 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuo Vadis: Is Trajectory Forecasting the Key Towards Long-Term Multi-Object Tracking?
Oct 14, 2022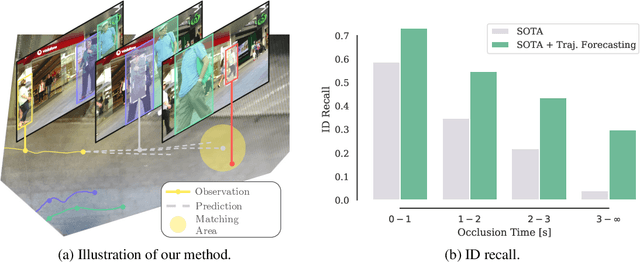
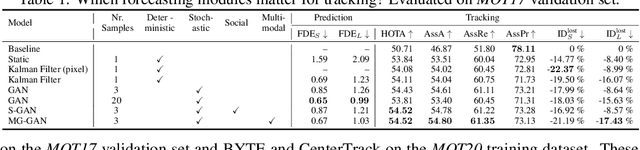
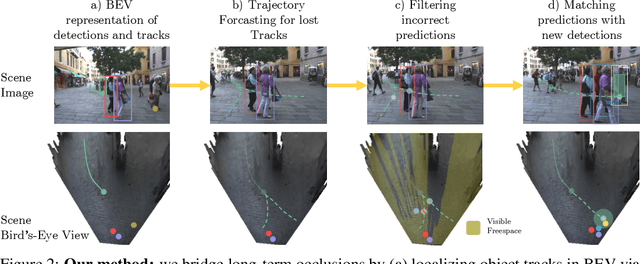
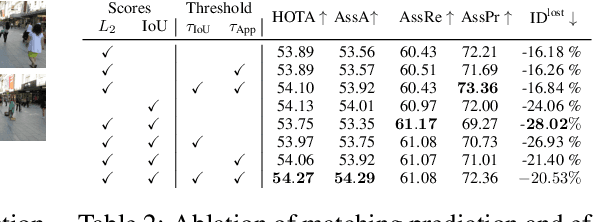
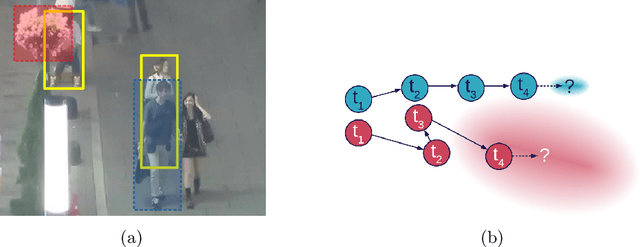
Recent developments in monocular multi-object tracking have been very successful in tracking visible objects and bridging short occlusion gaps, mainly relying on data-driven appearance models. While we have significantly advanced short-term tracking performance, bridging longer occlusion gaps remains elusive: state-of-the-art object trackers only bridge less than 10% of occlusions longer than three seconds. We suggest that the missing key is reasoning about future trajectories over a longer time horizon. Intuitively, the longer the occlusion gap, the larger the search space for possible associations. In this paper, we show that even a small yet diverse set of trajectory predictions for moving agents will significantly reduce this search space and thus improve long-term tracking robustness. Our experiments suggest that the crucial components of our approach are reasoning in a bird's-eye view space and generating a small yet diverse set of forecasts while accounting for their localization uncertainty. This way, we can advance state-of-the-art trackers on the MOTChallenge dataset and significantly improve their long-term tracking performance. This paper's source code and experimental data are available at https://github.com/dendorferpatrick/QuoVadis.
MOTCOM: The Multi-Object Tracking Dataset Complexity Metric
Jul 20, 2022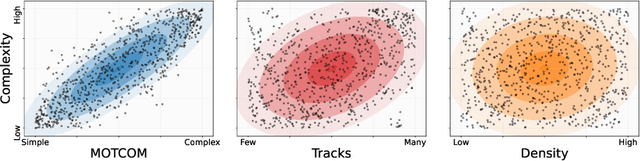
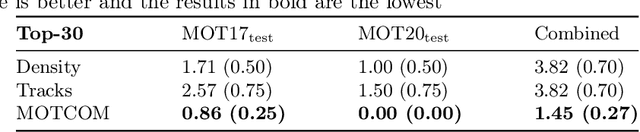

There exists no comprehensive metric for describing the complexity of Multi-Object Tracking (MOT) sequences. This lack of metrics decreases explainability, complicates comparison of datasets, and reduces the conversation on tracker performance to a matter of leader board position. As a remedy, we present the novel MOT dataset complexity metric (MOTCOM), which is a combination of three sub-metrics inspired by key problems in MOT: occlusion, erratic motion, and visual similarity. The insights of MOTCOM can open nuanced discussions on tracker performance and may lead to a wider acknowledgement of novel contributions developed for either less known datasets or those aimed at solving sub-problems. We evaluate MOTCOM on the comprehensive MOT17, MOT20, and MOTSynth datasets and show that MOTCOM is far better at describing the complexity of MOT sequences compared to the conventional density and number of tracks. Project page at https://vap.aau.dk/motcom
MG-GAN: A Multi-Generator Model Preventing Out-of-Distribution Samples in Pedestrian Trajectory Prediction
Aug 20, 2021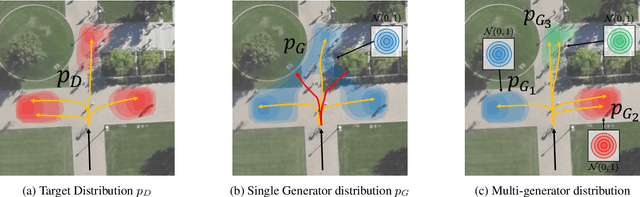
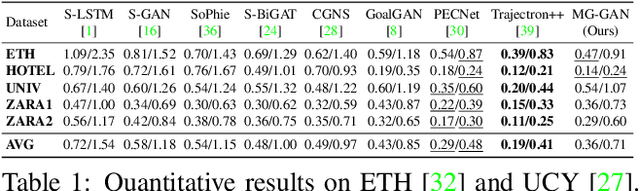
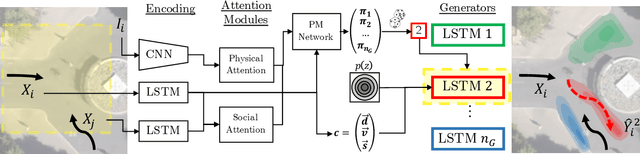
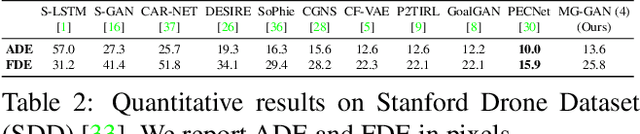
Pedestrian trajectory prediction is challenging due to its uncertain and multimodal nature. While generative adversarial networks can learn a distribution over future trajectories, they tend to predict out-of-distribution samples when the distribution of future trajectories is a mixture of multiple, possibly disconnected modes. To address this issue, we propose a multi-generator model for pedestrian trajectory prediction. Each generator specializes in learning a distribution over trajectories routing towards one of the primary modes in the scene, while a second network learns a categorical distribution over these generators, conditioned on the dynamics and scene input. This architecture allows us to effectively sample from specialized generators and to significantly reduce the out-of-distribution samples compared to single generator methods.
MOTChallenge: A Benchmark for Single-camera Multiple Target Tracking
Oct 15, 2020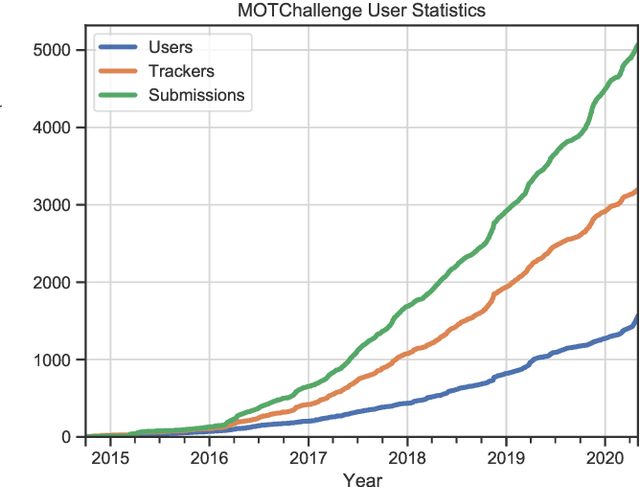
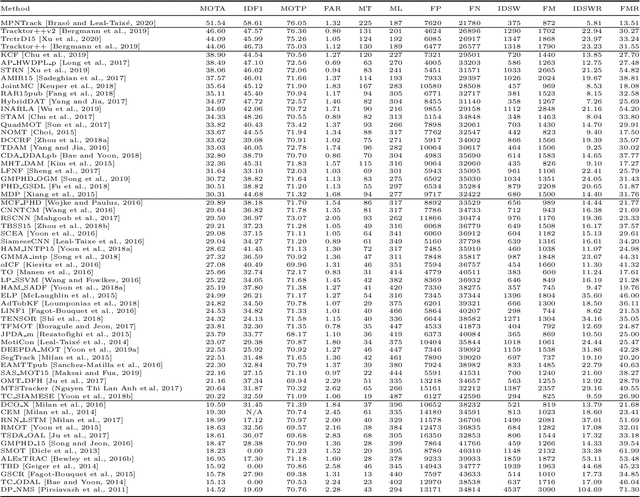

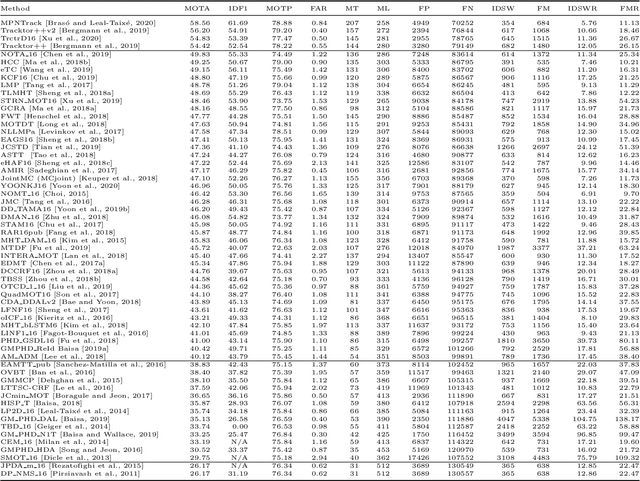
Standardized benchmarks have been crucial in pushing the performance of computer vision algorithms, especially since the advent of deep learning. Although leaderboards should not be over-claimed, they often provide the most objective measure of performance and are therefore important guides for research. We present MOTChallenge, a benchmark for single-camera Multiple Object Tracking (MOT) launched in late 2014, to collect existing and new data, and create a framework for the standardized evaluation of multiple object tracking methods. The benchmark is focused on multiple people tracking, since pedestrians are by far the most studied object in the tracking community, with applications ranging from robot navigation to self-driving cars. This paper collects the first three releases of the benchmark: (i) MOT15, along with numerous state-of-the-art results that were submitted in the last years, (ii) MOT16, which contains new challenging videos, and (iii) MOT17, that extends MOT16 sequences with more precise labels and evaluates tracking performance on three different object detectors. The second and third release not only offers a significant increase in the number of labeled boxes but also provide labels for multiple object classes beside pedestrians, as well as the level of visibility for every single object of interest. We finally provide a categorization of state-of-the-art trackers and a broad error analysis. This will help newcomers understand the related work and research trends in the MOT community, and hopefully shred some light into potential future research directions.
Goal-GAN: Multimodal Trajectory Prediction Based on Goal Position Estimation
Oct 02, 2020
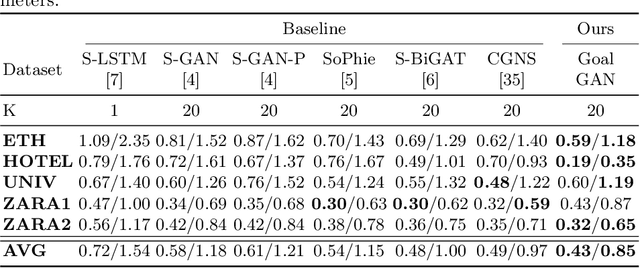
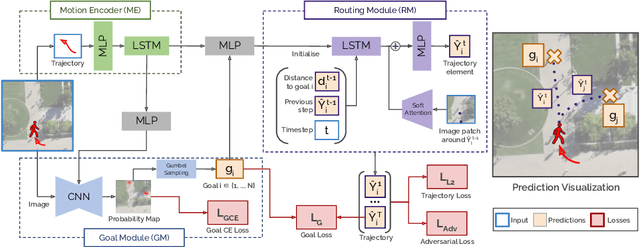
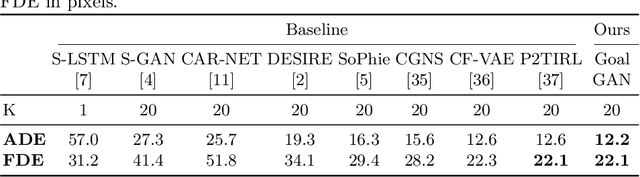
In this paper, we present Goal-GAN, an interpretable and end-to-end trainable model for human trajectory prediction. Inspired by human navigation, we model the task of trajectory prediction as an intuitive two-stage process: (i) goal estimation, which predicts the most likely target positions of the agent, followed by a (ii) routing module which estimates a set of plausible trajectories that route towards the estimated goal. We leverage information about the past trajectory and visual context of the scene to estimate a multi-modal probability distribution over the possible goal positions, which is used to sample a potential goal during the inference. The routing is governed by a recurrent neural network that reacts to physical constraints in the nearby surroundings and generates feasible paths that route towards the sampled goal. Our extensive experimental evaluation shows that our method establishes a new state-of-the-art on several benchmarks while being able to generate a realistic and diverse set of trajectories that conform to physical constraints.
HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking
Sep 29, 2020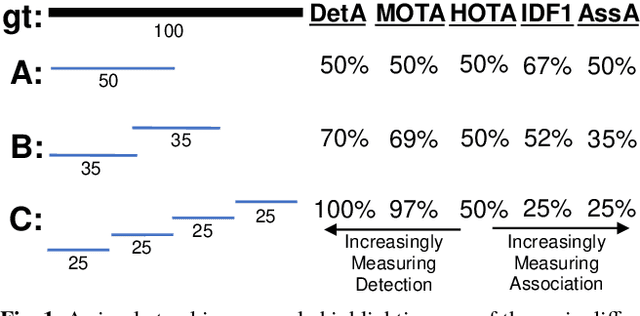
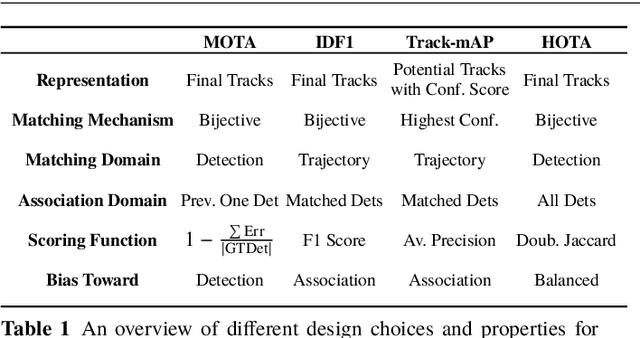
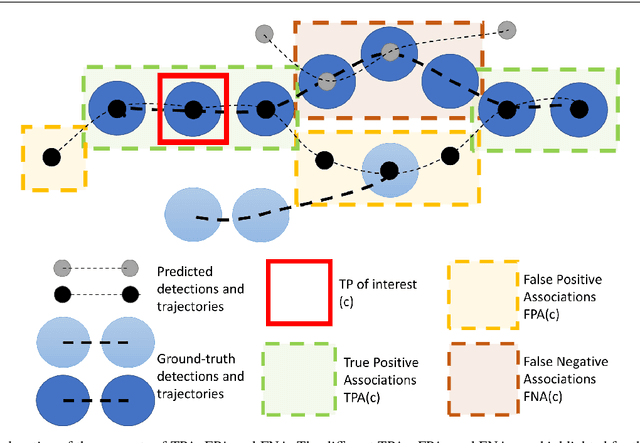
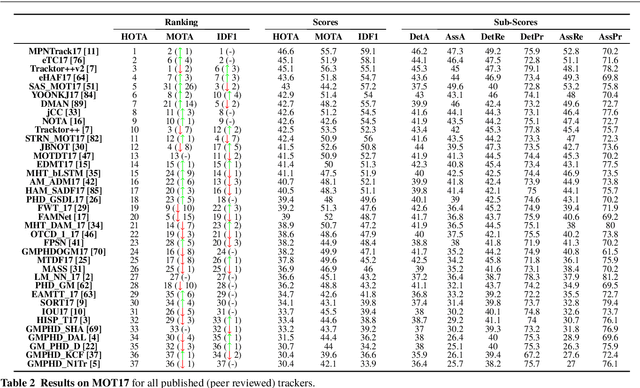
Multi-Object Tracking (MOT) has been notoriously difficult to evaluate. Previous metrics overemphasize the importance of either detection or association. To address this, we present a novel MOT evaluation metric, HOTA (Higher Order Tracking Accuracy), which explicitly balances the effect of performing accurate detection, association and localization into a single unified metric for comparing trackers. HOTA decomposes into a family of sub-metrics which are able to evaluate each of five basic error types separately, which enables clear analysis of tracking performance. We evaluate the effectiveness of HOTA on the MOTChallenge benchmark, and show that it is able to capture important aspects of MOT performance not previously taken into account by established metrics. Furthermore, we show HOTA scores better align with human visual evaluation of tracking performance.
MOT20: A benchmark for multi object tracking in crowded scenes
Mar 19, 2020
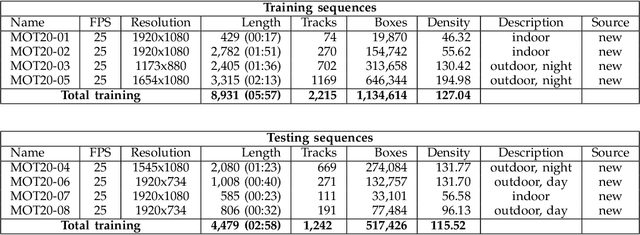

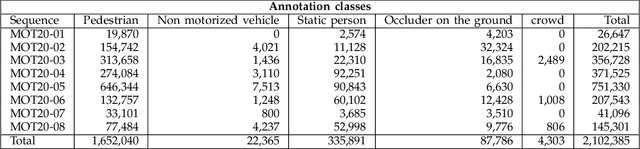
Standardized benchmarks are crucial for the majority of computer vision applications. Although leaderboards and ranking tables should not be over-claimed, benchmarks often provide the most objective measure of performance and are therefore important guides for research. The benchmark for Multiple Object Tracking, MOTChallenge, was launched with the goal to establish a standardized evaluation of multiple object tracking methods. The challenge focuses on multiple people tracking, since pedestrians are well studied in the tracking community, and precise tracking and detection has high practical relevance. Since the first release, MOT15, MOT16, and MOT17 have tremendously contributed to the community by introducing a clean dataset and precise framework to benchmark multi-object trackers. In this paper, we present our MOT20benchmark, consisting of 8 new sequences depicting very crowded challenging scenes. The benchmark was presented first at the 4thBMTT MOT Challenge Workshop at the Computer Vision and Pattern Recognition Conference (CVPR) 2019, and gives to chance to evaluate state-of-the-art methods for multiple object tracking when handling extremely crowded scenarios.
CVPR19 Tracking and Detection Challenge: How crowded can it get?
Jun 10, 2019
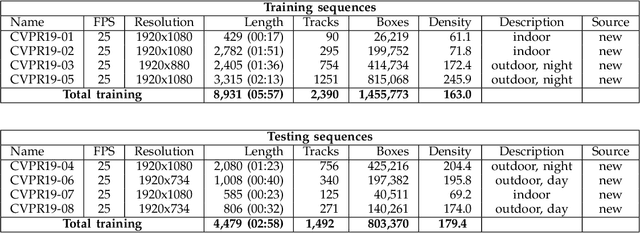

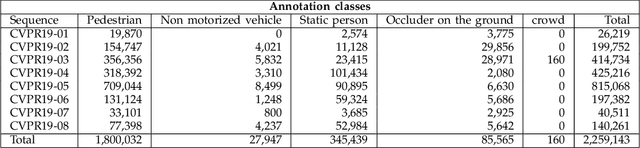
Standardized benchmarks are crucial for the majority of computer vision applications. Although leaderboards and ranking tables should not be over-claimed, benchmarks often provide the most objective measure of performance and are therefore important guides for research. The benchmark for Multiple Object Tracking, MOTChallenge, was launched with the goal to establish a standardized evaluation of multiple object tracking methods. The challenge focuses on multiple people tracking, since pedestrians are well studied in the tracking community, and precise tracking and detection has high practical relevance. Since the first release, MOT15, MOT16 and MOT17 have tremendously contributed to the community by introducing a clean dataset and precise framework to benchmark multi-object trackers. In this paper, we present our CVPR19 benchmark, consisting of 8 new sequences depicting very crowded challenging scenes. The benchmark will be presented at the 4th BMTT MOT Challenge Workshop at the Computer Vision and Pattern Recognition Conference (CVPR) 2019, and will evaluate the state-of-the-art in multiple object tracking whend handling extremely crowded scenarios.