 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSAT: Graph Structure Attention Networks
May 27, 2025Graph Neural Networks (GNNs) have emerged as a powerful tool for processing data represented in graph structures, achieving remarkable success across a wide range of applications. However, to further improve the performance on graph classification benchmarks, structural representation of each node that encodes rich local topological information in the neighbourhood of nodes is an important type of feature that is often overlooked in the modeling. The consequence of neglecting the structural information has resulted high number of layers to connect messages from distant nodes which by itself produces other problems such as oversmoothing. In the present paper, we leverage these structural information that are modeled by anonymous random walks (ARWs) and introduce graph structure attention network (GSAT) which is a generalization of graph attention network(GAT) to integrate the original attribute and the structural representation to enforce the model to automatically find patterns for attending to different edges in the node neighbourhood to enrich graph representation. Our experiments show GSAT slightly improves SOTA on some graph classification benchmarks.
Learning Energy-Based Generative Models via Potential Flow: A Variational Principle Approach to Probability Density Homotopy Matching
Apr 22, 2025Energy-based models (EBMs) are a powerful class of probabilistic generative models due to their flexibility and interpretability. However, relationships between potential flows and explicit EBMs remain underexplored, while contrastive divergence training via implicit Markov chain Monte Carlo (MCMC) sampling is often unstable and expensive in high-dimensional settings. In this paper, we propose Variational Potential Flow Bayes (VPFB), a new energy-based generative framework that eliminates the need for implicit MCMC sampling and does not rely on auxiliary networks or cooperative training. VPFB learns an energy-parameterized potential flow by constructing a flow-driven density homotopy that is matched to the data distribution through a variational loss minimizing the Kullback-Leibler divergence between the flow-driven and marginal homotopies. This principled formulation enables robust and efficient generative modeling while preserving the interpretability of EBMs. Experimental results on image generation, interpolation, out-of-distribution detection, and compositional generation confirm the effectiveness of VPFB, showing that our method performs competitively with existing approaches in terms of sample quality and versatility across diverse generative modeling tasks.
LGRPool: Hierarchical Graph Pooling Via Local-Global Regularisation
Apr 11, 2025Hierarchical graph pooling(HGP) are designed to consider the fact that conventional graph neural networks(GNN) are inherently flat and are also not multiscale. However, most HGP methods suffer not only from lack of considering global topology of the graph and focusing on the feature learning aspect, but also they do not align local and global features since graphs should inherently be analyzed in a multiscale way. LGRPool is proposed in the present paper as a HGP in the framework of expectation maximization in machine learning that aligns local and global aspects of message passing with each other using a regularizer to force the global topological information to be inline with the local message passing at different scales through the representations at different layers of HGP. Experimental results on some graph classification benchmarks show that it slightly outperforms some baselines.
Causal-Ex: Causal Graph-based Micro and Macro Expression Spotting
Mar 12, 2025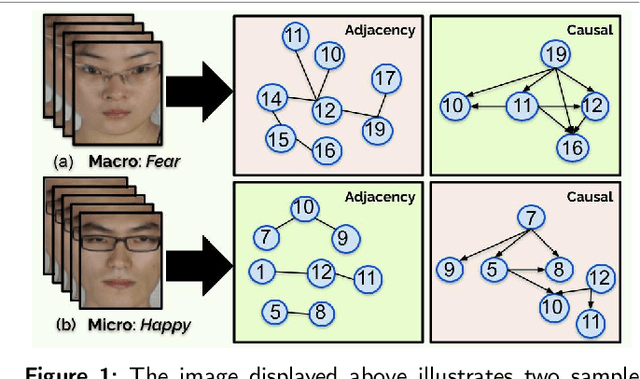



Detecting concealed emotions within apparently normal expressions is crucial for identifying potential mental health issues and facilitating timely support and intervention. The task of spotting macro and micro-expressions involves predicting the emotional timeline within a video, accomplished by identifying the onset, apex, and offset frames of the displayed emotions. Utilizing foundational facial muscle movement cues, known as facial action units, boosts the accuracy. However, an overlooked challenge from previous research lies in the inadvertent integration of biases into the training model. These biases arising from datasets can spuriously link certain action unit movements to particular emotion classes. We tackle this issue by novel replacement of action unit adjacency information with the action unit causal graphs. This approach aims to identify and eliminate undesired spurious connections, retaining only unbiased information for classification. Our model, named Causal-Ex (Causal-based Expression spotting), employs a rapid causal inference algorithm to construct a causal graph of facial action units. This enables us to select causally relevant facial action units. Our work demonstrates improvement in overall F1-scores compared to state-of-the-art approaches with 0.388 on CAS(ME)^2 and 0.3701 on SAMM-Long Video datasets.
Denoising via Repainting: an image denoising method using layer wise medical image repainting
Mar 11, 2025



Medical image denoising is essential for improving the reliability of clinical diagnosis and guiding subsequent image-based tasks. In this paper, we propose a multi-scale approach that integrates anisotropic Gaussian filtering with progressive Bezier-path redrawing. Our method constructs a scale-space pyramid to mitigate noise while preserving critical structural details. Starting at the coarsest scale, we segment partially denoised images into coherent components and redraw each using a parametric Bezier path with representative color. Through iterative refinements at finer scales, small and intricate structures are accurately reconstructed, while large homogeneous regions remain robustly smoothed. We employ both mean square error and self-intersection constraints to maintain shape coherence during path optimization. Empirical results on multiple MRI datasets demonstrate consistent improvements in PSNR and SSIM over competing methods. This coarse-to-fine framework offers a robust, data-efficient solution for cross-domain denoising, reinforcing its potential clinical utility and versatility. Future work extends this technique to three-dimensional data.
Leveraging Full Dependency Parsing Graph Information For Biomedical Event Extraction
Jan 02, 2025



Many models are proposed in the literature on biomedical event extraction(BEE). Some of them use the shortest dependency path(SDP) information to represent the argument classification task. There is an issue with this representation since even missing one word from the dependency parsing graph may totally change the final prediction. To this end, the full adjacency matrix of the dependency graph is used to embed individual tokens using a graph convolutional network(GCN). An ablation study is also done to show the effect of the dependency graph on the overall performance. The results show a significant improvement when dependency graph information is used. The proposed model slightly outperforms state-of-the-art models on BEE over different datasets.
Variational Potential Flow: A Novel Probabilistic Framework for Energy-Based Generative Modelling
Jul 21, 2024



Energy based models (EBMs) are appealing for their generality and simplicity in data likelihood modeling, but have conventionally been difficult to train due to the unstable and time-consuming implicit MCMC sampling during contrastive divergence training. In this paper, we present a novel energy-based generative framework, Variational Potential Flow (VAPO), that entirely dispenses with implicit MCMC sampling and does not rely on complementary latent models or cooperative training. The VAPO framework aims to learn a potential energy function whose gradient (flow) guides the prior samples, so that their density evolution closely follows an approximate data likelihood homotopy. An energy loss function is then formulated to minimize the Kullback-Leibler divergence between density evolution of the flow-driven prior and the data likelihood homotopy. Images can be generated after training the potential energy, by initializing the samples from Gaussian prior and solving the ODE governing the potential flow on a fixed time interval using generic ODE solvers. Experiment results show that the proposed VAPO framework is capable of generating realistic images on various image datasets. In particular, our proposed framework achieves competitive FID scores for unconditional image generation on the CIFAR-10 and CelebA datasets.
A Deep Learning Approach Using Masked Image Modeling for Reconstruction of Undersampled K-spaces
Aug 24, 2022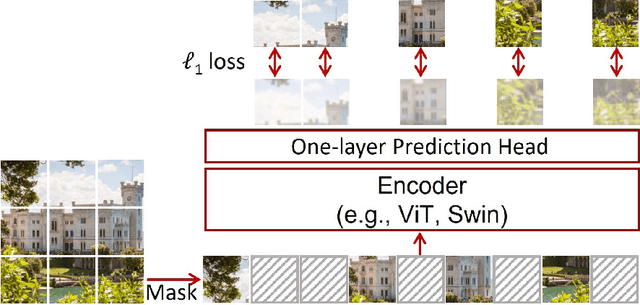
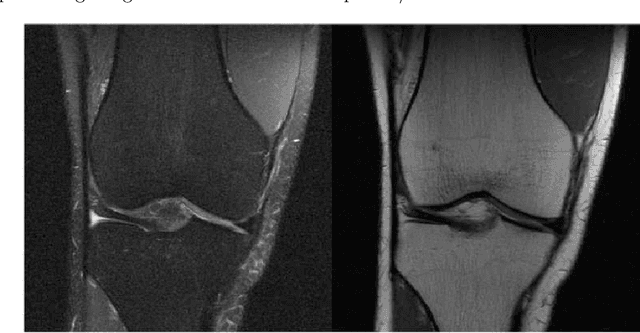
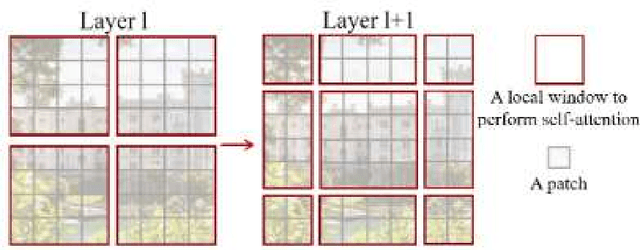
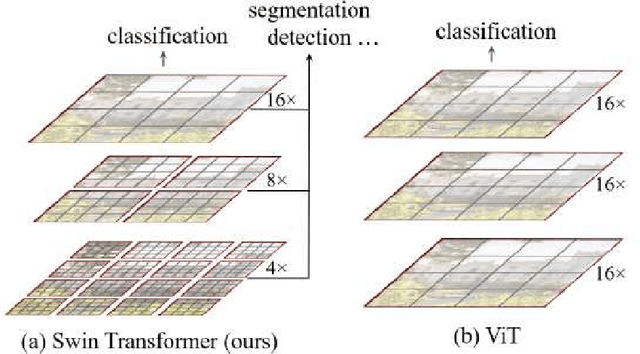
Magnetic Resonance Imaging (MRI) scans are time consuming and precarious, since the patients remain still in a confined space for extended periods of time. To reduce scanning time, some experts have experimented with undersampled k spaces, trying to use deep learning to predict the fully sampled result. These studies report that as many as 20 to 30 minutes could be saved off a scan that takes an hour or more. However, none of these studies have explored the possibility of using masked image modeling (MIM) to predict the missing parts of MRI k spaces. This study makes use of 11161 reconstructed MRI and k spaces of knee MRI images from Facebook's fastmri dataset. This tests a modified version of an existing model using baseline shifted window (Swin) and vision transformer architectures that makes use of MIM on undersampled k spaces to predict the full k space and consequently the full MRI image. Modifications were made using pytorch and numpy libraries, and were published to a github repository. After the model reconstructed the k space images, the basic Fourier transform was applied to determine the actual MRI image. Once the model reached a steady state, experimentation with hyperparameters helped to achieve pinpoint accuracy for the reconstructed images. The model was evaluated through L1 loss, gradient normalization, and structural similarity values. The model produced reconstructed images with L1 loss values averaging to <0.01 and gradient normalization values <0.1 after training finished. The reconstructed k spaces yielded structural similarity values of over 99% for both training and validation with the fully sampled k spaces, while validation loss continually decreased under 0.01. These data strongly support the idea that the algorithm works for MRI reconstruction, as they indicate the model's reconstructed image aligns extremely well with the original, fully sampled k space.
A review of deep learning methods for MRI reconstruction
Sep 17, 2021



Following the success of deep learning in a wide range of applications, neural network-based machine-learning techniques have received significant interest for accelerating magnetic resonance imaging (MRI) acquisition and reconstruction strategies. A number of ideas inspired by deep learning techniques for computer vision and image processing have been successfully applied to nonlinear image reconstruction in the spirit of compressed sensing for accelerated MRI. Given the rapidly growing nature of the field, it is imperative to consolidate and summarize the large number of deep learning methods that have been reported in the literature, to obtain a better understanding of the field in general. This article provides an overview of the recent developments in neural-network based approaches that have been proposed specifically for improving parallel imaging. A general background and introduction to parallel MRI is also given from a classical view of k-space based reconstruction methods. Image domain based techniques that introduce improved regularizers are covered along with k-space based methods which focus on better interpolation strategies using neural networks. While the field is rapidly evolving with thousands of papers published each year, in this review, we attempt to cover broad categories of methods that have shown good performance on publicly available data sets. Limitations and open problems are also discussed and recent efforts for producing open data sets and benchmarks for the community are examined.
Synthesize-It-Classifier: Learning a Generative Classifier through RecurrentSelf-analysis
Mar 26, 2021
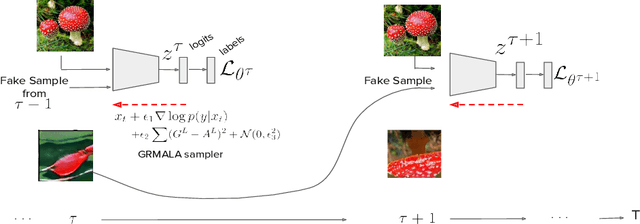


In this work, we show the generative capability of an image classifier network by synthesizing high-resolution, photo-realistic, and diverse images at scale. The overall methodology, called Synthesize-It-Classifier (STIC), does not require an explicit generator network to estimate the density of the data distribution and sample images from that, but instead uses the classifier's knowledge of the boundary to perform gradient ascent w.r.t. class logits and then synthesizes images using Gram Matrix Metropolis Adjusted Langevin Algorithm (GRMALA) by drawing on a blank canvas. During training, the classifier iteratively uses these synthesized images as fake samples and re-estimates the class boundary in a recurrent fashion to improve both the classification accuracy and quality of synthetic images. The STIC shows the mixing of the hard fake samples (i.e. those synthesized by the one hot class conditioning), and the soft fake samples (which are synthesized as a convex combination of classes, i.e. a mixup of classes) improves class interpolation. We demonstrate an Attentive-STIC network that shows an iterative drawing of synthesized images on the ImageNet dataset that has thousands of classes. In addition, we introduce the synthesis using a class conditional score classifier (Score-STIC) instead of a normal image classifier and show improved results on several real-world datasets, i.e. ImageNet, LSUN, and CIFAR 10.