 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSAT: Graph Structure Attention Networks
May 27, 2025Graph Neural Networks (GNNs) have emerged as a powerful tool for processing data represented in graph structures, achieving remarkable success across a wide range of applications. However, to further improve the performance on graph classification benchmarks, structural representation of each node that encodes rich local topological information in the neighbourhood of nodes is an important type of feature that is often overlooked in the modeling. The consequence of neglecting the structural information has resulted high number of layers to connect messages from distant nodes which by itself produces other problems such as oversmoothing. In the present paper, we leverage these structural information that are modeled by anonymous random walks (ARWs) and introduce graph structure attention network (GSAT) which is a generalization of graph attention network(GAT) to integrate the original attribute and the structural representation to enforce the model to automatically find patterns for attending to different edges in the node neighbourhood to enrich graph representation. Our experiments show GSAT slightly improves SOTA on some graph classification benchmarks.
LGRPool: Hierarchical Graph Pooling Via Local-Global Regularisation
Apr 11, 2025Hierarchical graph pooling(HGP) are designed to consider the fact that conventional graph neural networks(GNN) are inherently flat and are also not multiscale. However, most HGP methods suffer not only from lack of considering global topology of the graph and focusing on the feature learning aspect, but also they do not align local and global features since graphs should inherently be analyzed in a multiscale way. LGRPool is proposed in the present paper as a HGP in the framework of expectation maximization in machine learning that aligns local and global aspects of message passing with each other using a regularizer to force the global topological information to be inline with the local message passing at different scales through the representations at different layers of HGP. Experimental results on some graph classification benchmarks show that it slightly outperforms some baselines.
Leveraging Full Dependency Parsing Graph Information For Biomedical Event Extraction
Jan 02, 2025



Many models are proposed in the literature on biomedical event extraction(BEE). Some of them use the shortest dependency path(SDP) information to represent the argument classification task. There is an issue with this representation since even missing one word from the dependency parsing graph may totally change the final prediction. To this end, the full adjacency matrix of the dependency graph is used to embed individual tokens using a graph convolutional network(GCN). An ablation study is also done to show the effect of the dependency graph on the overall performance. The results show a significant improvement when dependency graph information is used. The proposed model slightly outperforms state-of-the-art models on BEE over different datasets.
BioNCERE: Non-Contrastive Enhancement For Relation Extraction In Biomedical Texts
Oct 31, 2024



State-of-the-art models for relation extraction (RE) in the biomedical domain consider finetuning BioBERT using classification, but they may suffer from the anisotropy problem. Contrastive learning methods can reduce this anisotropy phenomena, and also help to avoid class collapse in any classification problem. In the present paper, a new training method called biological non-contrastive relation extraction (BioNCERE) is introduced for relation extraction without using any named entity labels for training to reduce annotation costs. BioNCERE uses transfer learning and non-contrastive learning to avoid full or dimensional collapse as well as bypass overfitting. It resolves RE in three stages by leveraging transfer learning two times. By freezing the weights learned in previous stages in the proposed pipeline and by leveraging non-contrastive learning in the second stage, the model predicts relations without any knowledge of named entities. Experiments have been done on SemMedDB that are almost similar to State-of-the-art performance on RE without using the information of named entities.
Transferring Neural Potentials For High Order Dependency Parsing
Jun 18, 2023

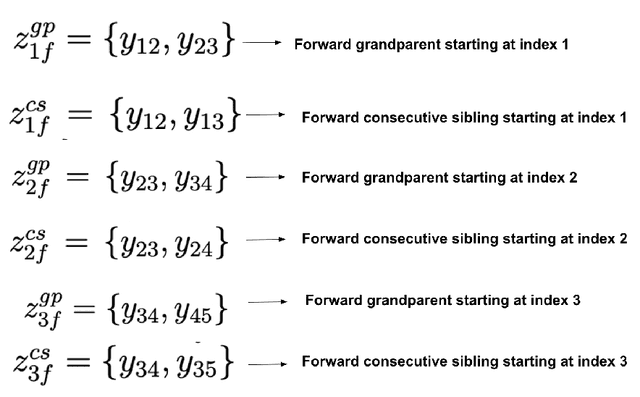

High order dependency parsing leverages high order features such as siblings or grandchildren to improve state of the art accuracy of current first order dependency parsers. The present paper uses biaffine scores to provide an estimate of the arc scores and is then propagated into a graphical model. The inference inside the graphical model is solved using dual decomposition. The present algorithm propagates biaffine neural scores to the graphical model and by leveraging dual decomposition inference, the overall circuit is trained end-to-end to transfer first order informations to the high order informations.
Semantic Tagging with LSTM-CRF
Jan 28, 2023



In the present paper, two models are presented namely LSTM-CRF and BERT-LSTM-CRF for semantic tagging of universal semantic tag dataset. The experiments show that the first model is much easier to converge while the second model that leverages BERT embedding, takes a long time to converge and needs a big dataset for semtagging to be effective.
Semantic Operator Prediction and Applications
Jan 01, 2023In the present paper, semantic parsing challenges are briefly introduced and QDMR formalism in semantic parsing is implemented using sequence to sequence model with attention but uses only part of speech(POS) as a representation of words of a sentence to make the training as simple and as fast as possible and also avoiding curse of dimensionality as well as overfitting. It is shown how semantic operator prediction could be augmented with other models like the CopyNet model or the recursive neural net model.
A Bayesian Approach To Graph Partitioning
Apr 24, 2022
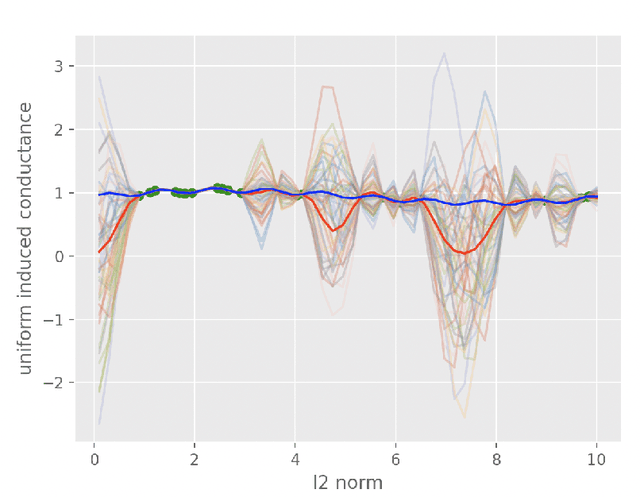

A new algorithm based on bayesian inference for learning local graph conductance based on Gaussian Process(GP) is given that uses advanced MCMC convergence ideas to create a scalable and fast algorithm for convergence to stationary distribution which is provided to learn the bahavior of conductance when traversing the indirected weighted graph. First metric embedding is used to represent the vertices of the graph. Then, uniform induced conductance is calculated for training points. Finally, in the learning step, a gaussian process is used to approximate the uniform induced conductance. MCMC is used to measure uncertainty of estimated hyper-parameters.