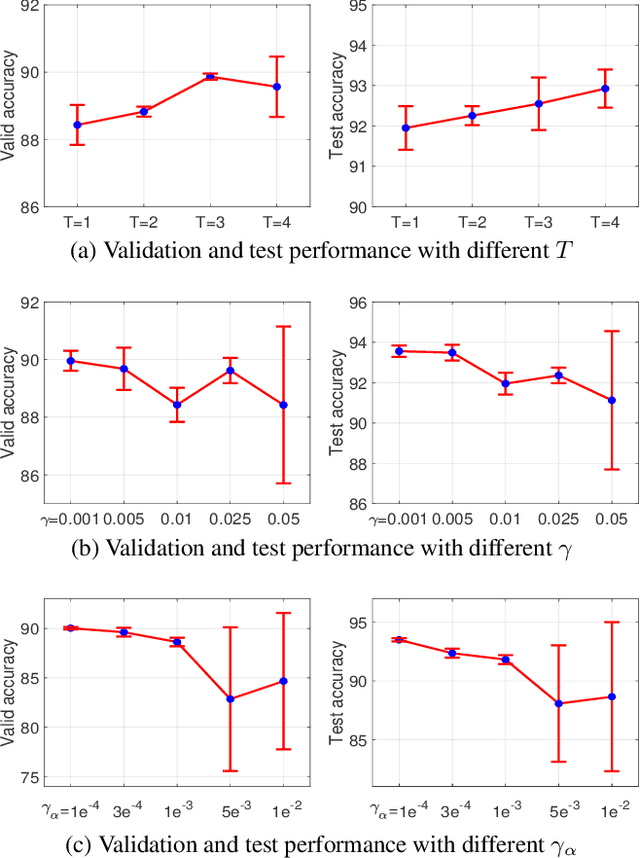
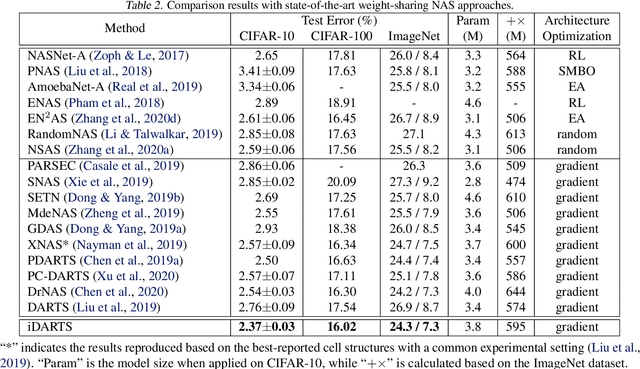
\textit{Differentiable ARchiTecture Search} (DARTS) has recently become the mainstream of neural architecture search (NAS) due to its efficiency and simplicity. With a gradient-based bi-level optimization, DARTS alternately optimizes the inner model weights and the outer architecture parameter in a weight-sharing supernet. A key challenge to the scalability and quality of the learned architectures is the need for differentiating through the inner-loop optimisation. While much has been discussed about several potentially fatal factors in DARTS, the architecture gradient, a.k.a. hypergradient, has received less attention. In this paper, we tackle the hypergradient computation in DARTS based on the implicit function theorem, making it only depends on the obtained solution to the inner-loop optimization and agnostic to the optimization path. To further reduce the computational requirements, we formulate a stochastic hypergradient approximation for differentiable NAS, and theoretically show that the architecture optimization with the proposed method, named iDARTS, is expected to converge to a stationary point. Comprehensive experiments on two NAS benchmark search spaces and the common NAS search space verify the effectiveness of our proposed method. It leads to architectures outperforming, with large margins, those learned by the baseline methods.